 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-Assisted Systematization for Evaluating GenAI Systems
May 25, 2026Evaluating generative AI (GenAI) systems is challenging because many targets of evaluation are broad, contested concepts, such as "reasoning," "fairness," or "creativity." When these concepts are left underspecified, it becomes unclear what should be measured or how evaluation results should be interpreted. This problem reflects a missing step: systematization, that is, moving from a broad background concept to an explicit, structured account of the concept in measurable terms. To help address the fact that systematization is cognitively demanding and resource-intensive, we investigate whether AI assistance can support this process. To enable AI-assisted systematization and assess its quality, we introduce a structured representation of a systematized concept, a concept spec, and a validation worksheet. We then develop two AI-assisted systematizers: a direct, zero-shot approach and a multi-agent approach that more closely mirrors manual systematization approaches from existing literature. We use these systematizers to produce concept specs for two concepts -- hate-based rhetoric and digital empathy -- and evaluate resulting concept specs on content validity and information recoverability.
Understanding Frechet Speech Distance for Synthetic Speech Quality Evaluation
Jan 29, 2026Objective evaluation of synthetic speech quality remains a critical challenge. Human listening tests are the gold standard, but costly and impractical at scale. Fréchet Distance has emerged as a promising alternative, yet its reliability depends heavily on the choice of embeddings and experimental settings. In this work, we comprehensively evaluate Fréchet Speech Distance (FSD) and its variant Speech Maximum Mean Discrepancy (SMMD) under varied embeddings and conditions. We further incorporate human listening evaluations alongside TTS intelligibility and synthetic-trained ASR WER to validate the perceptual relevance of these metrics. Our findings show that WavLM Base+ features yield the most stable alignment with human ratings. While FSD and SMMD cannot fully replace subjective evaluation, we show that they can serve as complementary, cost-efficient, and reproducible measures, particularly useful when large-scale or direct listening assessments are infeasible. Code is available at https://github.com/kaen2891/FrechetSpeechDistance.
MiGrATe: Mixed-Policy GRPO for Adaptation at Test-Time
Aug 12, 2025



Large language models (LLMs) are increasingly being applied to black-box optimization tasks, from program synthesis to molecule design. Prior work typically leverages in-context learning to iteratively guide the model towards better solutions. Such methods, however, often struggle to balance exploration of new solution spaces with exploitation of high-reward ones. Recently, test-time training (TTT) with synthetic data has shown promise in improving solution quality. However, the need for hand-crafted training data tailored to each task limits feasibility and scalability across domains. To address this problem, we introduce MiGrATe-a method for online TTT that uses GRPO as a search algorithm to adapt LLMs at inference without requiring external training data. MiGrATe operates via a mixed-policy group construction procedure that combines on-policy sampling with two off-policy data selection techniques: greedy sampling, which selects top-performing past completions, and neighborhood sampling (NS), which generates completions structurally similar to high-reward ones. Together, these components bias the policy gradient towards exploitation of promising regions in solution space, while preserving exploration through on-policy sampling. We evaluate MiGrATe on three challenging domains-word search, molecule optimization, and hypothesis+program induction on the Abstraction and Reasoning Corpus (ARC)-and find that it consistently outperforms both inference-only and TTT baselines, demonstrating the potential of online TTT as a solution for complex search tasks without external supervision.
Fluent but Culturally Distant: Can Regional Training Teach Cultural Understanding?
May 25, 2025Large language models (LLMs) are used around the world but exhibit Western cultural tendencies. To address this cultural misalignment, many countries have begun developing "regional" LLMs tailored to local communities. Yet it remains unclear whether these models merely speak the language of their users or also reflect their cultural values and practices. Using India as a case study, we evaluate five Indic and five global LLMs along two key dimensions: values (via the Inglehart-Welzel map and GlobalOpinionQA) and practices (via CulturalBench and NormAd). Across all four tasks, we find that Indic models do not align more closely with Indian cultural norms than global models. In fact, an average American person is a better proxy for Indian cultural values than any Indic model. Even prompting strategies fail to meaningfully improve alignment. Ablations show that regional fine-tuning does not enhance cultural competence and may in fact hurt it by impeding recall of existing knowledge. We trace this failure to the scarcity of high-quality, untranslated, and culturally grounded pretraining and fine-tuning data. Our study positions cultural evaluation as a first-class requirement alongside multilingual benchmarks and offers a reusable methodology for developers. We call for deeper investments in culturally representative data to build and evaluate truly sovereign LLMs.
Steering AI-Driven Personalization of Scientific Text for General Audiences
Nov 15, 2024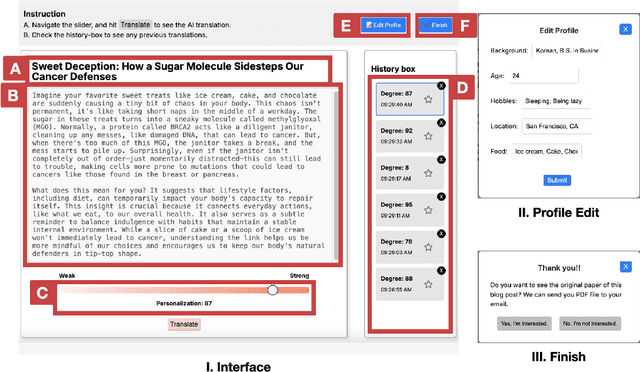

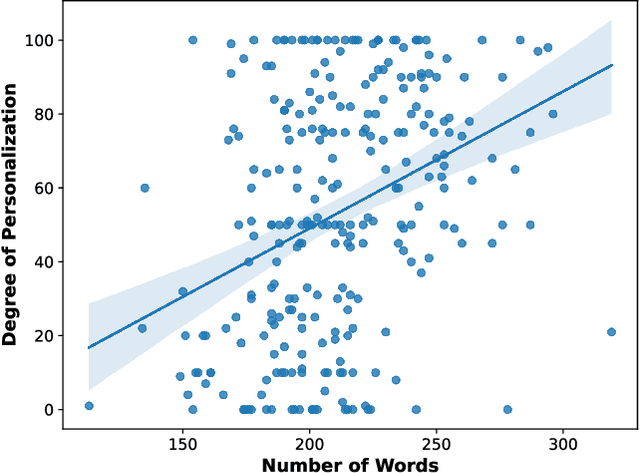
Digital media platforms (e.g., social media, science blogs) offer opportunities to communicate scientific content to general audiences at scale. However, these audiences vary in their scientific expertise, literacy levels, and personal backgrounds, making effective science communication challenging. To address this challenge, we designed TranSlider, an AI-powered tool that generates personalized translations of scientific text based on individual user profiles (e.g., hobbies, location, and education). Our tool features an interactive slider that allows users to steer the degree of personalization from 0 (weakly relatable) to 100 (strongly relatable), leveraging LLMs to generate the translations with given degrees. Through an exploratory study with 15 participants, we investigated both the utility of these AI-personalized translations and how interactive reading features influenced users' understanding and reading experiences. We found that participants who preferred higher degrees of personalization appreciated the relatable and contextual translations, while those who preferred lower degrees valued concise translations with subtle contextualization. Furthermore, participants reported the compounding effect of multiple translations on their understanding of scientific content. Given these findings, we discuss several implications of AI-personalized translation tools in facilitating communication in collaborative contexts.
Sylber: Syllabic Embedding Representation of Speech from Raw Audio
Oct 09, 2024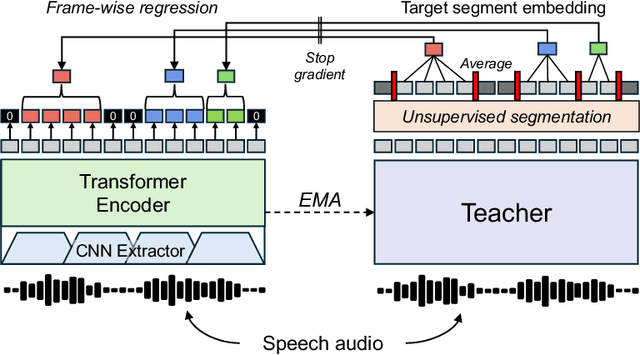
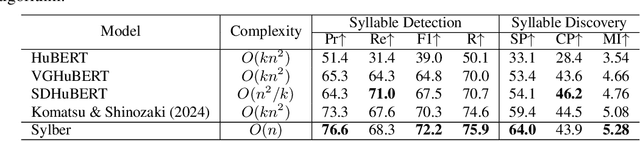
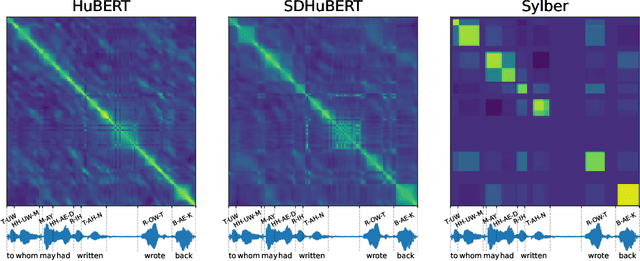
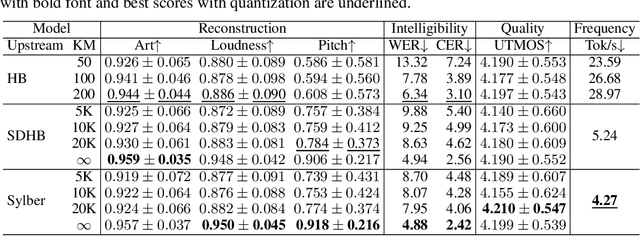
Syllables are compositional units of spoken language that play a crucial role in human speech perception and production. However, current neural speech representations lack structure, resulting in dense token sequences that are costly to process. To bridge this gap, we propose a new model, Sylber, that produces speech representations with clean and robust syllabic structure. Specifically, we propose a self-supervised model that regresses features on syllabic segments distilled from a teacher model which is an exponential moving average of the model in training. This results in a highly structured representation of speech features, offering three key benefits: 1) a fast, linear-time syllable segmentation algorithm, 2) efficient syllabic tokenization with an average of 4.27 tokens per second, and 3) syllabic units better suited for lexical and syntactic understanding. We also train token-to-speech generative models with our syllabic units and show that fully intelligible speech can be reconstructed from these tokens. Lastly, we observe that categorical perception, a linguistic phenomenon of speech perception, emerges naturally in our model, making the embedding space more categorical and sparse than previous self-supervised learning approaches. Together, we present a novel self-supervised approach for representing speech as syllables, with significant potential for efficient speech tokenization and spoken language modeling.
AI Suggestions Homogenize Writing Toward Western Styles and Diminish Cultural Nuances
Sep 17, 2024



Large language models (LLMs) are being increasingly integrated into everyday products and services, such as coding tools and writing assistants. As these embedded AI applications are deployed globally, there is a growing concern that the AI models underlying these applications prioritize Western values. This paper investigates what happens when a Western-centric AI model provides writing suggestions to users from a different cultural background. We conducted a cross-cultural controlled experiment with 118 participants from India and the United States who completed culturally grounded writing tasks with and without AI suggestions. Our analysis reveals that AI provided greater efficiency gains for Americans compared to Indians. Moreover, AI suggestions led Indian participants to adopt Western writing styles, altering not just what is written but also how it is written. These findings show that Western-centric AI models homogenize writing toward Western norms, diminishing nuances that differentiate cultural expression.
DiscoveryBench: Towards Data-Driven Discovery with Large Language Models
Jul 01, 2024



Can the rapid advances in code generation, function calling, and data analysis using large language models (LLMs) help automate the search and verification of hypotheses purely from a set of provided datasets? To evaluate this question, we present DiscoveryBench, the first comprehensive benchmark that formalizes the multi-step process of data-driven discovery. The benchmark is designed to systematically assess current model capabilities in discovery tasks and provide a useful resource for improving them. Our benchmark contains 264 tasks collected across 6 diverse domains, such as sociology and engineering, by manually deriving discovery workflows from published papers to approximate the real-world challenges faced by researchers, where each task is defined by a dataset, its metadata, and a discovery goal in natural language. We additionally provide 903 synthetic tasks to conduct controlled evaluations across task complexity. Furthermore, our structured formalism of data-driven discovery enables a facet-based evaluation that provides useful insights into different failure modes. We evaluate several popular LLM-based reasoning frameworks using both open and closed LLMs as baselines on DiscoveryBench and find that even the best system scores only 25%. Our benchmark, thus, illustrates the challenges in autonomous data-driven discovery and serves as a valuable resource for the community to make progress.
Articulatory Encodec: Vocal Tract Kinematics as a Codec for Speech
Jun 18, 2024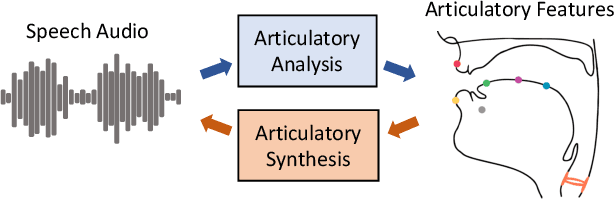
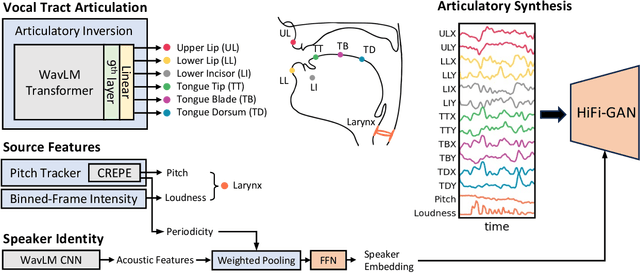

Vocal tract articulation is a natural, grounded control space of speech production. The spatiotemporal coordination of articulators combined with the vocal source shapes intelligible speech sounds to enable effective spoken communication. Based on this physiological grounding of speech, we propose a new framework of neural encoding-decoding of speech -- articulatory encodec. The articulatory encodec comprises an articulatory analysis model that infers articulatory features from speech audio, and an articulatory synthesis model that synthesizes speech audio from articulatory features. The articulatory features are kinematic traces of vocal tract articulators and source features, which are intuitively interpretable and controllable, being the actual physical interface of speech production. An additional speaker identity encoder is jointly trained with the articulatory synthesizer to inform the voice texture of individual speakers. By training on large-scale speech data, we achieve a fully intelligible, high-quality articulatory synthesizer that generalizes to unseen speakers. Furthermore, the speaker embedding is effectively disentangled from articulations, which enables accent-perserving zero-shot voice conversion. To the best of our knowledge, this is the first demonstration of universal, high-performance articulatory inference and synthesis, suggesting the proposed framework as a powerful coding system of speech.
Data-driven Discovery with Large Generative Models
Feb 21, 2024With the accumulation of data at an unprecedented rate, its potential to fuel scientific discovery is growing exponentially. This position paper urges the Machine Learning (ML) community to exploit the capabilities of large generative models (LGMs) to develop automated systems for end-to-end data-driven discovery -- a paradigm encompassing the search and verification of hypotheses purely from a set of provided datasets, without the need for additional data collection or physical experiments. We first outline several desiderata for an ideal data-driven discovery system. Then, through DATAVOYAGER, a proof-of-concept utilizing GPT-4, we demonstrate how LGMs fulfill several of these desiderata -- a feat previously unattainable -- while also highlighting important limitations in the current system that open up opportunities for novel ML research. We contend that achieving accurate, reliable, and robust end-to-end discovery systems solely through the current capabilities of LGMs is challenging. We instead advocate for fail-proof tool integration, along with active user moderation through feedback mechanisms, to foster data-driven scientific discoveries with efficiency and reproducibility.