 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyleStream: Real-Time Zero-Shot Voice Style Conversion
Feb 23, 2026Voice style conversion aims to transform an input utterance to match a target speaker's timbre, accent, and emotion, with a central challenge being the disentanglement of linguistic content from style. While prior work has explored this problem, conversion quality remains limited, and real-time voice style conversion has not been addressed. We propose StyleStream, the first streamable zero-shot voice style conversion system that achieves state-of-the-art performance. StyleStream consists of two components: a Destylizer, which removes style attributes while preserving linguistic content, and a Stylizer, a diffusion transformer (DiT) that reintroduces target style conditioned on reference speech. Robust content-style disentanglement is enforced through text supervision and a highly constrained information bottleneck. This design enables a fully non-autoregressive architecture, achieving real-time voice style conversion with an end-to-end latency of 1 second. Samples and real-time demo: https://berkeley-speech-group.github.io/StyleStream/.
Agentic Test-Time Scaling for WebAgents
Feb 12, 2026Test-time scaling has become a standard way to improve performance and boost reliability of neural network models. However, its behavior on agentic, multi-step tasks remains less well-understood: small per-step errors can compound over long horizons; and we find that naive policies that uniformly increase sampling show diminishing returns. In this work, we present CATTS, a simple technique for dynamically allocating compute for multi-step agents. We first conduct an empirical study of inference-time scaling for web agents. We find that uniformly increasing per-step compute quickly saturates in long-horizon environments. We then investigate stronger aggregation strategies, including an LLM-based Arbiter that can outperform naive voting, but that can overrule high-consensus decisions. We show that uncertainty statistics derived from the agent's own vote distribution (entropy and top-1/top-2 margin) correlate with downstream success and provide a practical signal for dynamic compute allocation. Based on these findings, we introduce Confidence-Aware Test-Time Scaling (CATTS), which uses vote-derived uncertainty to allocate compute only when decisions are genuinely contentious. CATTS improves performance on WebArena-Lite and GoBrowse by up to 9.1% over React while using up to 2.3x fewer tokens than uniform scaling, providing both efficiency gains and an interpretable decision rule.
Patient foundation model for risk stratification in low-risk overweight patients
Feb 09, 2026Accurate risk stratification in patients with overweight or obesity is critical for guiding preventive care and allocating high-cost therapies such as GLP-1 receptor agonists. We present PatientTPP, a neural temporal point process (TPP) model trained on over 500,000 real-world clinical trajectories to learn patient representations from sequences of diagnoses, labs, and medications. We extend existing TPP modeling approaches to include static and numeric features and incorporate clinical knowledge for event encoding. PatientTPP representations support downstream prediction tasks, including classification of obesity-associated outcomes in low-risk individuals, even for events not explicitly modeled during training. In health economic evaluation, PatientTPP outperformed body mass index in stratifying patients by future cardiovascular-related healthcare costs, identifying higher-risk patients more efficiently. By modeling both the type and timing of clinical events, PatientTPP offers an interpretable, general-purpose foundation for patient risk modeling with direct applications to obesity-related care and cost targeting.
Sylber 2.0: A Universal Syllable Embedding
Jan 29, 2026Scaling spoken language modeling requires speech tokens that are both efficient and universal. Recent work has proposed syllables as promising speech tokens at low temporal resolution, but existing models are constrained to English and fail to capture sufficient acoustic detail. To address this gap, we present Sylber 2.0, a self-supervised framework for coding speech at the syllable level that enables efficient temporal compression and high-fidelity reconstruction. Sylber 2.0 achieves a very low token frequency around 5 Hz, while retaining both linguistic and acoustic detail across multiple languages and expressive styles. Experiments show that it performs on par with previous models operating on high-frequency baselines. Furthermore, Sylber 2.0 enables efficient TTS modeling which can generate speech with competitive intelligibility and quality with SOTA models using only 72M parameters. Moreover, the universality of Sylber 2.0 provides more effective features for low resource ASR than previous speech coding frameworks. In sum, we establish an effective syllable-level abstraction for general spoken language.
Evolutionary Strategies lead to Catastrophic Forgetting in LLMs
Jan 28, 2026One of the biggest missing capabilities in current AI systems is the ability to learn continuously after deployment. Implementing such continually learning systems have several challenges, one of which is the large memory requirement of gradient-based algorithms that are used to train state-of-the-art LLMs. Evolutionary Strategies (ES) have recently re-emerged as a gradient-free alternative to traditional learning algorithms and have shown encouraging performance on specific tasks in LLMs. In this paper, we perform a comprehensive analysis of ES and specifically evaluate its forgetting curves when training for an increasing number of update steps. We first find that ES is able to reach performance numbers close to GRPO for math and reasoning tasks with a comparable compute budget. However, and most importantly for continual learning, the performance gains in ES is accompanied by significant forgetting of prior abilities, limiting its applicability for training models online. We also explore the reason behind this behavior and show that the updates made using ES are much less sparse and have orders of magnitude larger $\ell_2$ norm compared to corresponding GRPO updates, explaining the contrasting forgetting curves between the two algorithms. With this study, we aim to highlight the issue of forgetting in gradient-free algorithms like ES and hope to inspire future work to mitigate these issues.
Scaling Spoken Language Models with Syllabic Speech Tokenization
Sep 30, 2025Spoken language models (SLMs) typically discretize speech into high-frame-rate tokens extracted from SSL speech models. As the most successful LMs are based on the Transformer architecture, processing these long token streams with self-attention is expensive, as attention scales quadratically with sequence length. A recent SSL work introduces acoustic tokenization of speech at the syllable level, which is more interpretable and potentially more scalable with significant compression in token lengths (4-5 Hz). Yet, their value for spoken language modeling is not yet fully explored. We present the first systematic study of syllabic tokenization for spoken language modeling, evaluating models on a suite of SLU benchmarks while varying training data scale. Syllabic tokens can match or surpass the previous high-frame rate tokens while significantly cutting training and inference costs, achieving more than a 2x reduction in training time and a 5x reduction in FLOPs. Our findings highlight syllable-level language modeling as a promising path to efficient long-context spoken language models.
Plan-and-Act: Improving Planning of Agents for Long-Horizon Tasks
Mar 12, 2025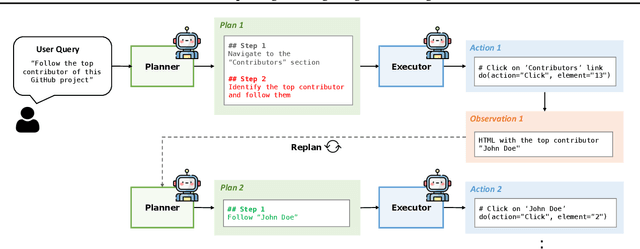
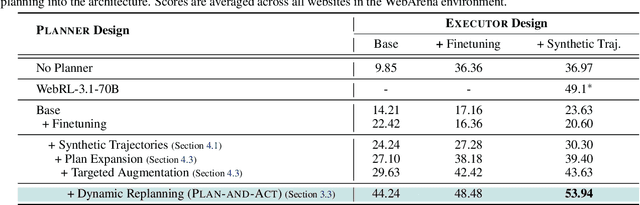
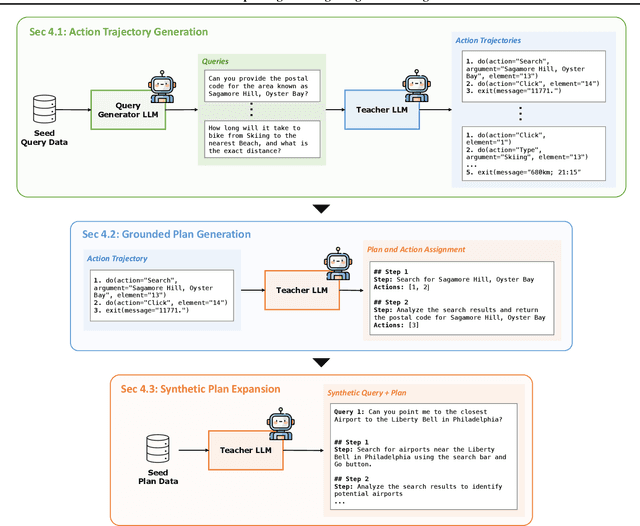
Large language models (LLMs) have shown remarkable advancements in enabling language agents to tackle simple tasks. However, applying them for complex, multi-step, long-horizon tasks remains a challenge. Recent work have found success by separating high-level planning from low-level execution, which enables the model to effectively balance high-level planning objectives and low-level execution details. However, generating accurate plans remains difficult since LLMs are not inherently trained for this task. To address this, we propose Plan-and-Act, a novel framework that incorporates explicit planning into LLM-based agents and introduces a scalable method to enhance plan generation through a novel synthetic data generation method. Plan-and-Act consists of a Planner model which generates structured, high-level plans to achieve user goals, and an Executor model that translates these plans into environment-specific actions. To train the Planner effectively, we introduce a synthetic data generation method that annotates ground-truth trajectories with feasible plans, augmented with diverse and extensive examples to enhance generalization. We evaluate Plan-and-Act using web navigation as a representative long-horizon planning environment, demonstrating a state-of the-art 54% success rate on the WebArena-Lite benchmark.
ETS: Efficient Tree Search for Inference-Time Scaling
Feb 19, 2025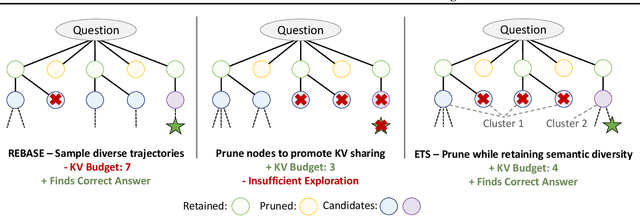
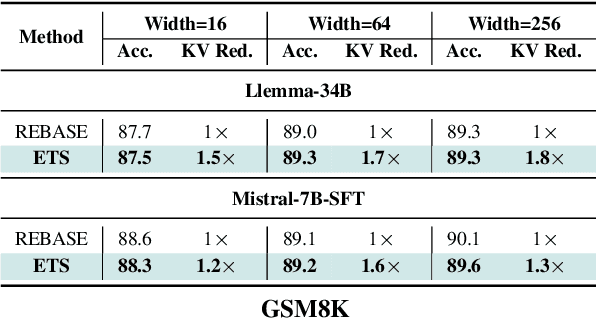
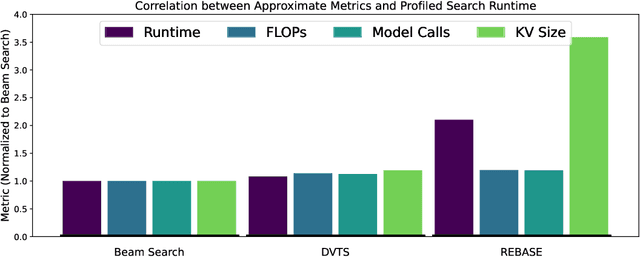
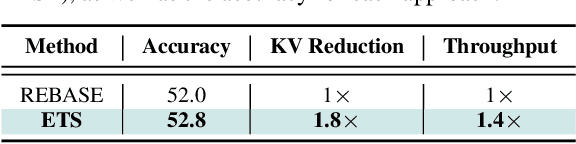
Test-time compute scaling has emerged as a new axis along which to improve model accuracy, where additional computation is used at inference time to allow the model to think longer for more challenging problems. One promising approach for test-time compute scaling is search against a process reward model, where a model generates multiple potential candidates at each step of the search, and these partial trajectories are then scored by a separate reward model in order to guide the search process. The diversity of trajectories in the tree search process affects the accuracy of the search, since increasing diversity promotes more exploration. However, this diversity comes at a cost, as divergent trajectories have less KV sharing, which means they consume more memory and slow down the search process. Previous search methods either do not perform sufficient exploration, or else explore diverse trajectories but have high latency. We address this challenge by proposing Efficient Tree Search (ETS), which promotes KV sharing by pruning redundant trajectories while maintaining necessary diverse trajectories. ETS incorporates a linear programming cost model to promote KV cache sharing by penalizing the number of nodes retained, while incorporating a semantic coverage term into the cost model to ensure that we retain trajectories which are semantically different. We demonstrate how ETS can achieve 1.8$\times$ reduction in average KV cache size during the search process, leading to 1.4$\times$ increased throughput relative to prior state-of-the-art methods, with minimal accuracy degradation and without requiring any custom kernel implementation. Code is available at: https://github.com/SqueezeAILab/ETS.
Sylber: Syllabic Embedding Representation of Speech from Raw Audio
Oct 09, 2024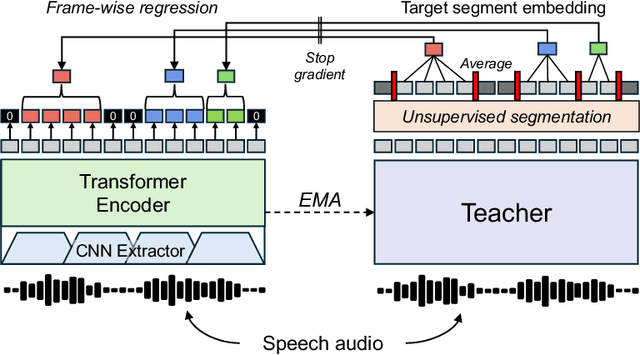
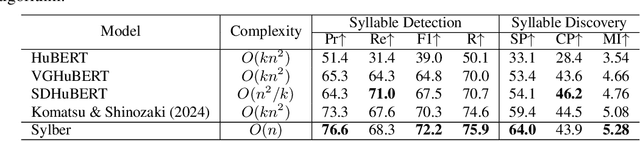
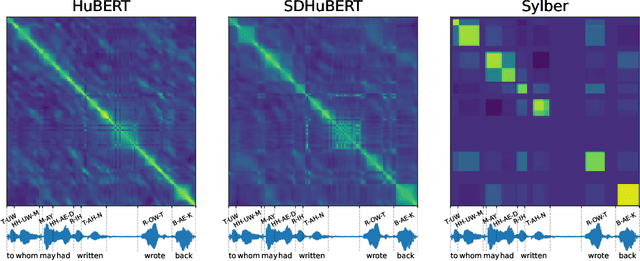
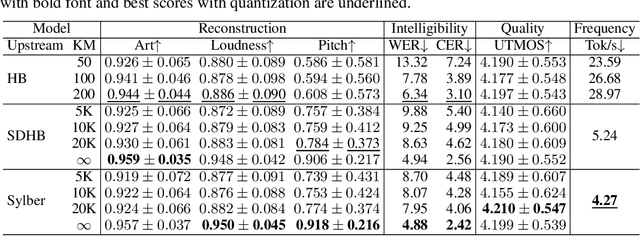
Syllables are compositional units of spoken language that play a crucial role in human speech perception and production. However, current neural speech representations lack structure, resulting in dense token sequences that are costly to process. To bridge this gap, we propose a new model, Sylber, that produces speech representations with clean and robust syllabic structure. Specifically, we propose a self-supervised model that regresses features on syllabic segments distilled from a teacher model which is an exponential moving average of the model in training. This results in a highly structured representation of speech features, offering three key benefits: 1) a fast, linear-time syllable segmentation algorithm, 2) efficient syllabic tokenization with an average of 4.27 tokens per second, and 3) syllabic units better suited for lexical and syntactic understanding. We also train token-to-speech generative models with our syllabic units and show that fully intelligible speech can be reconstructed from these tokens. Lastly, we observe that categorical perception, a linguistic phenomenon of speech perception, emerges naturally in our model, making the embedding space more categorical and sparse than previous self-supervised learning approaches. Together, we present a novel self-supervised approach for representing speech as syllables, with significant potential for efficient speech tokenization and spoken language modeling.
TinyAgent: Function Calling at the Edge
Sep 01, 2024



Recent large language models (LLMs) have enabled the development of advanced agentic systems that can integrate various tools and APIs to fulfill user queries through function calling. However, the deployment of these LLMs on the edge has not been explored since they typically require cloud-based infrastructure due to their substantial model size and computational demands. To this end, we present TinyAgent, an end-to-end framework for training and deploying task-specific small language model agents capable of function calling for driving agentic systems at the edge. We first show how to enable accurate function calling for open-source models via the LLMCompiler framework. We then systematically curate a high-quality dataset for function calling, which we use to fine-tune two small language models, TinyAgent-1.1B and 7B. For efficient inference, we introduce a novel tool retrieval method to reduce the input prompt length and utilize quantization to further accelerate the inference speed. As a driving application, we demonstrate a local Siri-like system for Apple's MacBook that can execute user commands through text or voice input. Our results show that our models can achieve, and even surpass, the function-calling capabilities of larger models like GPT-4-Turbo, while being fully deployed at the edge. We open-source our dataset, models, and installable package and provide a demo video for our MacBook assistant agent.