 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion-State Policy Optimization for Masked Diffusion Language Models
Feb 09, 2026Masked diffusion language models generate by iteratively filling masked tokens over multiple denoising steps, so learning only from a terminal reward on the final completion yields coarse credit assignment over intermediate decisions. We propose DiSPO (Diffusion-State Policy Optimization), a plug-in credit-assignment layer that directly optimizes intermediate filling decisions. At selected intermediate masked states, DiSPO branches by resampling fillings for the currently masked positions from rollout-cached logits, scores the resulting completions, and updates only the newly filled tokens -- without additional multi-step diffusion rollouts. We formalize a fixed-state objective for branched completions and derive a policy-gradient estimator that can be combined with terminal-feedback policy optimization using the same rollouts. On LLaDA-8B-Instruct, DiSPO consistently improves over the terminal-feedback diffu-GRPO baseline on math and planning benchmarks under matched rollout compute and optimizer steps. Our code will be available at https://daioba.github.io/dispo .
Emergent Analogical Reasoning in Transformers
Feb 03, 2026Analogy is a central faculty of human intelligence, enabling abstract patterns discovered in one domain to be applied to another. Despite its central role in cognition, the mechanisms by which Transformers acquire and implement analogical reasoning remain poorly understood. In this work, inspired by the notion of functors in category theory, we formalize analogical reasoning as the inference of correspondences between entities across categories. Based on this formulation, we introduce synthetic tasks that evaluate the emergence of analogical reasoning under controlled settings. We find that the emergence of analogical reasoning is highly sensitive to data characteristics, optimization choices, and model scale. Through mechanistic analysis, we show that analogical reasoning in Transformers decomposes into two key components: (1) geometric alignment of relational structure in the embedding space, and (2) the application of a functor within the Transformer. These mechanisms enable models to transfer relational structure from one category to another, realizing analogy. Finally, we quantify these effects and find that the same trends are observed in pretrained LLMs. In doing so, we move analogy from an abstract cognitive notion to a concrete, mechanistically grounded phenomenon in modern neural networks.
Topology of Reasoning: Understanding Large Reasoning Models through Reasoning Graph Properties
Jun 06, 2025Recent large-scale reasoning models have achieved state-of-the-art performance on challenging mathematical benchmarks, yet the internal mechanisms underlying their success remain poorly understood. In this work, we introduce the notion of a reasoning graph, extracted by clustering hidden-state representations at each reasoning step, and systematically analyze three key graph-theoretic properties: cyclicity, diameter, and small-world index, across multiple tasks (GSM8K, MATH500, AIME 2024). Our findings reveal that distilled reasoning models (e.g., DeepSeek-R1-Distill-Qwen-32B) exhibit significantly more recurrent cycles (about 5 per sample), substantially larger graph diameters, and pronounced small-world characteristics (about 6x) compared to their base counterparts. Notably, these structural advantages grow with task difficulty and model capacity, with cycle detection peaking at the 14B scale and exploration diameter maximized in the 32B variant, correlating positively with accuracy. Furthermore, we show that supervised fine-tuning on an improved dataset systematically expands reasoning graph diameters in tandem with performance gains, offering concrete guidelines for dataset design aimed at boosting reasoning capabilities. By bridging theoretical insights into reasoning graph structures with practical recommendations for data construction, our work advances both the interpretability and the efficacy of large reasoning models.
Beyond Induction Heads: In-Context Meta Learning Induces Multi-Phase Circuit Emergence
May 22, 2025Transformer-based language models exhibit In-Context Learning (ICL), where predictions are made adaptively based on context. While prior work links induction heads to ICL through a sudden jump in accuracy, this can only account for ICL when the answer is included within the context. However, an important property of practical ICL in large language models is the ability to meta-learn how to solve tasks from context, rather than just copying answers from context; how such an ability is obtained during training is largely unexplored. In this paper, we experimentally clarify how such meta-learning ability is acquired by analyzing the dynamics of the model's circuit during training. Specifically, we extend the copy task from previous research into an In-Context Meta Learning setting, where models must infer a task from examples to answer queries. Interestingly, in this setting, we find that there are multiple phases in the process of acquiring such abilities, and that a unique circuit emerges in each phase, contrasting with the single-phases change in induction heads. The emergence of such circuits can be related to several phenomena known in large language models, and our analysis lead to a deeper understanding of the source of the transformer's ICL ability.
Plan-and-Act: Improving Planning of Agents for Long-Horizon Tasks
Mar 12, 2025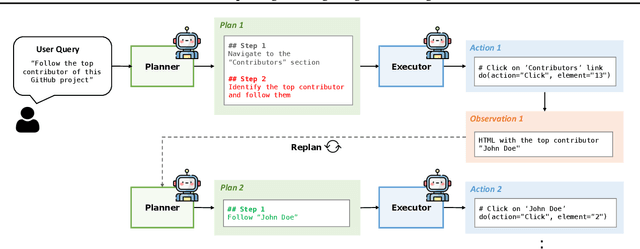
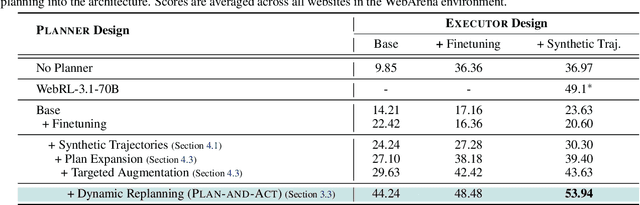
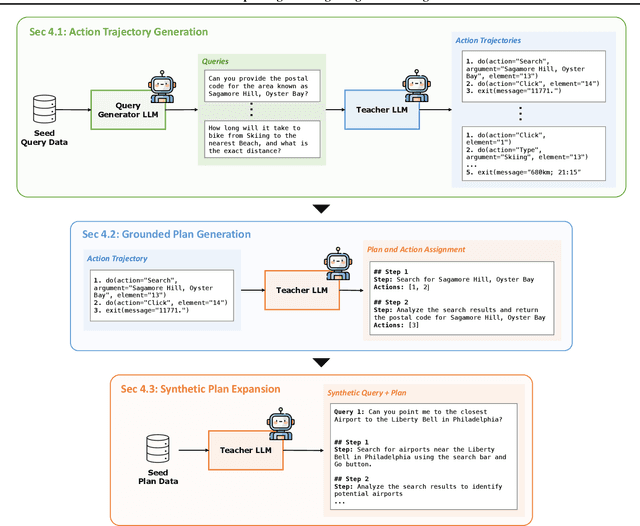
Large language models (LLMs) have shown remarkable advancements in enabling language agents to tackle simple tasks. However, applying them for complex, multi-step, long-horizon tasks remains a challenge. Recent work have found success by separating high-level planning from low-level execution, which enables the model to effectively balance high-level planning objectives and low-level execution details. However, generating accurate plans remains difficult since LLMs are not inherently trained for this task. To address this, we propose Plan-and-Act, a novel framework that incorporates explicit planning into LLM-based agents and introduces a scalable method to enhance plan generation through a novel synthetic data generation method. Plan-and-Act consists of a Planner model which generates structured, high-level plans to achieve user goals, and an Executor model that translates these plans into environment-specific actions. To train the Planner effectively, we introduce a synthetic data generation method that annotates ground-truth trajectories with feasible plans, augmented with diverse and extensive examples to enhance generalization. We evaluate Plan-and-Act using web navigation as a representative long-horizon planning environment, demonstrating a state-of the-art 54% success rate on the WebArena-Lite benchmark.
Inference-Time Text-to-Video Alignment with Diffusion Latent Beam Search
Jan 31, 2025



The remarkable progress in text-to-video diffusion models enables photorealistic generations, although the contents of the generated video often include unnatural movement or deformation, reverse playback, and motionless scenes. Recently, an alignment problem has attracted huge attention, where we steer the output of diffusion models based on some quantity on the goodness of the content. Because there is a large room for improvement of perceptual quality along the frame direction, we should address which metrics we should optimize and how we can optimize them in the video generation. In this paper, we propose diffusion latent beam search with lookahead estimator, which can select better diffusion latent to maximize a given alignment reward, at inference time. We then point out that the improvement of perceptual video quality considering the alignment to prompts requires reward calibration by weighting existing metrics. When evaluating outputs by using vision language models as a proxy of humans, many previous metrics to quantify the naturalness of video do not always correlate with evaluation and also depend on the degree of dynamic descriptions in evaluation prompts. We demonstrate that our method improves the perceptual quality based on the calibrated reward, without model parameter update, and outputs the best generation compared to greedy search and best-of-N sampling. We provide practical guidelines on which axes, among search budget, lookahead steps for reward estimate, and denoising steps, in the reverse diffusion process, we should allocate the inference-time computation.
Rethinking Evaluation of Sparse Autoencoders through the Representation of Polysemous Words
Jan 09, 2025



Sparse autoencoders (SAEs) have gained a lot of attention as a promising tool to improve the interpretability of large language models (LLMs) by mapping the complex superposition of polysemantic neurons into monosemantic features and composing a sparse dictionary of words. However, traditional performance metrics like Mean Squared Error and L0 sparsity ignore the evaluation of the semantic representational power of SAEs -- whether they can acquire interpretable monosemantic features while preserving the semantic relationship of words. For instance, it is not obvious whether a learned sparse feature could distinguish different meanings in one word. In this paper, we propose a suite of evaluations for SAEs to analyze the quality of monosemantic features by focusing on polysemous words. Our findings reveal that SAEs developed to improve the MSE-L0 Pareto frontier may confuse interpretability, which does not necessarily enhance the extraction of monosemantic features. The analysis of SAEs with polysemous words can also figure out the internal mechanism of LLMs; deeper layers and the Attention module contribute to distinguishing polysemy in a word. Our semantics focused evaluation offers new insights into the polysemy and the existing SAE objective and contributes to the development of more practical SAEs.
Improving Dynamic Object Interactions in Text-to-Video Generation with AI Feedback
Dec 03, 2024

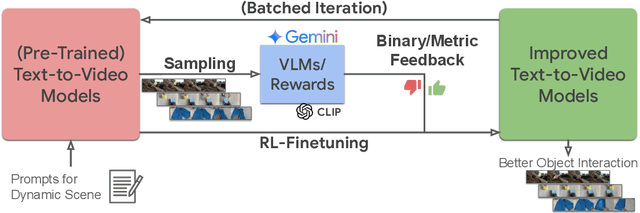

Large text-to-video models hold immense potential for a wide range of downstream applications. However, these models struggle to accurately depict dynamic object interactions, often resulting in unrealistic movements and frequent violations of real-world physics. One solution inspired by large language models is to align generated outputs with desired outcomes using external feedback. This enables the model to refine its responses autonomously, eliminating extensive manual data collection. In this work, we investigate the use of feedback to enhance the object dynamics in text-to-video models. We aim to answer a critical question: what types of feedback, paired with which specific self-improvement algorithms, can most effectively improve text-video alignment and realistic object interactions? We begin by deriving a unified probabilistic objective for offline RL finetuning of text-to-video models. This perspective highlights how design elements in existing algorithms like KL regularization and policy projection emerge as specific choices within a unified framework. We then use derived methods to optimize a set of text-video alignment metrics (e.g., CLIP scores, optical flow), but notice that they often fail to align with human perceptions of generation quality. To address this limitation, we propose leveraging vision-language models to provide more nuanced feedback specifically tailored to object dynamics in videos. Our experiments demonstrate that our method can effectively optimize a wide variety of rewards, with binary AI feedback driving the most significant improvements in video quality for dynamic interactions, as confirmed by both AI and human evaluations. Notably, we observe substantial gains when using reward signals derived from AI feedback, particularly in scenarios involving complex interactions between multiple objects and realistic depictions of objects falling.
Geometric-Averaged Preference Optimization for Soft Preference Labels
Sep 10, 2024Many algorithms for aligning LLMs with human preferences assume that human preferences are binary and deterministic. However, it is reasonable to think that they can vary with different individuals, and thus should be distributional to reflect the fine-grained relationship between the responses. In this work, we introduce the distributional soft preference labels and improve Direct Preference Optimization (DPO) with a weighted geometric average of the LLM output likelihood in the loss function. In doing so, the scale of learning loss is adjusted based on the soft labels, and the loss with equally preferred responses would be close to zero. This simple modification can be easily applied to any DPO family and helps the models escape from the over-optimization and objective mismatch prior works suffer from. In our experiments, we simulate the soft preference labels with AI feedback from LLMs and demonstrate that geometric averaging consistently improves performance on standard benchmarks for alignment research. In particular, we observe more preferable responses than binary labels and significant improvements with data where modestly-confident labels are in the majority.
Interpreting Grokked Transformers in Complex Modular Arithmetic
Feb 27, 2024


Grokking has been actively explored to reveal the mystery of delayed generalization. Identifying interpretable algorithms inside the grokked models is a suggestive hint to understanding its mechanism. In this work, beyond the simplest and well-studied modular addition, we observe the internal circuits learned through grokking in complex modular arithmetic via interpretable reverse engineering, which highlights the significant difference in their dynamics: subtraction poses a strong asymmetry on Transformer; multiplication requires cosine-biased components at all the frequencies in a Fourier domain; polynomials often result in the superposition of the patterns from elementary arithmetic, but clear patterns do not emerge in challenging cases; grokking can easily occur even in higher-degree formulas with basic symmetric and alternating expressions. We also introduce the novel progress measure for modular arithmetic; Fourier Frequency Sparsity and Fourier Coefficient Ratio, which not only indicate the late generalization but also characterize distinctive internal representations of grokked models per modular operation. Our empirical analysis emphasizes the importance of holistic evaluation among various combinations.