 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Dynamic Object Interactions in Text-to-Video Generation with AI Feedback
Paper and Code


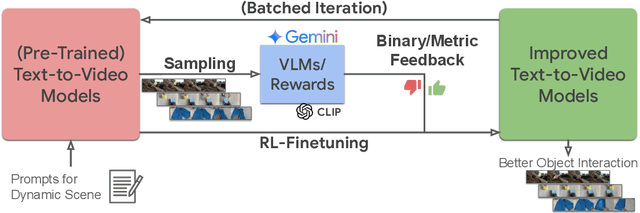

Large text-to-video models hold immense potential for a wide range of downstream applications. However, these models struggle to accurately depict dynamic object interactions, often resulting in unrealistic movements and frequent violations of real-world physics. One solution inspired by large language models is to align generated outputs with desired outcomes using external feedback. This enables the model to refine its responses autonomously, eliminating extensive manual data collection. In this work, we investigate the use of feedback to enhance the object dynamics in text-to-video models. We aim to answer a critical question: what types of feedback, paired with which specific self-improvement algorithms, can most effectively improve text-video alignment and realistic object interactions? We begin by deriving a unified probabilistic objective for offline RL finetuning of text-to-video models. This perspective highlights how design elements in existing algorithms like KL regularization and policy projection emerge as specific choices within a unified framework. We then use derived methods to optimize a set of text-video alignment metrics (e.g., CLIP scores, optical flow), but notice that they often fail to align with human perceptions of generation quality. To address this limitation, we propose leveraging vision-language models to provide more nuanced feedback specifically tailored to object dynamics in videos. Our experiments demonstrate that our method can effectively optimize a wide variety of rewards, with binary AI feedback driving the most significant improvements in video quality for dynamic interactions, as confirmed by both AI and human evaluations. Notably, we observe substantial gains when using reward signals derived from AI feedback, particularly in scenarios involving complex interactions between multiple objects and realistic depictions of objects falling.