 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReverbMiipher: Generative Speech Restoration meets Reverberation Characteristics Controllability
May 08, 2025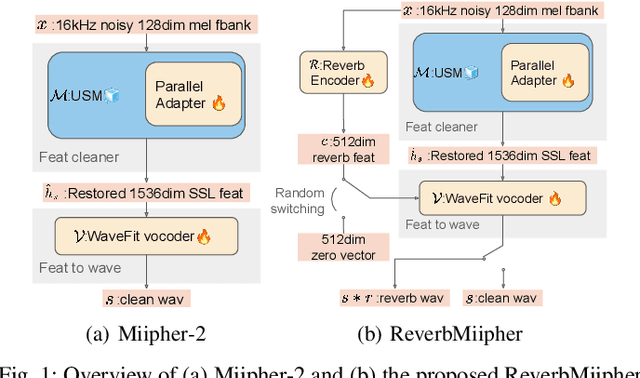
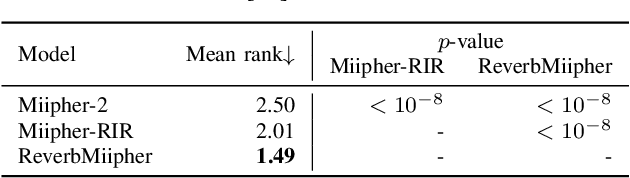
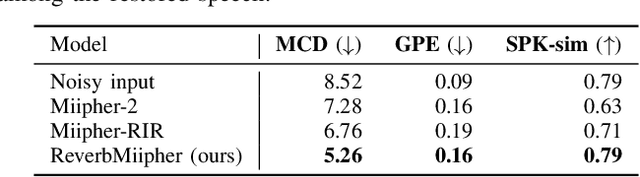
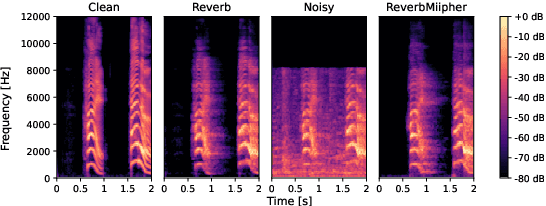
Reverberation encodes spatial information regarding the acoustic source environment, yet traditional Speech Restoration (SR) usually completely removes reverberation. We propose ReverbMiipher, an SR model extending parametric resynthesis framework, designed to denoise speech while preserving and enabling control over reverberation. ReverbMiipher incorporates a dedicated ReverbEncoder to extract a reverb feature vector from noisy input. This feature conditions a vocoder to reconstruct the speech signal, removing noise while retaining the original reverberation characteristics. A stochastic zero-vector replacement strategy during training ensures the feature specifically encodes reverberation, disentangling it from other speech attributes. This learned representation facilitates reverberation control via techniques such as interpolation between features, replacement with features from other utterances, or sampling from a latent space. Objective and subjective evaluations confirm ReverbMiipher effectively preserves reverberation, removes other artifacts, and outperforms the conventional two-stage SR and convolving simulated room impulse response approach. We further demonstrate its ability to generate novel reverberation effects through feature manipulation.
Miipher-2: A Universal Speech Restoration Model for Million-Hour Scale Data Restoration
May 07, 2025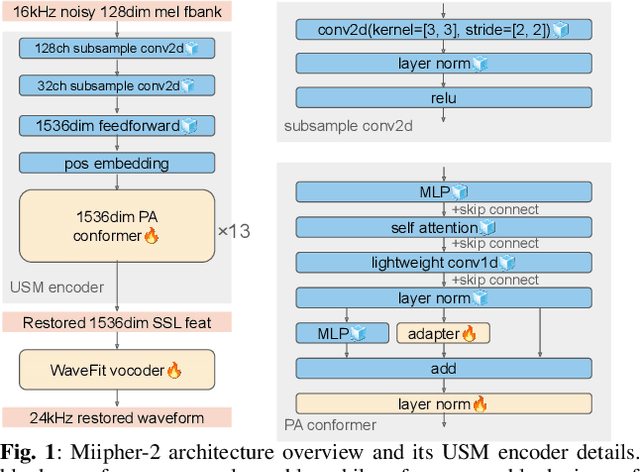
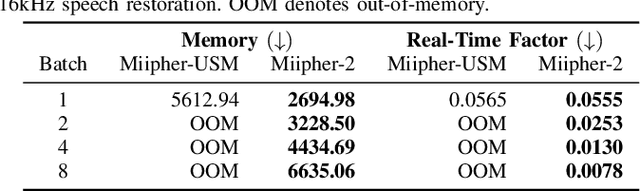
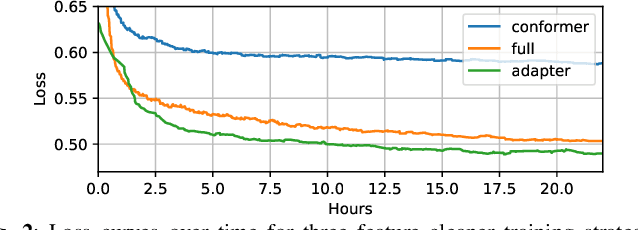
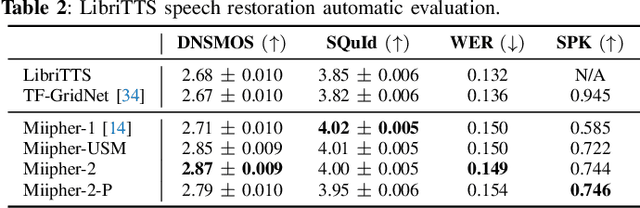
Training data cleaning is a new application for generative model-based speech restoration (SR). This paper introduces Miipher-2, an SR model designed for million-hour scale data, for training data cleaning for large-scale generative models like large language models. Key challenges addressed include generalization to unseen languages, operation without explicit conditioning (e.g., text, speaker ID), and computational efficiency. Miipher-2 utilizes a frozen, pre-trained Universal Speech Model (USM), supporting over 300 languages, as a robust, conditioning-free feature extractor. To optimize efficiency and minimize memory, Miipher-2 incorporates parallel adapters for predicting clean USM features from noisy inputs and employs the WaneFit neural vocoder for waveform synthesis. These components were trained on 3,000 hours of multi-lingual, studio-quality recordings with augmented degradations, while USM parameters remained fixed. Experimental results demonstrate Miipher-2's superior or comparable performance to conventional SR models in word-error-rate, speaker similarity, and both objective and subjective sound quality scores across all tested languages. Miipher-2 operates efficiently on consumer-grade accelerators, achieving a real-time factor of 0.0078, enabling the processing of a million-hour speech dataset in approximately three days using only 100 such accelerators.
Improving Dynamic Object Interactions in Text-to-Video Generation with AI Feedback
Dec 03, 2024

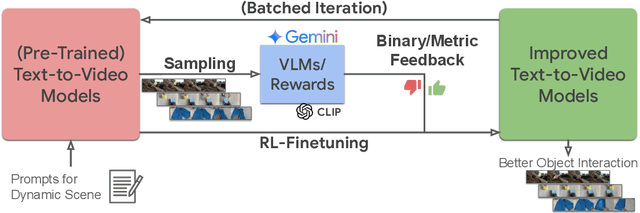

Large text-to-video models hold immense potential for a wide range of downstream applications. However, these models struggle to accurately depict dynamic object interactions, often resulting in unrealistic movements and frequent violations of real-world physics. One solution inspired by large language models is to align generated outputs with desired outcomes using external feedback. This enables the model to refine its responses autonomously, eliminating extensive manual data collection. In this work, we investigate the use of feedback to enhance the object dynamics in text-to-video models. We aim to answer a critical question: what types of feedback, paired with which specific self-improvement algorithms, can most effectively improve text-video alignment and realistic object interactions? We begin by deriving a unified probabilistic objective for offline RL finetuning of text-to-video models. This perspective highlights how design elements in existing algorithms like KL regularization and policy projection emerge as specific choices within a unified framework. We then use derived methods to optimize a set of text-video alignment metrics (e.g., CLIP scores, optical flow), but notice that they often fail to align with human perceptions of generation quality. To address this limitation, we propose leveraging vision-language models to provide more nuanced feedback specifically tailored to object dynamics in videos. Our experiments demonstrate that our method can effectively optimize a wide variety of rewards, with binary AI feedback driving the most significant improvements in video quality for dynamic interactions, as confirmed by both AI and human evaluations. Notably, we observe substantial gains when using reward signals derived from AI feedback, particularly in scenarios involving complex interactions between multiple objects and realistic depictions of objects falling.
Geometric-Averaged Preference Optimization for Soft Preference Labels
Sep 10, 2024Many algorithms for aligning LLMs with human preferences assume that human preferences are binary and deterministic. However, it is reasonable to think that they can vary with different individuals, and thus should be distributional to reflect the fine-grained relationship between the responses. In this work, we introduce the distributional soft preference labels and improve Direct Preference Optimization (DPO) with a weighted geometric average of the LLM output likelihood in the loss function. In doing so, the scale of learning loss is adjusted based on the soft labels, and the loss with equally preferred responses would be close to zero. This simple modification can be easily applied to any DPO family and helps the models escape from the over-optimization and objective mismatch prior works suffer from. In our experiments, we simulate the soft preference labels with AI feedback from LLMs and demonstrate that geometric averaging consistently improves performance on standard benchmarks for alignment research. In particular, we observe more preferable responses than binary labels and significant improvements with data where modestly-confident labels are in the majority.
FLEURS-R: A Restored Multilingual Speech Corpus for Generation Tasks
Aug 12, 2024
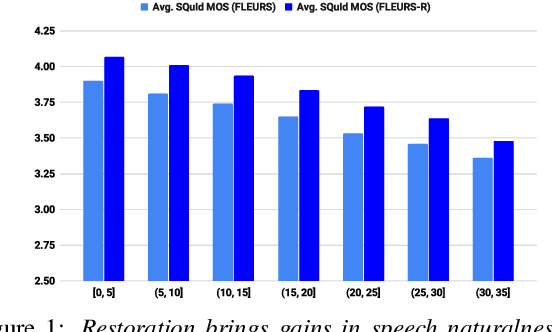
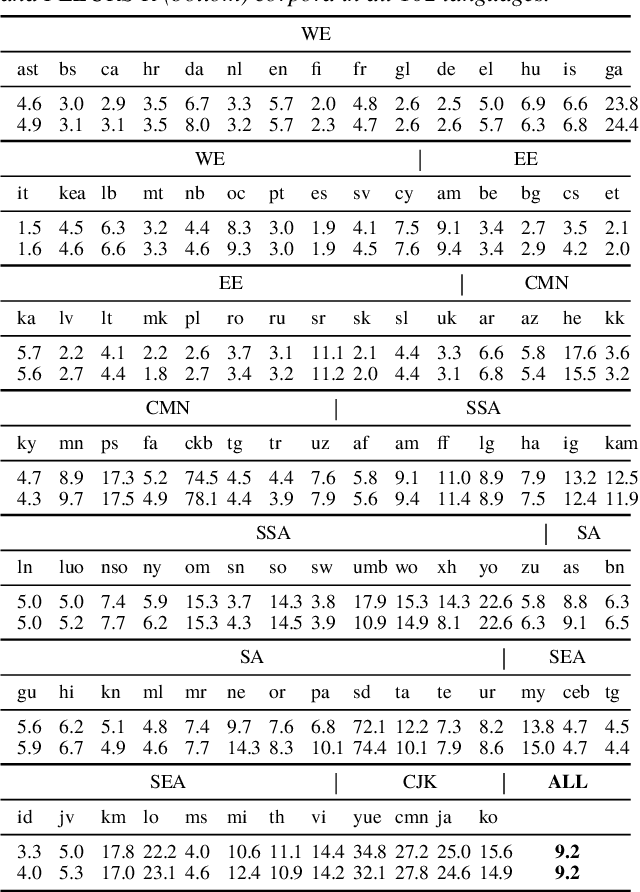
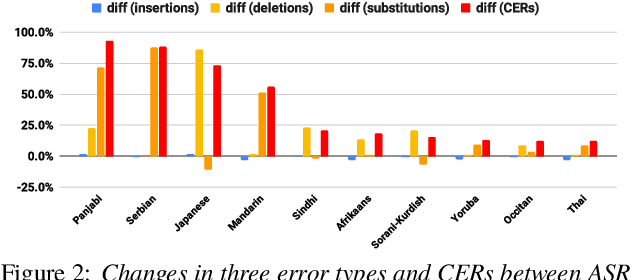
This paper introduces FLEURS-R, a speech restoration applied version of the Few-shot Learning Evaluation of Universal Representations of Speech (FLEURS) corpus. FLEURS-R maintains an N-way parallel speech corpus in 102 languages as FLEURS, with improved audio quality and fidelity by applying the speech restoration model Miipher. The aim of FLEURS-R is to advance speech technology in more languages and catalyze research including text-to-speech (TTS) and other speech generation tasks in low-resource languages. Comprehensive evaluations with the restored speech and TTS baseline models trained from the new corpus show that the new corpus obtained significantly improved speech quality while maintaining the semantic contents of the speech. The corpus is publicly released via Hugging Face.
SimulTron: On-Device Simultaneous Speech to Speech Translation
Jun 04, 2024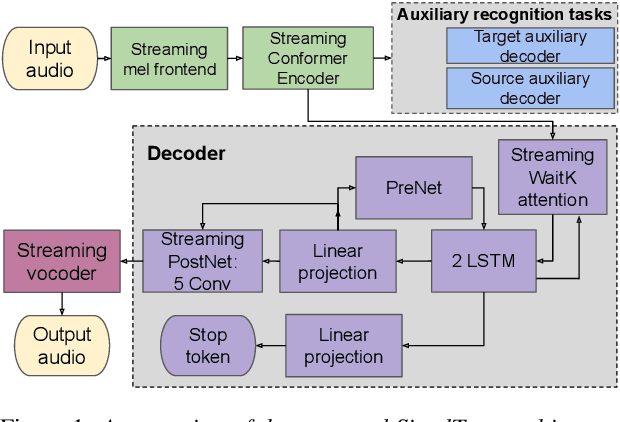
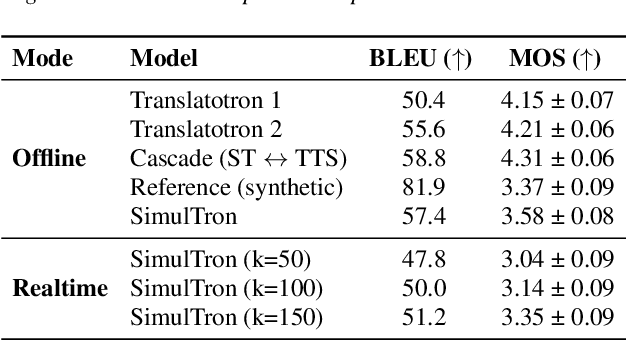

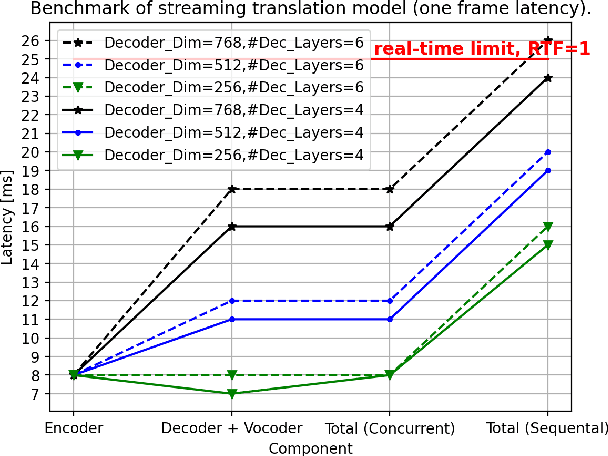
Simultaneous speech-to-speech translation (S2ST) holds the promise of breaking down communication barriers and enabling fluid conversations across languages. However, achieving accurate, real-time translation through mobile devices remains a major challenge. We introduce SimulTron, a novel S2ST architecture designed to tackle this task. SimulTron is a lightweight direct S2ST model that uses the strengths of the Translatotron framework while incorporating key modifications for streaming operation, and an adjustable fixed delay. Our experiments show that SimulTron surpasses Translatotron 2 in offline evaluations. Furthermore, real-time evaluations reveal that SimulTron improves upon the performance achieved by Translatotron 1. Additionally, SimulTron achieves superior BLEU scores and latency compared to previous real-time S2ST method on the MuST-C dataset. Significantly, we have successfully deployed SimulTron on a Pixel 7 Pro device, show its potential for simultaneous S2ST on-device.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Extending Multilingual Speech Synthesis to 100+ Languages without Transcribed Data
Feb 29, 2024



Collecting high-quality studio recordings of audio is challenging, which limits the language coverage of text-to-speech (TTS) systems. This paper proposes a framework for scaling a multilingual TTS model to 100+ languages using found data without supervision. The proposed framework combines speech-text encoder pretraining with unsupervised training using untranscribed speech and unspoken text data sources, thereby leveraging massively multilingual joint speech and text representation learning. Without any transcribed speech in a new language, this TTS model can generate intelligible speech in >30 unseen languages (CER difference of <10% to ground truth). With just 15 minutes of transcribed, found data, we can reduce the intelligibility difference to 1% or less from the ground-truth, and achieve naturalness scores that match the ground-truth in several languages.
SayTap: Language to Quadrupedal Locomotion
Jun 14, 2023Large language models (LLMs) have demonstrated the potential to perform high-level planning. Yet, it remains a challenge for LLMs to comprehend low-level commands, such as joint angle targets or motor torques. This paper proposes an approach to use foot contact patterns as an interface that bridges human commands in natural language and a locomotion controller that outputs these low-level commands. This results in an interactive system for quadrupedal robots that allows the users to craft diverse locomotion behaviors flexibly. We contribute an LLM prompt design, a reward function, and a method to expose the controller to the feasible distribution of contact patterns. The results are a controller capable of achieving diverse locomotion patterns that can be transferred to real robot hardware. Compared with other design choices, the proposed approach enjoys more than 50% success rate in predicting the correct contact patterns and can solve 10 more tasks out of a total of 30 tasks. Our project site is: https://saytap.github.io.
Translatotron 3: Speech to Speech Translation with Monolingual Data
Jun 01, 2023This paper presents Translatotron 3, a novel approach to train a direct speech-to-speech translation model from monolingual speech-text datasets only in a fully unsupervised manner. Translatotron 3 combines masked autoencoder, unsupervised embedding mapping, and back-translation to achieve this goal. Experimental results in speech-to-speech translation tasks between Spanish and English show that Translatotron 3 outperforms a baseline cascade system, reporting 18.14 BLEU points improvement on the synthesized Unpaired-Conversational dataset. In contrast to supervised approaches that necessitate real paired data, which is unavailable, or specialized modeling to replicate para-/non-linguistic information, Translatotron 3 showcases its capability to retain para-/non-linguistic such as pauses, speaking rates, and speaker identity. Audio samples can be found in our website http://google-research.github.io/lingvo-lab/translatotron3