 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeECLeKTic: a Novel Challenge Set for Evaluation of Cross-Lingual Knowledge Transfer
Feb 28, 2025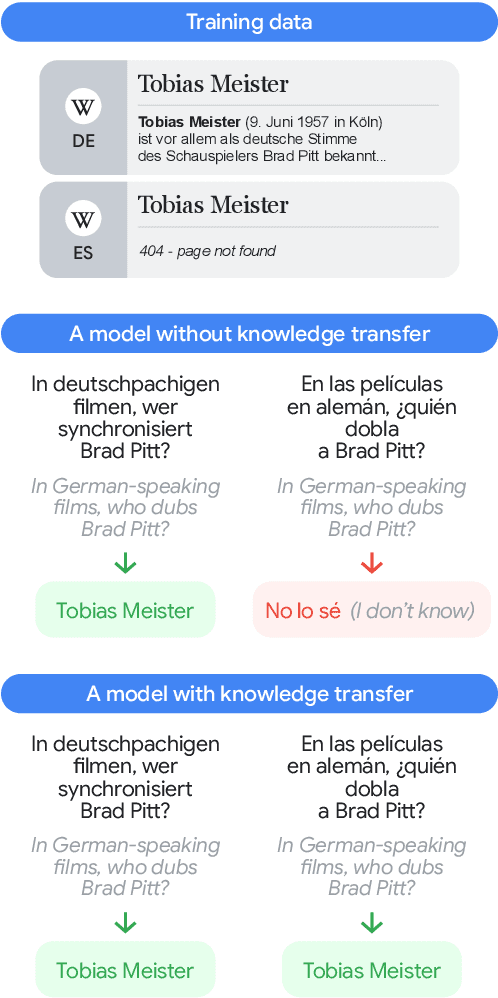
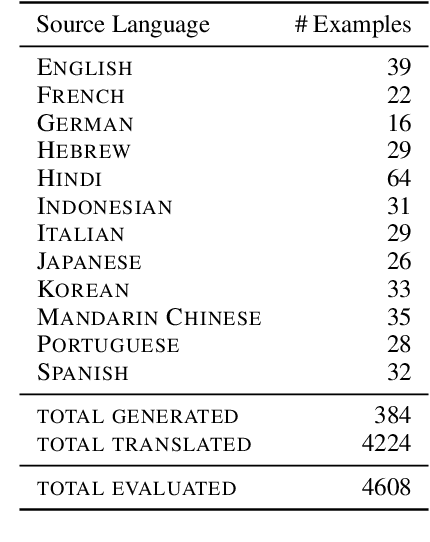
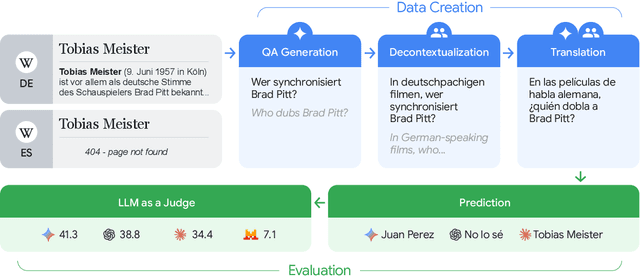
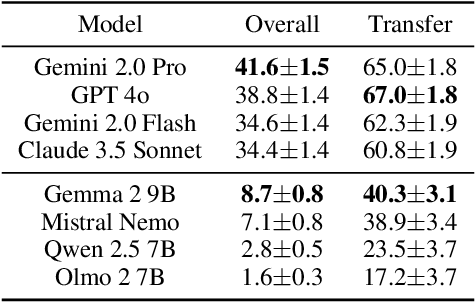
To achieve equitable performance across languages, multilingual large language models (LLMs) must be able to abstract knowledge beyond the language in which it was acquired. However, the current literature lacks reliable ways to measure LLMs' capability of cross-lingual knowledge transfer. To that end, we present ECLeKTic, a multilingual closed-book QA (CBQA) dataset that Evaluates Cross-Lingual Knowledge Transfer in a simple, black-box manner. We detected information with uneven coverage across languages by controlling for presence and absence of Wikipedia articles in 12 languages. We generated knowledge-seeking questions in a source language, for which the answer appears in a relevant Wikipedia article and translated them to all other 11 languages, for which the respective Wikipedias lack equivalent articles. Assuming that Wikipedia reflects the prominent knowledge in the LLM's training data, to solve ECLeKTic's CBQA task the model is required to transfer knowledge between languages. Experimenting with 8 LLMs, we show that SOTA models struggle to effectively share knowledge across, languages even if they can predict the answer well for queries in the same language the knowledge was acquired in.
WMT24++: Expanding the Language Coverage of WMT24 to 55 Languages & Dialects
Feb 18, 2025
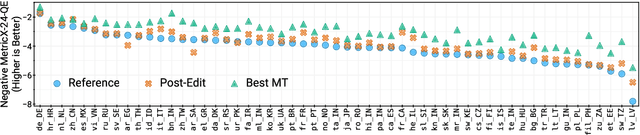


As large language models (LLM) become more and more capable in languages other than English, it is important to collect benchmark datasets in order to evaluate their multilingual performance, including on tasks like machine translation (MT). In this work, we extend the WMT24 dataset to cover 55 languages by collecting new human-written references and post-edits for 46 new languages and dialects in addition to post-edits of the references in 8 out of 9 languages in the original WMT24 dataset. The dataset covers four domains: literary, news, social, and speech. We benchmark a variety of MT providers and LLMs on the collected dataset using automatic metrics and find that LLMs are the best-performing MT systems in all 55 languages. These results should be confirmed using a human-based evaluation, which we leave for future work.
FLEURS-R: A Restored Multilingual Speech Corpus for Generation Tasks
Aug 12, 2024
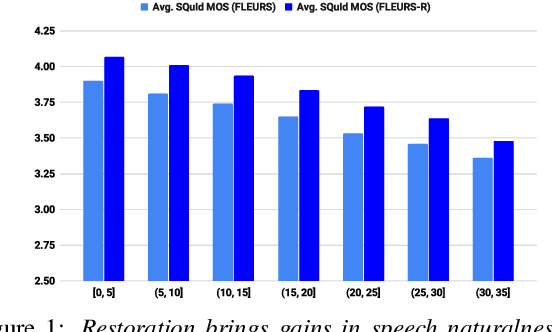
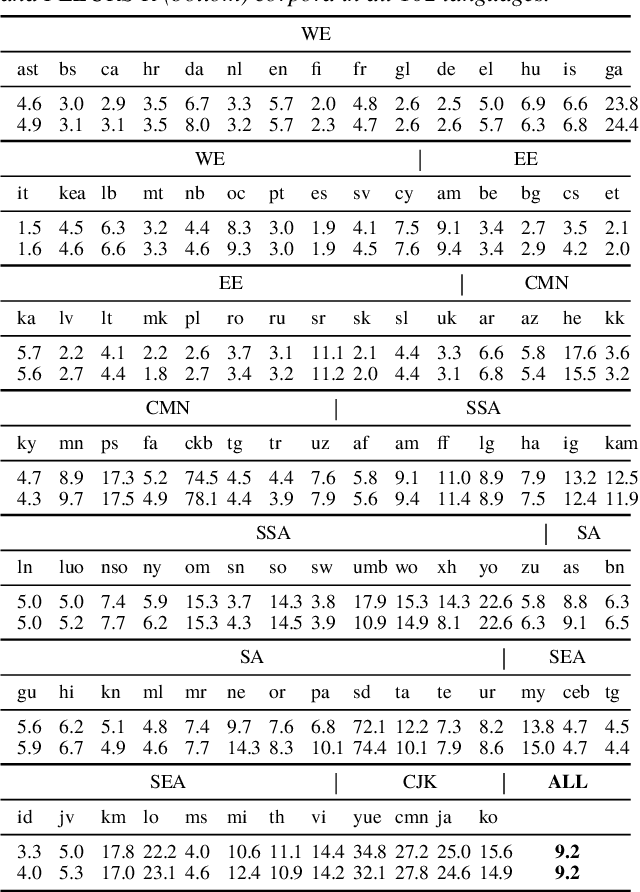
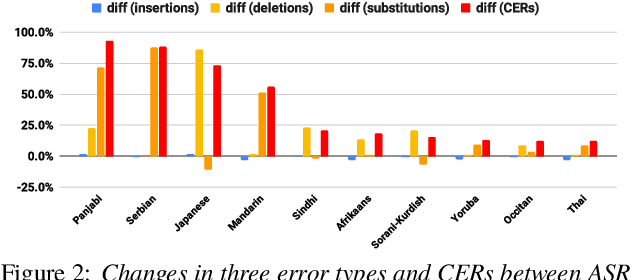
This paper introduces FLEURS-R, a speech restoration applied version of the Few-shot Learning Evaluation of Universal Representations of Speech (FLEURS) corpus. FLEURS-R maintains an N-way parallel speech corpus in 102 languages as FLEURS, with improved audio quality and fidelity by applying the speech restoration model Miipher. The aim of FLEURS-R is to advance speech technology in more languages and catalyze research including text-to-speech (TTS) and other speech generation tasks in low-resource languages. Comprehensive evaluations with the restored speech and TTS baseline models trained from the new corpus show that the new corpus obtained significantly improved speech quality while maintaining the semantic contents of the speech. The corpus is publicly released via Hugging Face.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Multimodal Modeling For Spoken Language Identification
Sep 19, 2023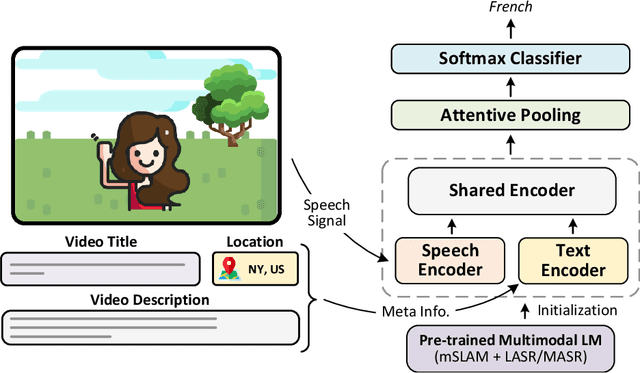
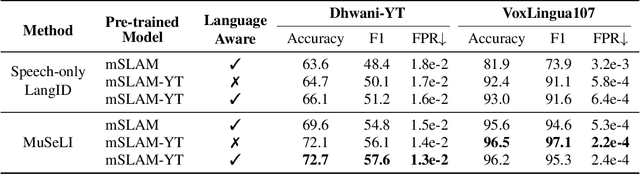
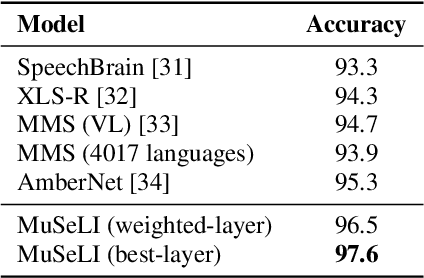
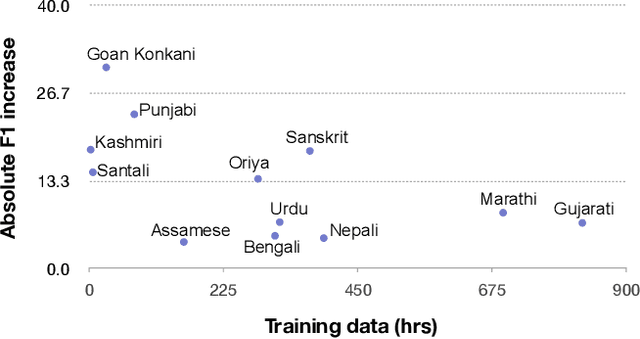
Spoken language identification refers to the task of automatically predicting the spoken language in a given utterance. Conventionally, it is modeled as a speech-based language identification task. Prior techniques have been constrained to a single modality; however in the case of video data there is a wealth of other metadata that may be beneficial for this task. In this work, we propose MuSeLI, a Multimodal Spoken Language Identification method, which delves into the use of various metadata sources to enhance language identification. Our study reveals that metadata such as video title, description and geographic location provide substantial information to identify the spoken language of the multimedia recording. We conduct experiments using two diverse public datasets of YouTube videos, and obtain state-of-the-art results on the language identification task. We additionally conduct an ablation study that describes the distinct contribution of each modality for language recognition.
Google USM: Scaling Automatic Speech Recognition Beyond 100 Languages
Mar 03, 2023
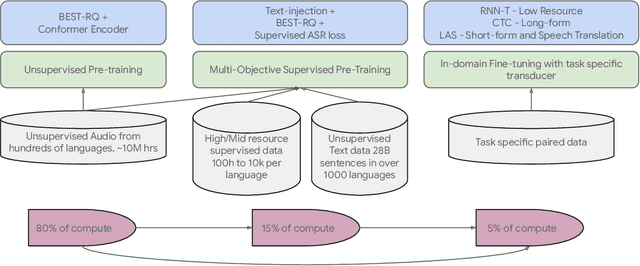
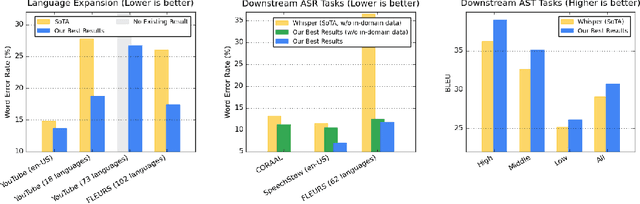

We introduce the Universal Speech Model (USM), a single large model that performs automatic speech recognition (ASR) across 100+ languages. This is achieved by pre-training the encoder of the model on a large unlabeled multilingual dataset of 12 million (M) hours spanning over 300 languages, and fine-tuning on a smaller labeled dataset. We use multilingual pre-training with random-projection quantization and speech-text modality matching to achieve state-of-the-art performance on downstream multilingual ASR and speech-to-text translation tasks. We also demonstrate that despite using a labeled training set 1/7-th the size of that used for the Whisper model, our model exhibits comparable or better performance on both in-domain and out-of-domain speech recognition tasks across many languages.
SQuId: Measuring Speech Naturalness in Many Languages
Oct 12, 2022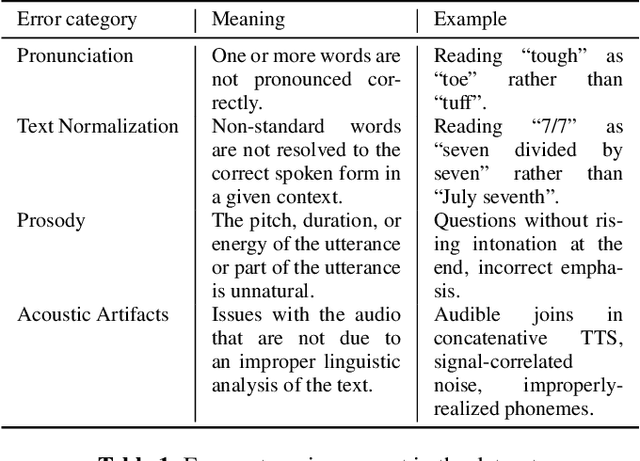
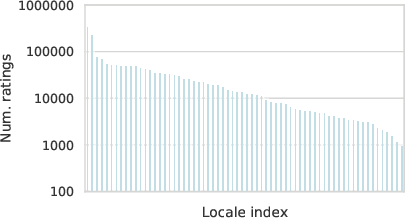

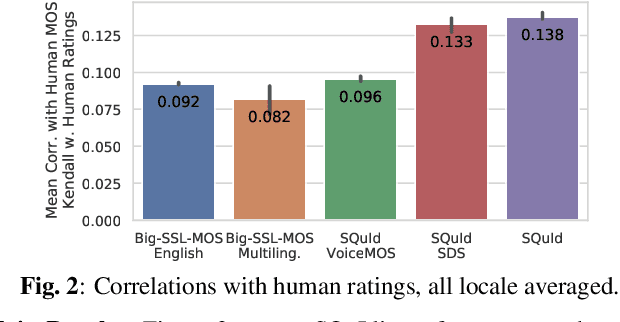
Much of text-to-speech research relies on human evaluation, which incurs heavy costs and slows down the development process. The problem is particularly acute in heavily multilingual applications, where recruiting and polling judges can take weeks. We introduce SQuId (Speech Quality Identification), a multilingual naturalness prediction model trained on over a million ratings and tested in 65 locales-the largest effort of this type to date. The main insight is that training one model on many locales consistently outperforms mono-locale baselines. We present our task, the model, and show that it outperforms a competitive baseline based on w2v-BERT and VoiceMOS by 50.0%. We then demonstrate the effectiveness of cross-locale transfer during fine-tuning and highlight its effect on zero-shot locales, i.e., locales for which there is no fine-tuning data. Through a series of analyses, we highlight the role of non-linguistic effects such as sound artifacts in cross-locale transfer. Finally, we present the effect of our design decision, e.g., model size, pre-training diversity, and language rebalancing with several ablation experiments.
FRMT: A Benchmark for Few-Shot Region-Aware Machine Translation
Oct 01, 2022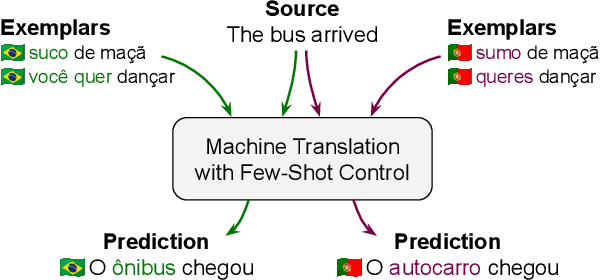
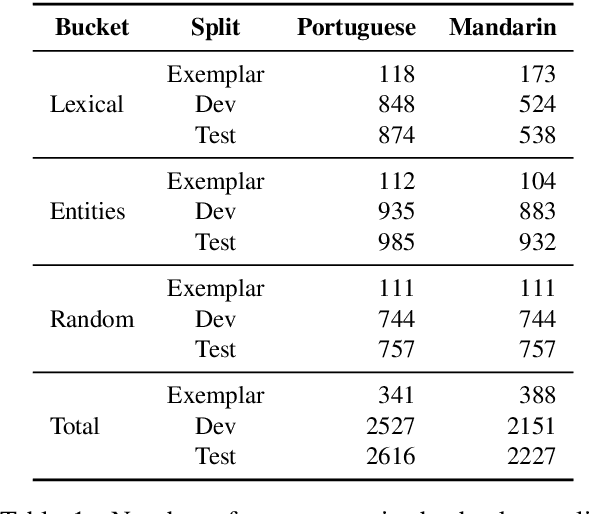

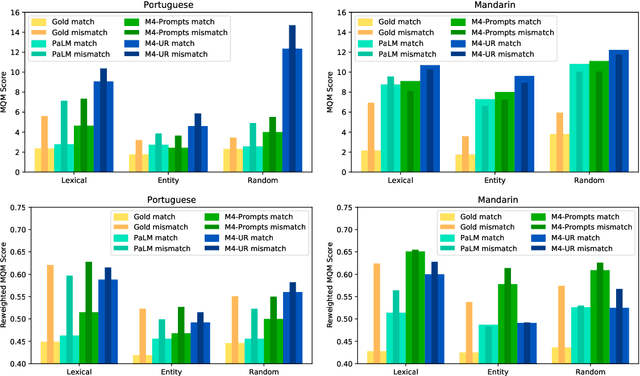
We present FRMT, a new dataset and evaluation benchmark for Few-shot Region-aware Machine Translation, a type of style-targeted translation. The dataset consists of professional translations from English into two regional variants each of Portuguese and Mandarin Chinese. Source documents are selected to enable detailed analysis of phenomena of interest, including lexically distinct terms and distractor terms. We explore automatic evaluation metrics for FRMT and validate their correlation with expert human evaluation across both region-matched and mismatched rating scenarios. Finally, we present a number of baseline models for this task, and offer guidelines for how researchers can train, evaluate, and compare their own models. Our dataset and evaluation code are publicly available: https://bit.ly/frmt-task
FLEURS: Few-shot Learning Evaluation of Universal Representations of Speech
May 25, 2022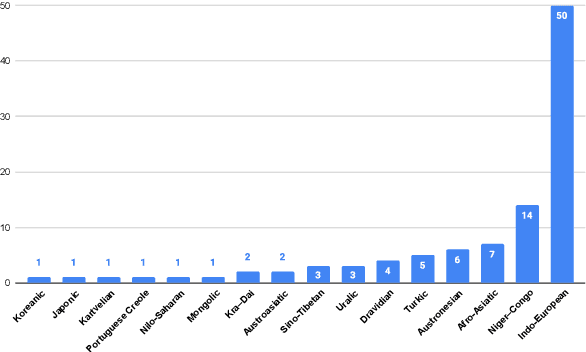
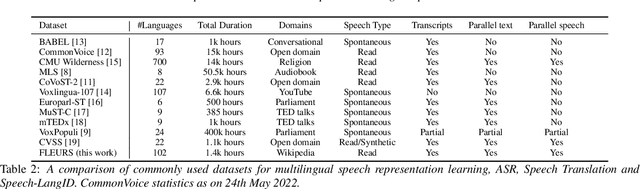
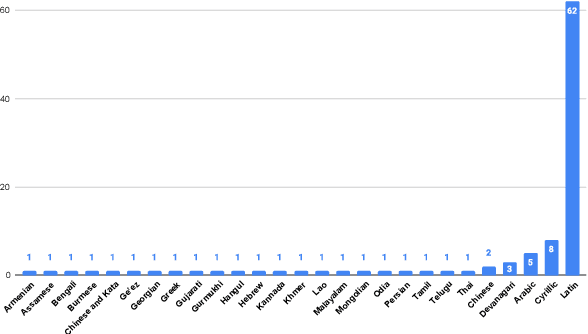
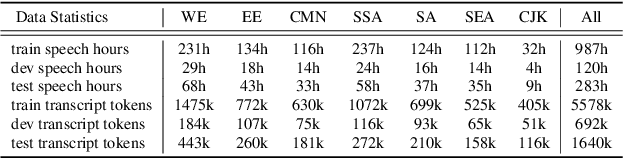
We introduce FLEURS, the Few-shot Learning Evaluation of Universal Representations of Speech benchmark. FLEURS is an n-way parallel speech dataset in 102 languages built on top of the machine translation FLoRes-101 benchmark, with approximately 12 hours of speech supervision per language. FLEURS can be used for a variety of speech tasks, including Automatic Speech Recognition (ASR), Speech Language Identification (Speech LangID), Translation and Retrieval. In this paper, we provide baselines for the tasks based on multilingual pre-trained models like mSLAM. The goal of FLEURS is to enable speech technology in more languages and catalyze research in low-resource speech understanding.
Building Machine Translation Systems for the Next Thousand Languages
May 16, 2022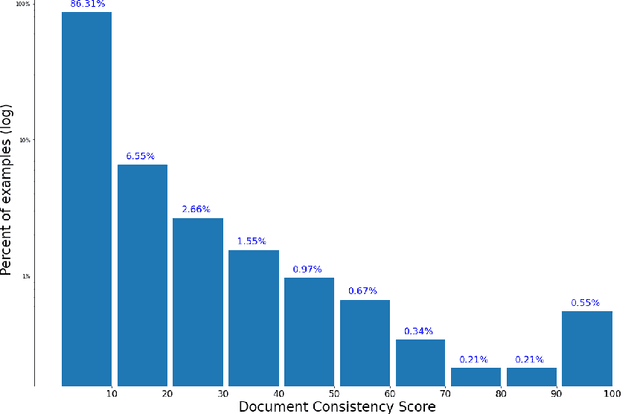
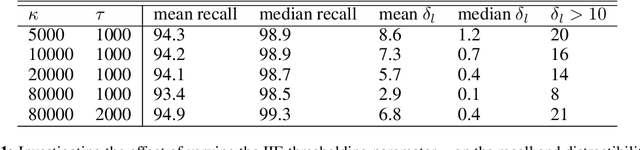

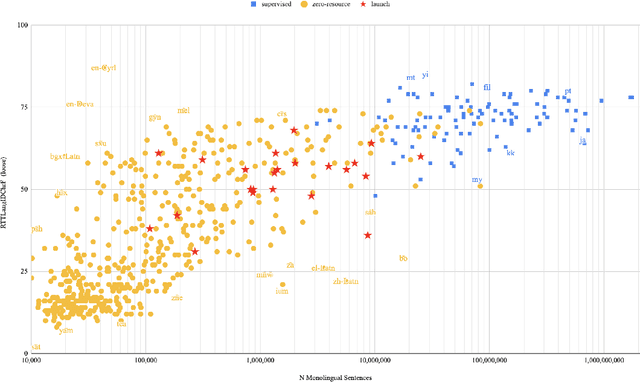
In this paper we share findings from our effort to build practical machine translation (MT) systems capable of translating across over one thousand languages. We describe results in three research domains: (i) Building clean, web-mined datasets for 1500+ languages by leveraging semi-supervised pre-training for language identification and developing data-driven filtering techniques; (ii) Developing practical MT models for under-served languages by leveraging massively multilingual models trained with supervised parallel data for over 100 high-resource languages and monolingual datasets for an additional 1000+ languages; and (iii) Studying the limitations of evaluation metrics for these languages and conducting qualitative analysis of the outputs from our MT models, highlighting several frequent error modes of these types of models. We hope that our work provides useful insights to practitioners working towards building MT systems for currently understudied languages, and highlights research directions that can complement the weaknesses of massively multilingual models in data-sparse settings.