 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
MD3: The Multi-Dialect Dataset of Dialogues
May 19, 2023



We introduce a new dataset of conversational speech representing English from India, Nigeria, and the United States. The Multi-Dialect Dataset of Dialogues (MD3) strikes a new balance between open-ended conversational speech and task-oriented dialogue by prompting participants to perform a series of short information-sharing tasks. This facilitates quantitative cross-dialectal comparison, while avoiding the imposition of a restrictive task structure that might inhibit the expression of dialect features. Preliminary analysis of the dataset reveals significant differences in syntax and in the use of discourse markers. The dataset, which will be made publicly available with the publication of this paper, includes more than 20 hours of audio and more than 200,000 orthographically-transcribed tokens.
TaTa: A Multilingual Table-to-Text Dataset for African Languages
Oct 31, 2022



Existing data-to-text generation datasets are mostly limited to English. To address this lack of data, we create Table-to-Text in African languages (TaTa), the first large multilingual table-to-text dataset with a focus on African languages. We created TaTa by transcribing figures and accompanying text in bilingual reports by the Demographic and Health Surveys Program, followed by professional translation to make the dataset fully parallel. TaTa includes 8,700 examples in nine languages including four African languages (Hausa, Igbo, Swahili, and Yor\`ub\'a) and a zero-shot test language (Russian). We additionally release screenshots of the original figures for future research on multilingual multi-modal approaches. Through an in-depth human evaluation, we show that TaTa is challenging for current models and that less than half the outputs from an mT5-XXL-based model are understandable and attributable to the source data. We further demonstrate that existing metrics perform poorly for TaTa and introduce learned metrics that achieve a high correlation with human judgments. We release all data and annotations at https://github.com/google-research/url-nlp.
FLEURS: Few-shot Learning Evaluation of Universal Representations of Speech
May 25, 2022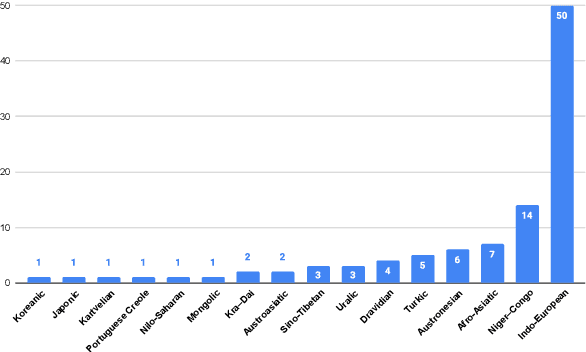
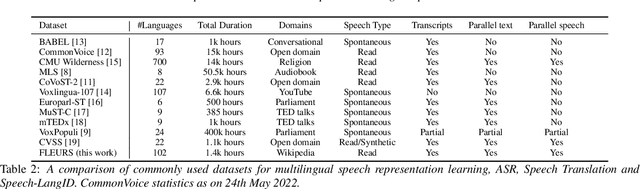
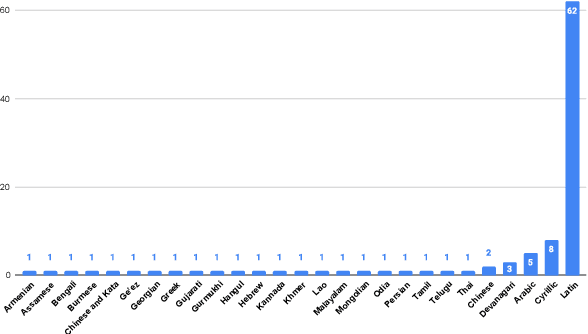
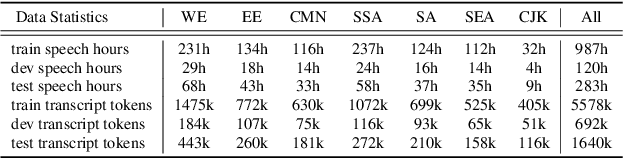
We introduce FLEURS, the Few-shot Learning Evaluation of Universal Representations of Speech benchmark. FLEURS is an n-way parallel speech dataset in 102 languages built on top of the machine translation FLoRes-101 benchmark, with approximately 12 hours of speech supervision per language. FLEURS can be used for a variety of speech tasks, including Automatic Speech Recognition (ASR), Speech Language Identification (Speech LangID), Translation and Retrieval. In this paper, we provide baselines for the tasks based on multilingual pre-trained models like mSLAM. The goal of FLEURS is to enable speech technology in more languages and catalyze research in low-resource speech understanding.
XTREME-S: Evaluating Cross-lingual Speech Representations
Apr 13, 2022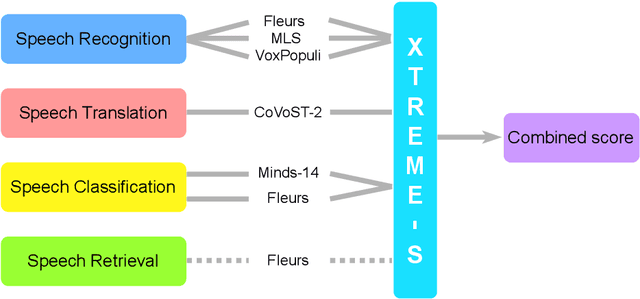
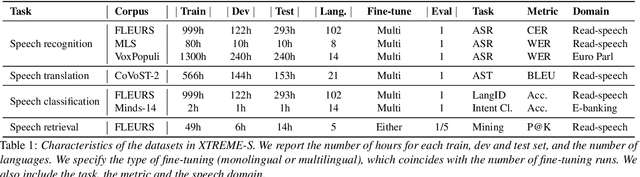
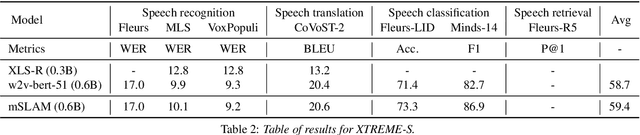
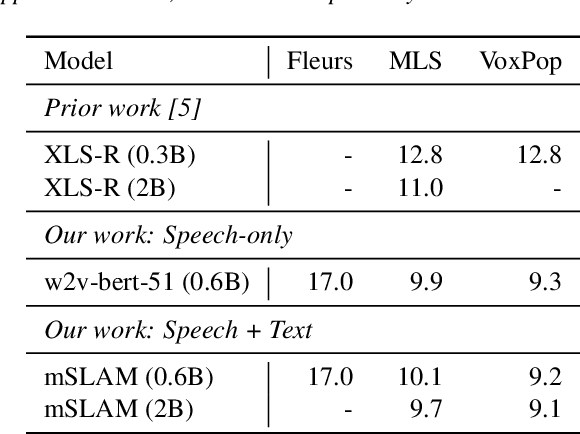
We introduce XTREME-S, a new benchmark to evaluate universal cross-lingual speech representations in many languages. XTREME-S covers four task families: speech recognition, classification, speech-to-text translation and retrieval. Covering 102 languages from 10+ language families, 3 different domains and 4 task families, XTREME-S aims to simplify multilingual speech representation evaluation, as well as catalyze research in "universal" speech representation learning. This paper describes the new benchmark and establishes the first speech-only and speech-text baselines using XLS-R and mSLAM on all downstream tasks. We motivate the design choices and detail how to use the benchmark. Datasets and fine-tuning scripts are made easily accessible at https://hf.co/datasets/google/xtreme_s.
Quality at a Glance: An Audit of Web-Crawled Multilingual Datasets
Mar 22, 2021
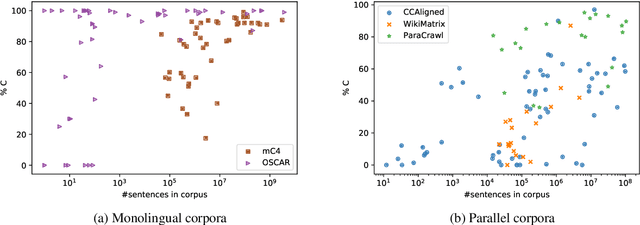

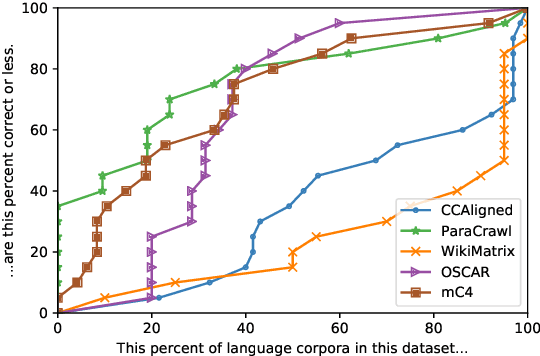
With the success of large-scale pre-training and multilingual modeling in Natural Language Processing (NLP), recent years have seen a proliferation of large, web-mined text datasets covering hundreds of languages. However, to date there has been no systematic analysis of the quality of these publicly available datasets, or whether the datasets actually contain content in the languages they claim to represent. In this work, we manually audit the quality of 205 language-specific corpora released with five major public datasets (CCAligned, ParaCrawl, WikiMatrix, OSCAR, mC4), and audit the correctness of language codes in a sixth (JW300). We find that lower-resource corpora have systematic issues: at least 15 corpora are completely erroneous, and a significant fraction contains less than 50% sentences of acceptable quality. Similarly, we find 82 corpora that are mislabeled or use nonstandard/ambiguous language codes. We demonstrate that these issues are easy to detect even for non-speakers of the languages in question, and supplement the human judgements with automatic analyses. Inspired by our analysis, we recommend techniques to evaluate and improve multilingual corpora and discuss the risks that come with low-quality data releases.
Google Crowdsourced Speech Corpora and Related Open-Source Resources for Low-Resource Languages and Dialects: An Overview
Oct 14, 2020This paper presents an overview of a program designed to address the growing need for developing freely available speech resources for under-represented languages. At present we have released 38 datasets for building text-to-speech and automatic speech recognition applications for languages and dialects of South and Southeast Asia, Africa, Europe and South America. The paper describes the methodology used for developing such corpora and presents some of our findings that could benefit under-represented language communities.