Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLEURS: Few-shot Learning Evaluation of Universal Representations of Speech
Paper and Code
May 25, 2022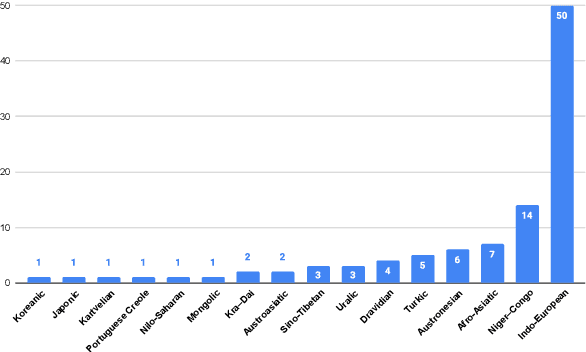
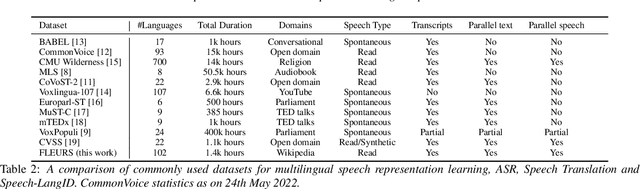
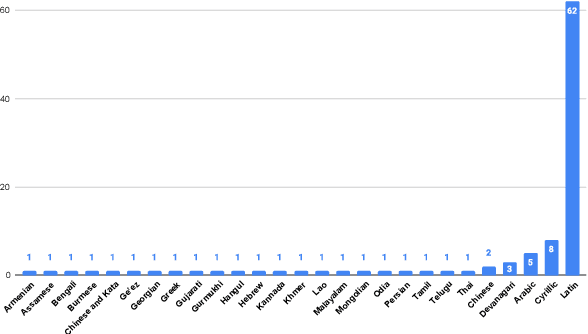
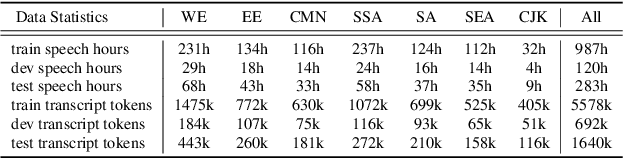
We introduce FLEURS, the Few-shot Learning Evaluation of Universal Representations of Speech benchmark. FLEURS is an n-way parallel speech dataset in 102 languages built on top of the machine translation FLoRes-101 benchmark, with approximately 12 hours of speech supervision per language. FLEURS can be used for a variety of speech tasks, including Automatic Speech Recognition (ASR), Speech Language Identification (Speech LangID), Translation and Retrieval. In this paper, we provide baselines for the tasks based on multilingual pre-trained models like mSLAM. The goal of FLEURS is to enable speech technology in more languages and catalyze research in low-resource speech understanding.
View paper on