 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMERLIN: A Testbed for Multilingual Multimodal Entity Recognition and Linking
Oct 16, 2025This paper introduces MERLIN, a novel testbed system for the task of Multilingual Multimodal Entity Linking. The created dataset includes BBC news article titles, paired with corresponding images, in five languages: Hindi, Japanese, Indonesian, Vietnamese, and Tamil, featuring over 7,000 named entity mentions linked to 2,500 unique Wikidata entities. We also include several benchmarks using multilingual and multimodal entity linking methods exploring different language models like LLaMa-2 and Aya-23. Our findings indicate that incorporating visual data improves the accuracy of entity linking, especially for entities where the textual context is ambiguous or insufficient, and particularly for models that do not have strong multilingual abilities. For the work, the dataset, methods are available here at https://github.com/rsathya4802/merlin
Grounding Multilingual Multimodal LLMs With Cultural Knowledge
Aug 12, 2025Multimodal Large Language Models excel in high-resource settings, but often misinterpret long-tail cultural entities and underperform in low-resource languages. To address this gap, we propose a data-centric approach that directly grounds MLLMs in cultural knowledge. Leveraging a large scale knowledge graph from Wikidata, we collect images that represent culturally significant entities, and generate synthetic multilingual visual question answering data. The resulting dataset, CulturalGround, comprises 22 million high-quality, culturally-rich VQA pairs spanning 42 countries and 39 languages. We train an open-source MLLM CulturalPangea on CulturalGround, interleaving standard multilingual instruction-tuning data to preserve general abilities. CulturalPangea achieves state-of-the-art performance among open models on various culture-focused multilingual multimodal benchmarks, outperforming prior models by an average of 5.0 without degrading results on mainstream vision-language tasks. Our findings show that our targeted, culturally grounded approach could substantially narrow the cultural gap in MLLMs and offer a practical path towards globally inclusive multimodal systems.
CAIRe: Cultural Attribution of Images by Retrieval-Augmented Evaluation
Jun 10, 2025As text-to-image models become increasingly prevalent, ensuring their equitable performance across diverse cultural contexts is critical. Efforts to mitigate cross-cultural biases have been hampered by trade-offs, including a loss in performance, factual inaccuracies, or offensive outputs. Despite widespread recognition of these challenges, an inability to reliably measure these biases has stalled progress. To address this gap, we introduce CAIRe, a novel evaluation metric that assesses the degree of cultural relevance of an image, given a user-defined set of labels. Our framework grounds entities and concepts in the image to a knowledge base and uses factual information to give independent graded judgments for each culture label. On a manually curated dataset of culturally salient but rare items built using language models, CAIRe surpasses all baselines by 28% F1 points. Additionally, we construct two datasets for culturally universal concept, one comprising of T2I-generated outputs and another retrieved from naturally occurring data. CAIRe achieves Pearson's correlations of 0.56 and 0.66 with human ratings on these sets, based on a 5-point Likert scale of cultural relevance. This demonstrates its strong alignment with human judgment across diverse image sources.
Towards Automatic Evaluation for Image Transcreation
Dec 18, 2024



Beyond conventional paradigms of translating speech and text, recently, there has been interest in automated transcreation of images to facilitate localization of visual content across different cultures. Attempts to define this as a formal Machine Learning (ML) problem have been impeded by the lack of automatic evaluation mechanisms, with previous work relying solely on human evaluation. In this paper, we seek to close this gap by proposing a suite of automatic evaluation metrics inspired by machine translation (MT) metrics, categorized into: a) Object-based, b) Embedding-based, and c) VLM-based. Drawing on theories from translation studies and real-world transcreation practices, we identify three critical dimensions of image transcreation: cultural relevance, semantic equivalence and visual similarity, and design our metrics to evaluate systems along these axes. Our results show that proprietary VLMs best identify cultural relevance and semantic equivalence, while vision-encoder representations are adept at measuring visual similarity. Meta-evaluation across 7 countries shows our metrics agree strongly with human ratings, with average segment-level correlations ranging from 0.55-0.87. Finally, through a discussion of the merits and demerits of each metric, we offer a robust framework for automated image transcreation evaluation, grounded in both theoretical foundations and practical application. Our code can be found here: https://github.com/simran-khanuja/automatic-eval-transcreation
Pangea: A Fully Open Multilingual Multimodal LLM for 39 Languages
Oct 21, 2024Despite recent advances in multimodal large language models (MLLMs), their development has predominantly focused on English- and western-centric datasets and tasks, leaving most of the world's languages and diverse cultural contexts underrepresented. This paper introduces Pangea, a multilingual multimodal LLM trained on PangeaIns, a diverse 6M instruction dataset spanning 39 languages. PangeaIns features: 1) high-quality English instructions, 2) carefully machine-translated instructions, and 3) culturally relevant multimodal tasks to ensure cross-cultural coverage. To rigorously assess models' capabilities, we introduce PangeaBench, a holistic evaluation suite encompassing 14 datasets covering 47 languages. Results show that Pangea significantly outperforms existing open-source models in multilingual settings and diverse cultural contexts. Ablation studies further reveal the importance of English data proportions, language popularity, and the number of multimodal training samples on overall performance. We fully open-source our data, code, and trained checkpoints, to facilitate the development of inclusive and robust multilingual MLLMs, promoting equity and accessibility across a broader linguistic and cultural spectrum.
NaturalBench: Evaluating Vision-Language Models on Natural Adversarial Samples
Oct 18, 2024
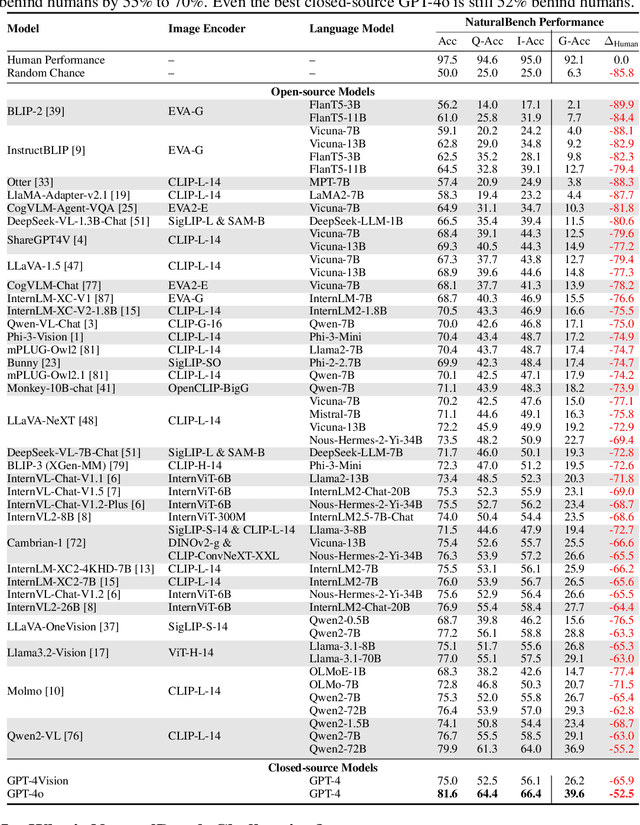

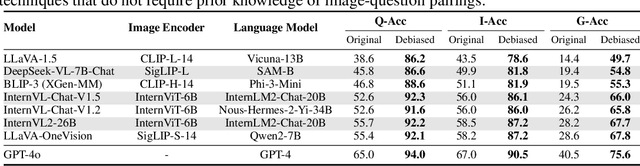
Vision-language models (VLMs) have made significant progress in recent visual-question-answering (VQA) benchmarks that evaluate complex visio-linguistic reasoning. However, are these models truly effective? In this work, we show that VLMs still struggle with natural images and questions that humans can easily answer, which we term natural adversarial samples. We also find it surprisingly easy to generate these VQA samples from natural image-text corpora using off-the-shelf models like CLIP and ChatGPT. We propose a semi-automated approach to collect a new benchmark, NaturalBench, for reliably evaluating VLMs with 10,000 human-verified VQA samples. Crucially, we adopt a $\textbf{vision-centric}$ design by pairing each question with two images that yield different answers, preventing blind solutions from answering without using the images. This makes NaturalBench more challenging than previous benchmarks that can be solved with commonsense priors. We evaluate 53 state-of-the-art VLMs on NaturalBench, showing that models like LLaVA-OneVision, Cambrian-1, Llama3.2-Vision, Molmo, Qwen2-VL, and even GPT-4o lag 50%-70% behind human performance (over 90%). We analyze why NaturalBench is hard from two angles: (1) Compositionality: Solving NaturalBench requires diverse visio-linguistic skills, including understanding attribute bindings, object relationships, and advanced reasoning like logic and counting. To this end, unlike prior work that uses a single tag per sample, we tag each NaturalBench sample with 1 to 8 skill tags for fine-grained evaluation. (2) Biases: NaturalBench exposes severe biases in VLMs, as models often choose the same answer regardless of the image. Lastly, we apply our benchmark curation method to diverse data sources, including long captions (over 100 words) and non-English languages like Chinese and Hindi, highlighting its potential for dynamic evaluations of VLMs.
An image speaks a thousand words, but can everyone listen? On translating images for cultural relevance
Apr 01, 2024



Given the rise of multimedia content, human translators increasingly focus on culturally adapting not only words but also other modalities such as images to convey the same meaning. While several applications stand to benefit from this, machine translation systems remain confined to dealing with language in speech and text. In this work, we take a first step towards translating images to make them culturally relevant. First, we build three pipelines comprising state-of-the-art generative models to do the task. Next, we build a two-part evaluation dataset: i) concept: comprising 600 images that are cross-culturally coherent, focusing on a single concept per image, and ii) application: comprising 100 images curated from real-world applications. We conduct a multi-faceted human evaluation of translated images to assess for cultural relevance and meaning preservation. We find that as of today, image-editing models fail at this task, but can be improved by leveraging LLMs and retrievers in the loop. Best pipelines can only translate 5% of images for some countries in the easier concept dataset and no translation is successful for some countries in the application dataset, highlighting the challenging nature of the task. Our code and data is released here: https://github.com/simran-khanuja/image-transcreation.
What Is Missing in Multilingual Visual Reasoning and How to Fix It
Mar 03, 2024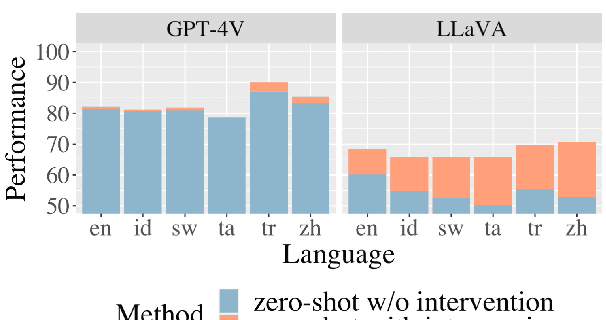


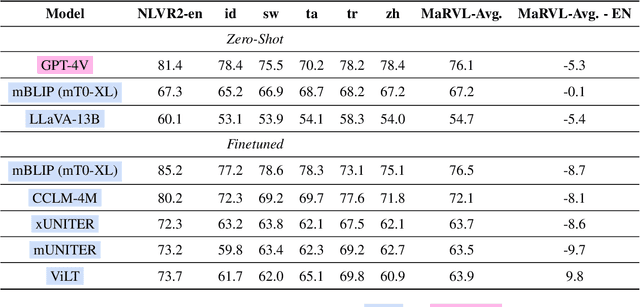
NLP models today strive for supporting multiple languages and modalities, improving accessibility for diverse users. In this paper, we evaluate their multilingual, multimodal capabilities by testing on a visual reasoning task. We observe that proprietary systems like GPT-4V obtain the best performance on this task now, but open models lag in comparison. Surprisingly, GPT-4V exhibits similar performance between English and other languages, indicating the potential for equitable system development across languages. Our analysis on model failures reveals three key aspects that make this task challenging: multilinguality, complex reasoning, and multimodality. To address these challenges, we propose three targeted interventions including a translate-test approach to tackle multilinguality, a visual programming approach to break down complex reasoning, and a novel method that leverages image captioning to address multimodality. Our interventions achieve the best open performance on this task in a zero-shot setting, boosting open model LLaVA by 13.4%, while also minorly improving GPT-4V's performance.
DeMuX: Data-efficient Multilingual Learning
Nov 10, 2023



We consider the task of optimally fine-tuning pre-trained multilingual models, given small amounts of unlabelled target data and an annotation budget. In this paper, we introduce DEMUX, a framework that prescribes the exact data-points to label from vast amounts of unlabelled multilingual data, having unknown degrees of overlap with the target set. Unlike most prior works, our end-to-end framework is language-agnostic, accounts for model representations, and supports multilingual target configurations. Our active learning strategies rely upon distance and uncertainty measures to select task-specific neighbors that are most informative to label, given a model. DeMuX outperforms strong baselines in 84% of the test cases, in the zero-shot setting of disjoint source and target language sets (including multilingual target pools), across three models and four tasks. Notably, in low-budget settings (5-100 examples), we observe gains of up to 8-11 F1 points for token-level tasks, and 2-5 F1 for complex tasks. Our code is released here: https://github.com/simran-khanuja/demux.
Multi-lingual and Multi-cultural Figurative Language Understanding
May 25, 2023Figurative language permeates human communication, but at the same time is relatively understudied in NLP. Datasets have been created in English to accelerate progress towards measuring and improving figurative language processing in language models (LMs). However, the use of figurative language is an expression of our cultural and societal experiences, making it difficult for these phrases to be universally applicable. In this work, we create a figurative language inference dataset, \datasetname, for seven diverse languages associated with a variety of cultures: Hindi, Indonesian, Javanese, Kannada, Sundanese, Swahili and Yoruba. Our dataset reveals that each language relies on cultural and regional concepts for figurative expressions, with the highest overlap between languages originating from the same region. We assess multilingual LMs' abilities to interpret figurative language in zero-shot and few-shot settings. All languages exhibit a significant deficiency compared to English, with variations in performance reflecting the availability of pre-training and fine-tuning data, emphasizing the need for LMs to be exposed to a broader range of linguistic and cultural variation during training.