 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the limits and opportunities of AI reviewers: Reviewing the reviews of Nature-family papers with 45 expert scientists
May 20, 2026With the advancement of AI capabilities, AI reviewers are beginning to be deployed in scientific peer review, yet their capability and credibility remain in question: many scientists simply view them as probabilistic systems without the expertise to evaluate research, while other researchers are more optimistic about their readiness without concrete evidence. Understanding what AI reviewers do well, where they fall short, and what challenges remain is essential. However, existing evaluations of AI reviewers have focused on whether their verdicts match human verdicts (e.g., score alignment, acceptance prediction), which is insufficient to characterize their capabilities and limits. In this paper, we close this gap through a large-scale expert annotation study, in which 45 domain scientists in Physical, Biological, and Health Sciences spent 469 hours rating 2,960 individual criticisms (each targeting one specific aspect of a paper) from human-written and AI-generated reviews of 82 Nature-family papers on correctness, significance, and sufficiency of evidence. On a composite of all three dimensions, a reviewing agent powered by GPT-5.2 scores above each paper's top-rated human reviewer (60.0% vs. 48.2%, p = 0.009), while all three AI reviewers (including Gemini 3.0 Pro and Claude Opus 4.5) exceed the lowest-rated human across every dimension. AI reviewers' accurate criticisms are also more often rated significant and well-evidenced, and surface a distinct 26% of issues no human raises. However, AI reviewers overlap far more than humans do (21% vs. 3% for cross-reviewer pairs), and exhibit 16 recurring weaknesses humans do not share, such as limited subfield knowledge, lack of long context management over multiple files, and overly critical stance on minor issues. Overall, our results position current AI reviewers as complements to, not substitutes for, human reviewers.
AgentIR: Reasoning-Aware Retrieval for Deep Research Agents
Mar 05, 2026Deep Research agents are rapidly emerging as primary consumers of modern retrieval systems. Unlike human users who issue and refine queries without documenting their intermediate thought processes, Deep Research agents generate explicit natural language reasoning before each search call, revealing rich intent and contextual information that existing retrievers entirely ignore. To exploit this overlooked signal, we introduce: (1) Reasoning-Aware Retrieval, a retrieval paradigm that jointly embeds the agent's reasoning trace alongside its query; and (2) DR-Synth, a data synthesis method that generates Deep Research retriever training data from standard QA datasets. We demonstrate that both components are independently effective, and their combination yields a trained embedding model, AgentIR-4B, with substantial gains. On the challenging BrowseComp-Plus benchmark, AgentIR-4B achieves 68\% accuracy with the open-weight agent Tongyi-DeepResearch, compared to 50\% with conventional embedding models twice its size, and 37\% with BM25. Code and data are available at: https://texttron.github.io/AgentIR/.
Olmo 3
Dec 15, 2025We introduce Olmo 3, a family of state-of-the-art, fully-open language models at the 7B and 32B parameter scales. Olmo 3 model construction targets long-context reasoning, function calling, coding, instruction following, general chat, and knowledge recall. This release includes the entire model flow, i.e., the full lifecycle of the family of models, including every stage, checkpoint, data point, and dependency used to build it. Our flagship model, Olmo 3 Think 32B, is the strongest fully-open thinking model released to-date.
Out of Style: RAG's Fragility to Linguistic Variation
Apr 11, 2025

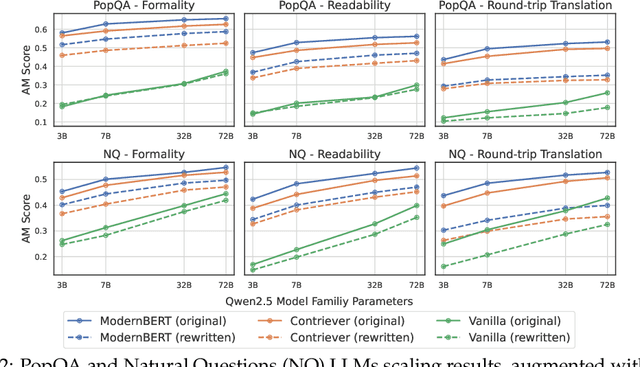
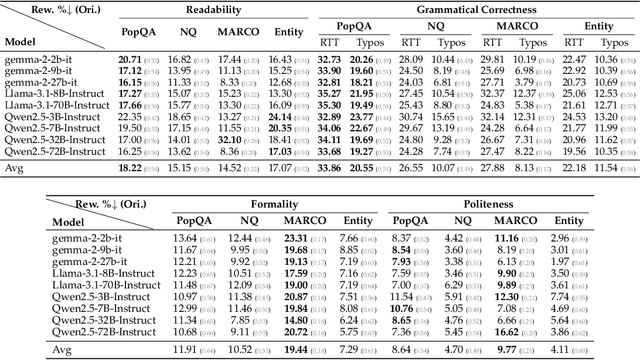
Despite the impressive performance of Retrieval-augmented Generation (RAG) systems across various NLP benchmarks, their robustness in handling real-world user-LLM interaction queries remains largely underexplored. This presents a critical gap for practical deployment, where user queries exhibit greater linguistic variations and can trigger cascading errors across interdependent RAG components. In this work, we systematically analyze how varying four linguistic dimensions (formality, readability, politeness, and grammatical correctness) impact RAG performance. We evaluate two retrieval models and nine LLMs, ranging from 3 to 72 billion parameters, across four information-seeking Question Answering (QA) datasets. Our results reveal that linguistic reformulations significantly impact both retrieval and generation stages, leading to a relative performance drop of up to 40.41% in Recall@5 scores for less formal queries and 38.86% in answer match scores for queries containing grammatical errors. Notably, RAG systems exhibit greater sensitivity to such variations compared to LLM-only generations, highlighting their vulnerability to error propagation due to linguistic shifts. These findings highlight the need for improved robustness techniques to enhance reliability in diverse user interactions.
OpenScholar: Synthesizing Scientific Literature with Retrieval-augmented LMs
Nov 21, 2024



Scientific progress depends on researchers' ability to synthesize the growing body of literature. Can large language models (LMs) assist scientists in this task? We introduce OpenScholar, a specialized retrieval-augmented LM that answers scientific queries by identifying relevant passages from 45 million open-access papers and synthesizing citation-backed responses. To evaluate OpenScholar, we develop ScholarQABench, the first large-scale multi-domain benchmark for literature search, comprising 2,967 expert-written queries and 208 long-form answers across computer science, physics, neuroscience, and biomedicine. On ScholarQABench, OpenScholar-8B outperforms GPT-4o by 5% and PaperQA2 by 7% in correctness, despite being a smaller, open model. While GPT4o hallucinates citations 78 to 90% of the time, OpenScholar achieves citation accuracy on par with human experts. OpenScholar's datastore, retriever, and self-feedback inference loop also improves off-the-shelf LMs: for instance, OpenScholar-GPT4o improves GPT-4o's correctness by 12%. In human evaluations, experts preferred OpenScholar-8B and OpenScholar-GPT4o responses over expert-written ones 51% and 70% of the time, respectively, compared to GPT4o's 32%. We open-source all of our code, models, datastore, data and a public demo.
Pangea: A Fully Open Multilingual Multimodal LLM for 39 Languages
Oct 21, 2024Despite recent advances in multimodal large language models (MLLMs), their development has predominantly focused on English- and western-centric datasets and tasks, leaving most of the world's languages and diverse cultural contexts underrepresented. This paper introduces Pangea, a multilingual multimodal LLM trained on PangeaIns, a diverse 6M instruction dataset spanning 39 languages. PangeaIns features: 1) high-quality English instructions, 2) carefully machine-translated instructions, and 3) culturally relevant multimodal tasks to ensure cross-cultural coverage. To rigorously assess models' capabilities, we introduce PangeaBench, a holistic evaluation suite encompassing 14 datasets covering 47 languages. Results show that Pangea significantly outperforms existing open-source models in multilingual settings and diverse cultural contexts. Ablation studies further reveal the importance of English data proportions, language popularity, and the number of multimodal training samples on overall performance. We fully open-source our data, code, and trained checkpoints, to facilitate the development of inclusive and robust multilingual MLLMs, promoting equity and accessibility across a broader linguistic and cultural spectrum.
CopyBench: Measuring Literal and Non-Literal Reproduction of Copyright-Protected Text in Language Model Generation
Jul 09, 2024



Evaluating the degree of reproduction of copyright-protected content by language models (LMs) is of significant interest to the AI and legal communities. Although both literal and non-literal similarities are considered by courts when assessing the degree of reproduction, prior research has focused only on literal similarities. To bridge this gap, we introduce CopyBench, a benchmark designed to measure both literal and non-literal copying in LM generations. Using copyrighted fiction books as text sources, we provide automatic evaluation protocols to assess literal and non-literal copying, balanced against the model utility in terms of the ability to recall facts from the copyrighted works and generate fluent completions. We find that, although literal copying is relatively rare, two types of non-literal copying -- event copying and character copying -- occur even in models as small as 7B parameters. Larger models demonstrate significantly more copying, with literal copying rates increasing from 0.2% to 10.5% and non-literal copying from 2.3% to 6.9% when comparing Llama3-8B and 70B models, respectively. We further evaluate the effectiveness of current strategies for mitigating copying and show that (1) training-time alignment can reduce literal copying but may increase non-literal copying, and (2) current inference-time mitigation methods primarily reduce literal but not non-literal copying.
CodeRAG-Bench: Can Retrieval Augment Code Generation?
Jun 20, 2024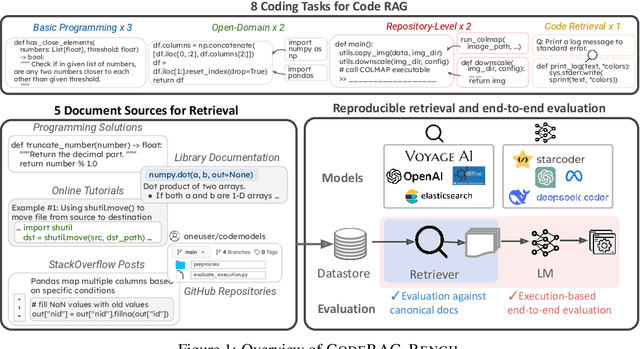
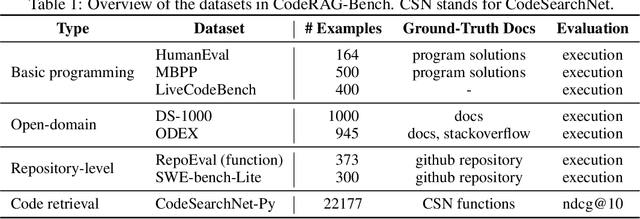
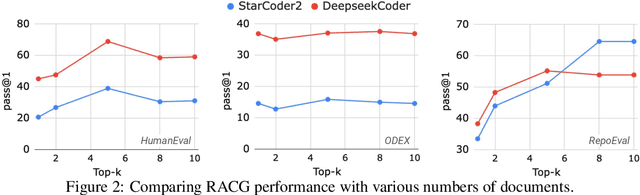
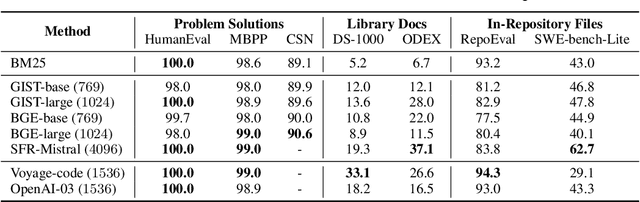
While language models (LMs) have proven remarkably adept at generating code, many programs are challenging for LMs to generate using their parametric knowledge alone. Providing external contexts such as library documentation can facilitate generating accurate and functional code. Despite the success of retrieval-augmented generation (RAG) in various text-oriented tasks, its potential for improving code generation remains under-explored. In this work, we conduct a systematic, large-scale analysis by asking: in what scenarios can retrieval benefit code generation models? and what challenges remain? We first curate a comprehensive evaluation benchmark, CodeRAG-Bench, encompassing three categories of code generation tasks, including basic programming, open-domain, and repository-level problems. We aggregate documents from five sources for models to retrieve contexts: competition solutions, online tutorials, library documentation, StackOverflow posts, and GitHub repositories. We examine top-performing models on CodeRAG-Bench by providing contexts retrieved from one or multiple sources. While notable gains are made in final code generation by retrieving high-quality contexts across various settings, our analysis reveals room for improvement -- current retrievers still struggle to fetch useful contexts especially with limited lexical overlap, and generators fail to improve with limited context lengths or abilities to integrate additional contexts. We hope CodeRAG-Bench serves as an effective testbed to encourage further development of advanced code-oriented RAG methods.
Reliable, Adaptable, and Attributable Language Models with Retrieval
Mar 05, 2024



Parametric language models (LMs), which are trained on vast amounts of web data, exhibit remarkable flexibility and capability. However, they still face practical challenges such as hallucinations, difficulty in adapting to new data distributions, and a lack of verifiability. In this position paper, we advocate for retrieval-augmented LMs to replace parametric LMs as the next generation of LMs. By incorporating large-scale datastores during inference, retrieval-augmented LMs can be more reliable, adaptable, and attributable. Despite their potential, retrieval-augmented LMs have yet to be widely adopted due to several obstacles: specifically, current retrieval-augmented LMs struggle to leverage helpful text beyond knowledge-intensive tasks such as question answering, have limited interaction between retrieval and LM components, and lack the infrastructure for scaling. To address these, we propose a roadmap for developing general-purpose retrieval-augmented LMs. This involves a reconsideration of datastores and retrievers, the exploration of pipelines with improved retriever-LM interaction, and significant investment in infrastructure for efficient training and inference.
Fine-grained Hallucination Detection and Editing for Language Models
Jan 17, 2024Large language models (LMs) are prone to generate diverse factually incorrect statements, which are widely called hallucinations. Current approaches predominantly focus on coarse-grained automatic hallucination detection or editing, overlooking nuanced error levels. In this paper, we propose a novel task -- automatic fine-grained hallucination detection -- and present a comprehensive taxonomy encompassing six hierarchically defined types of hallucination. To facilitate evaluation, we introduce a new benchmark that includes fine-grained human judgments on two LM outputs across various domains. Our analysis reveals that ChatGPT and Llama 2-Chat exhibit hallucinations in 60% and 75% of their outputs, respectively, and a majority of these hallucinations fall into categories that have been underexplored. As an initial step to address this, we train FAVA, a retrieval-augmented LM by carefully designing synthetic data generations to detect and correct fine-grained hallucinations. On our benchmark, our automatic and human evaluations show that FAVA significantly outperforms ChatGPT on fine-grained hallucination detection by a large margin though a large room for future improvement still exists. FAVA's suggested edits also improve the factuality of LM-generated text, resulting in 5-10% FActScore improvements.