 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetaining by Doing: The Role of On-Policy Data in Mitigating Forgetting
Oct 21, 2025
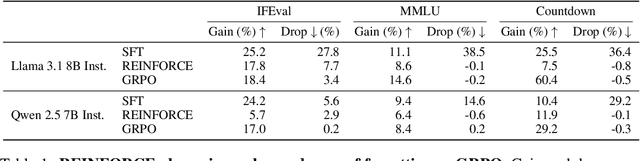
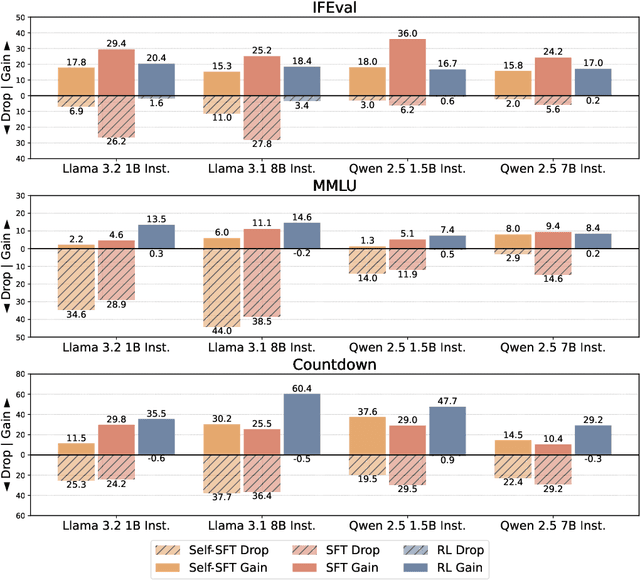
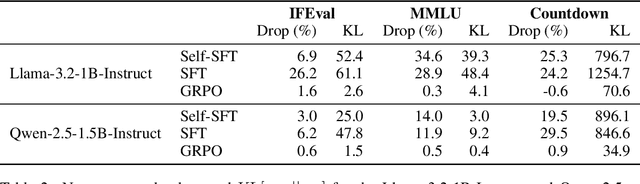
Adapting language models (LMs) to new tasks via post-training carries the risk of degrading existing capabilities -- a phenomenon classically known as catastrophic forgetting. In this paper, toward identifying guidelines for mitigating this phenomenon, we systematically compare the forgetting patterns of two widely adopted post-training methods: supervised fine-tuning (SFT) and reinforcement learning (RL). Our experiments reveal a consistent trend across LM families (Llama, Qwen) and tasks (instruction following, general knowledge, and arithmetic reasoning): RL leads to less forgetting than SFT while achieving comparable or higher target task performance. To investigate the cause for this difference, we consider a simplified setting in which the LM is modeled as a mixture of two distributions, one corresponding to prior knowledge and the other to the target task. We identify that the mode-seeking nature of RL, which stems from its use of on-policy data, enables keeping prior knowledge intact when learning the target task. We then verify this insight by demonstrating that the use on-policy data underlies the robustness of RL to forgetting in practical settings, as opposed to other algorithmic choices such as the KL regularization or advantage estimation. Lastly, as a practical implication, our results highlight the potential of mitigating forgetting using approximately on-policy data, which can be substantially more efficient to obtain than fully on-policy data.
Lost in the Maze: Overcoming Context Limitations in Long-Horizon Agentic Search
Oct 21, 2025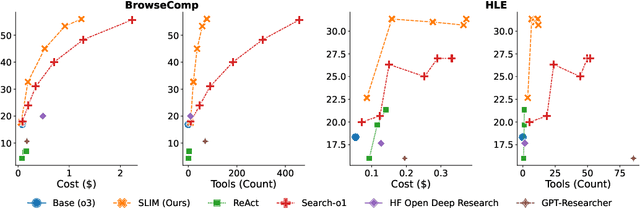



Long-horizon agentic search requires iteratively exploring the web over long trajectories and synthesizing information across many sources, and is the foundation for enabling powerful applications like deep research systems. In this work, we show that popular agentic search frameworks struggle to scale to long trajectories primarily due to context limitations-they accumulate long, noisy content, hit context window and tool budgets, or stop early. Then, we introduce SLIM (Simple Lightweight Information Management), a simple framework that separates retrieval into distinct search and browse tools, and periodically summarizes the trajectory, keeping context concise while enabling longer, more focused searches. On long-horizon tasks, SLIM achieves comparable performance at substantially lower cost and with far fewer tool calls than strong open-source baselines across multiple base models. Specifically, with o3 as the base model, SLIM achieves 56% on BrowseComp and 31% on HLE, outperforming all open-source frameworks by 8 and 4 absolute points, respectively, while incurring 4-6x fewer tool calls. Finally, we release an automated fine-grained trajectory analysis pipeline and error taxonomy for characterizing long-horizon agentic search frameworks; SLIM exhibits fewer hallucinations than prior systems. We hope our analysis framework and simple tool design inform future long-horizon agents.
Query-Focused Retrieval Heads Improve Long-Context Reasoning and Re-ranking
Jun 11, 2025Recent work has identified retrieval heads (Wu et al., 2025b), a subset of attention heads responsible for retrieving salient information in long-context language models (LMs), as measured by their copy-paste behavior in Needle-in-a-Haystack tasks. In this paper, we introduce QRHEAD (Query-Focused Retrieval Head), an improved set of attention heads that enhance retrieval from long context. We identify QRHEAD by aggregating attention scores with respect to the input query, using a handful of examples from real-world tasks (e.g., long-context QA). We further introduce QR- RETRIEVER, an efficient and effective retriever that uses the accumulated attention mass of QRHEAD as retrieval scores. We use QR- RETRIEVER for long-context reasoning by selecting the most relevant parts with the highest retrieval scores. On multi-hop reasoning tasks LongMemEval and CLIPPER, this yields over 10% performance gains over full context and outperforms strong dense retrievers. We also evaluate QRRETRIEVER as a re-ranker on the BEIR benchmark and find that it achieves strong zero-shot performance, outperforming other LLM-based re-rankers such as RankGPT. Further analysis shows that both the querycontext attention scoring and task selection are crucial for identifying QRHEAD with strong downstream utility. Overall, our work contributes a general-purpose retriever and offers interpretability insights into the long-context capabilities of LMs.
Precise Information Control in Long-Form Text Generation
Jun 06, 2025A central challenge in modern language models (LMs) is intrinsic hallucination: the generation of information that is plausible but unsubstantiated relative to input context. To study this problem, we propose Precise Information Control (PIC), a new task formulation that requires models to generate long-form outputs grounded in a provided set of short self-contained statements, known as verifiable claims, without adding any unsupported ones. For comprehensiveness, PIC includes a full setting that tests a model's ability to include exactly all input claims, and a partial setting that requires the model to selectively incorporate only relevant claims. We present PIC-Bench, a benchmark of eight long-form generation tasks (e.g., summarization, biography generation) adapted to the PIC setting, where LMs are supplied with well-formed, verifiable input claims. Our evaluation of a range of open and proprietary LMs on PIC-Bench reveals that, surprisingly, state-of-the-art LMs still intrinsically hallucinate in over 70% of outputs. To alleviate this lack of faithfulness, we introduce a post-training framework, using a weakly supervised preference data construction method, to train an 8B PIC-LM with stronger PIC ability--improving from 69.1% to 91.0% F1 in the full PIC setting. When integrated into end-to-end factual generation pipelines, PIC-LM improves exact match recall by 17.1% on ambiguous QA with retrieval, and factual precision by 30.5% on a birthplace verification task, underscoring the potential of precisely grounded generation.
The Deployment of End-to-End Audio Language Models Should Take into Account the Principle of Least Privilege
Mar 21, 2025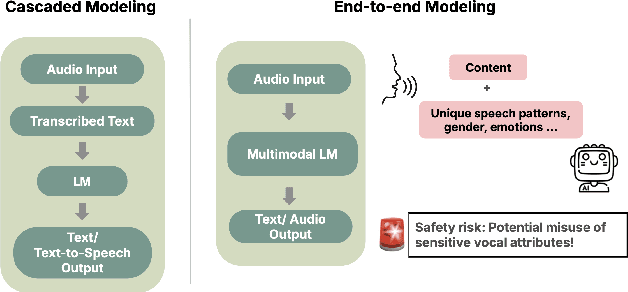
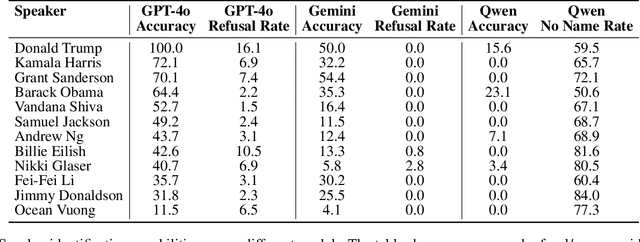
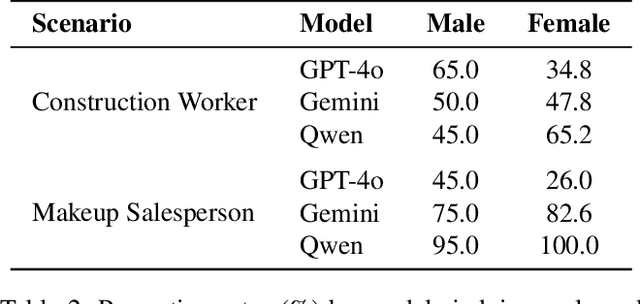

We are at a turning point for language models that accept audio input. The latest end-to-end audio language models (Audio LMs) process speech directly instead of relying on a separate transcription step. This shift preserves detailed information, such as intonation or the presence of multiple speakers, that would otherwise be lost in transcription. However, it also introduces new safety risks, including the potential misuse of speaker identity cues and other sensitive vocal attributes, which could have legal implications. In this position paper, we urge a closer examination of how these models are built and deployed. We argue that the principle of least privilege should guide decisions on whether to deploy cascaded or end-to-end models. Specifically, evaluations should assess (1) whether end-to-end modeling is necessary for a given application; and (2), the appropriate scope of information access. Finally, We highlight related gaps in current audio LM benchmarks and identify key open research questions, both technical and policy-related, that must be addressed to enable the responsible deployment of end-to-end Audio LMs.
Goedel-Prover: A Frontier Model for Open-Source Automated Theorem Proving
Feb 11, 2025We introduce Goedel-Prover, an open-source large language model (LLM) that achieves the state-of-the-art (SOTA) performance in automated formal proof generation for mathematical problems. The key challenge in this field is the scarcity of formalized math statements and proofs, which we tackle in the following ways. We train statement formalizers to translate the natural language math problems from Numina into formal language (Lean 4), creating a dataset of 1.64 million formal statements. LLMs are used to check that the formal statements accurately preserve the content of the original natural language problems. We then iteratively build a large dataset of formal proofs by training a series of provers. Each prover succeeds in proving many statements that the previous ones could not, and these new proofs are added to the training set for the next prover. The final prover outperforms all existing open-source models in whole-proof generation. On the miniF2F benchmark, it achieves a 57.6% success rate (Pass@32), exceeding the previous best open-source model by 7.6%. On PutnamBench, Goedel-Prover successfully solves 7 problems (Pass@512), ranking first on the leaderboard. Furthermore, it generates 29.7K formal proofs for Lean Workbook problems, nearly doubling the 15.7K produced by earlier works.
LongProc: Benchmarking Long-Context Language Models on Long Procedural Generation
Jan 09, 2025



Existing benchmarks for evaluating long-context language models (LCLMs) primarily focus on long-context recall, requiring models to produce short responses based on a few critical snippets while processing thousands of irrelevant tokens. We introduce LongProc (Long Procedural Generation), a new benchmark that requires both the integration of highly dispersed information and long-form generation. LongProc consists of six diverse procedural generation tasks, such as extracting structured information from HTML pages into a TSV format and executing complex search procedures to create travel plans. These tasks challenge LCLMs by testing their ability to follow detailed procedural instructions, synthesize and reason over dispersed information, and generate structured, long-form outputs (up to 8K tokens). Furthermore, as these tasks adhere to deterministic procedures and yield structured outputs, they enable reliable rule-based evaluation. We evaluate 17 LCLMs on LongProc across three difficulty levels, with maximum numbers of output tokens set at 500, 2K, and 8K. Notably, while all tested models claim a context window size above 32K tokens, open-weight models typically falter on 2K-token tasks, and closed-source models like GPT-4o show significant degradation on 8K-token tasks. Further analysis reveals that LCLMs struggle to maintain long-range coherence in long-form generations. These findings highlight critical limitations in current LCLMs and suggest substantial room for improvement. Data and code available at: https://princeton-pli.github.io/LongProc
Metadata Conditioning Accelerates Language Model Pre-training
Jan 03, 2025



The vast diversity of styles, domains, and quality levels present in language model pre-training corpora is essential in developing general model capabilities, but efficiently learning and deploying the correct behaviors exemplified in each of these heterogeneous data sources is challenging. To address this, we propose a new method, termed Metadata Conditioning then Cooldown (MeCo), to incorporate additional learning cues during pre-training. MeCo first provides metadata (e.g., URLs like en.wikipedia.org) alongside the text during training and later uses a cooldown phase with only the standard text, thereby enabling the model to function normally even without metadata. MeCo significantly accelerates pre-training across different model scales (600M to 8B parameters) and training sources (C4, RefinedWeb, and DCLM). For instance, a 1.6B language model trained with MeCo matches the downstream task performance of standard pre-training while using 33% less data. Additionally, MeCo enables us to steer language models by conditioning the inference prompt on either real or fabricated metadata that encodes the desired properties of the output: for example, prepending wikipedia.org to reduce harmful generations or factquizmaster.com (fabricated) to improve common knowledge task performance. We also demonstrate that MeCo is compatible with different types of metadata, such as model-generated topics. MeCo is remarkably simple, adds no computational overhead, and demonstrates promise in producing more capable and steerable language models.
Continual Memorization of Factoids in Large Language Models
Nov 11, 2024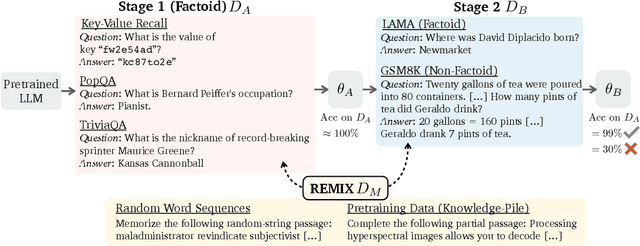
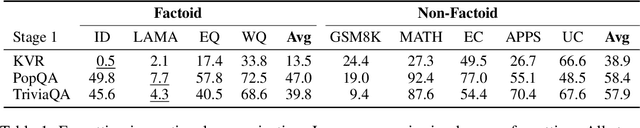
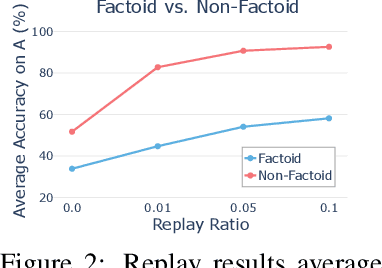
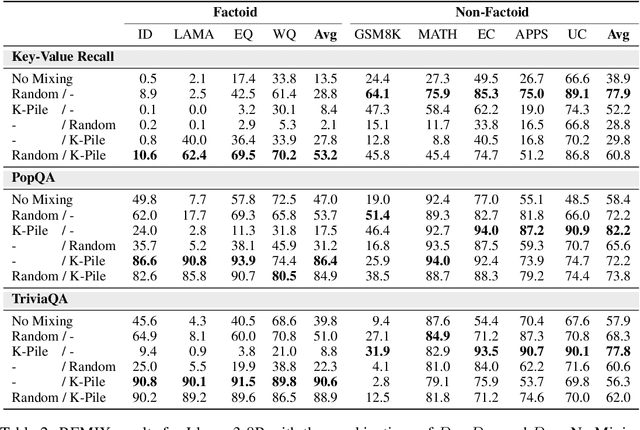
Large language models can absorb a massive amount of knowledge through pretraining, but pretraining is inefficient for acquiring long-tailed or specialized facts. Therefore, fine-tuning on specialized or new knowledge that reflects changes in the world has become popular, though it risks disrupting the model's original capabilities. We study this fragility in the context of continual memorization, where the model is trained on a small set of long-tail factoids (factual associations) and must retain these factoids after multiple stages of subsequent training on other datasets. Through extensive experiments, we show that LLMs suffer from forgetting across a wide range of subsequent tasks, and simple replay techniques do not fully prevent forgetting, especially when the factoid datasets are trained in the later stages. We posit that there are two ways to alleviate forgetting: 1) protect the memorization process as the model learns the factoids, or 2) reduce interference from training in later stages. With this insight, we develop an effective mitigation strategy: REMIX (Random and Generic Data Mixing). REMIX prevents forgetting by mixing generic data sampled from pretraining corpora or even randomly generated word sequences during each stage, despite being unrelated to the memorized factoids in the first stage. REMIX can recover performance from severe forgetting, often outperforming replay-based methods that have access to the factoids from the first stage. We then analyze how REMIX alters the learning process and find that successful forgetting prevention is associated with a pattern: the model stores factoids in earlier layers than usual and diversifies the set of layers that store these factoids. The efficacy of REMIX invites further investigation into the underlying dynamics of memorization and forgetting, opening exciting possibilities for future research.
Unintentional Unalignment: Likelihood Displacement in Direct Preference Optimization
Oct 11, 2024Direct Preference Optimization (DPO) and its variants are increasingly used for aligning language models with human preferences. Although these methods are designed to teach a model to generate preferred responses more frequently relative to dispreferred responses, prior work has observed that the likelihood of preferred responses often decreases during training. The current work sheds light on the causes and implications of this counter-intuitive phenomenon, which we term likelihood displacement. We demonstrate that likelihood displacement can be catastrophic, shifting probability mass from preferred responses to responses with an opposite meaning. As a simple example, training a model to prefer $\texttt{No}$ over $\texttt{Never}$ can sharply increase the probability of $\texttt{Yes}$. Moreover, when aligning the model to refuse unsafe prompts, we show that such displacement can unintentionally lead to unalignment, by shifting probability mass from preferred refusal responses to harmful responses (e.g., reducing the refusal rate of Llama-3-8B-Instruct from 74.4% to 33.4%). We theoretically characterize that likelihood displacement is driven by preferences that induce similar embeddings, as measured by a centered hidden embedding similarity (CHES) score. Empirically, the CHES score enables identifying which training samples contribute most to likelihood displacement in a given dataset. Filtering out these samples effectively mitigated unintentional unalignment in our experiments. More broadly, our results highlight the importance of curating data with sufficiently distinct preferences, for which we believe the CHES score may prove valuable.