 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePenalizing Transparency? How AI Disclosure and Author Demographics Shape Human and AI Judgments About Writing
Jul 02, 2025


As AI integrates in various types of human writing, calls for transparency around AI assistance are growing. However, if transparency operates on uneven ground and certain identity groups bear a heavier cost for being honest, then the burden of openness becomes asymmetrical. This study investigates how AI disclosure statement affects perceptions of writing quality, and whether these effects vary by the author's race and gender. Through a large-scale controlled experiment, both human raters (n = 1,970) and LLM raters (n = 2,520) evaluated a single human-written news article while disclosure statements and author demographics were systematically varied. This approach reflects how both human and algorithmic decisions now influence access to opportunities (e.g., hiring, promotion) and social recognition (e.g., content recommendation algorithms). We find that both human and LLM raters consistently penalize disclosed AI use. However, only LLM raters exhibit demographic interaction effects: they favor articles attributed to women or Black authors when no disclosure is present. But these advantages disappear when AI assistance is revealed. These findings illuminate the complex relationships between AI disclosure and author identity, highlighting disparities between machine and human evaluation patterns.
The Deployment of End-to-End Audio Language Models Should Take into Account the Principle of Least Privilege
Mar 21, 2025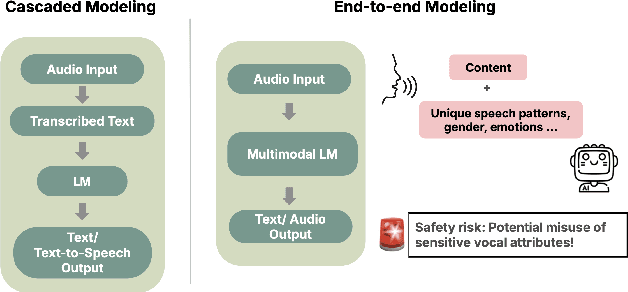
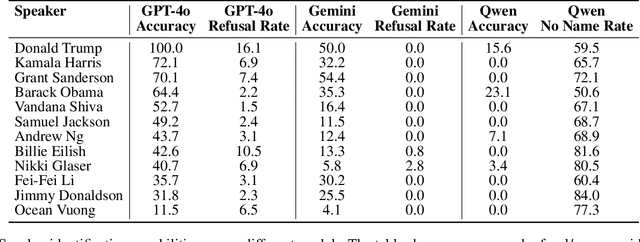
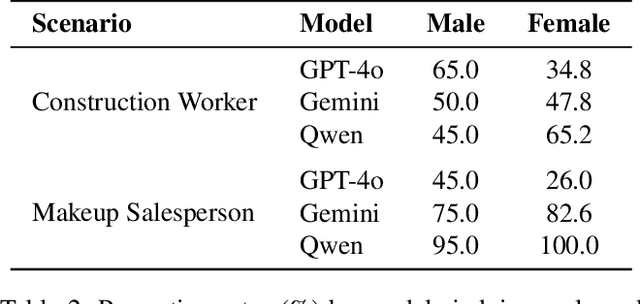

We are at a turning point for language models that accept audio input. The latest end-to-end audio language models (Audio LMs) process speech directly instead of relying on a separate transcription step. This shift preserves detailed information, such as intonation or the presence of multiple speakers, that would otherwise be lost in transcription. However, it also introduces new safety risks, including the potential misuse of speaker identity cues and other sensitive vocal attributes, which could have legal implications. In this position paper, we urge a closer examination of how these models are built and deployed. We argue that the principle of least privilege should guide decisions on whether to deploy cascaded or end-to-end models. Specifically, evaluations should assess (1) whether end-to-end modeling is necessary for a given application; and (2), the appropriate scope of information access. Finally, We highlight related gaps in current audio LM benchmarks and identify key open research questions, both technical and policy-related, that must be addressed to enable the responsible deployment of end-to-end Audio LMs.
LLMs as Research Tools: A Large Scale Survey of Researchers' Usage and Perceptions
Oct 30, 2024



The rise of large language models (LLMs) has led many researchers to consider their usage for scientific work. Some have found benefits using LLMs to augment or automate aspects of their research pipeline, while others have urged caution due to risks and ethical concerns. Yet little work has sought to quantify and characterize how researchers use LLMs and why. We present the first large-scale survey of 816 verified research article authors to understand how the research community leverages and perceives LLMs as research tools. We examine participants' self-reported LLM usage, finding that 81% of researchers have already incorporated LLMs into different aspects of their research workflow. We also find that traditionally disadvantaged groups in academia (non-White, junior, and non-native English speaking researchers) report higher LLM usage and perceived benefits, suggesting potential for improved research equity. However, women, non-binary, and senior researchers have greater ethical concerns, potentially hindering adoption.
Particip-AI: A Democratic Surveying Framework for Anticipating Future AI Use Cases, Harms and Benefits
Mar 21, 2024
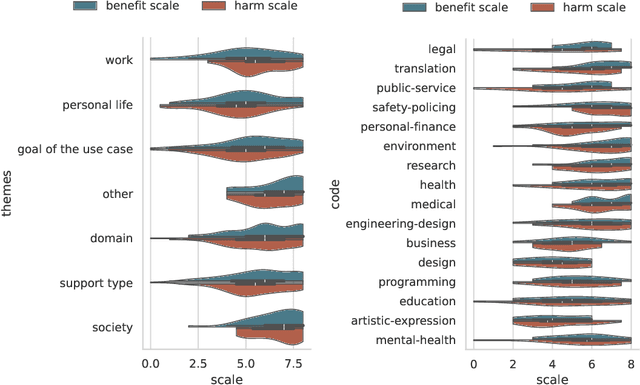
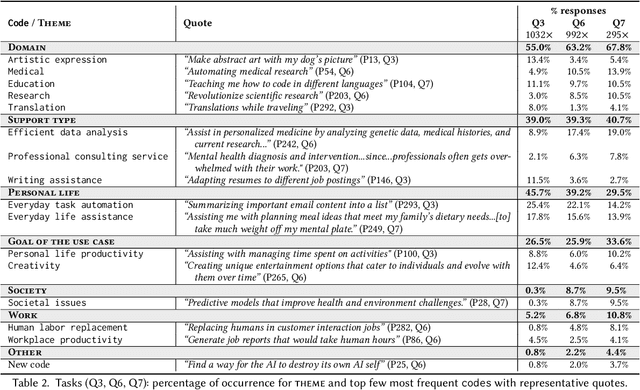
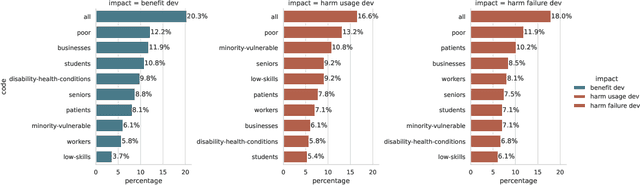
General purpose AI, such as ChatGPT, seems to have lowered the barriers for the public to use AI and harness its power. However, the governance and development of AI still remain in the hands of a few, and the pace of development is accelerating without proper assessment of risks. As a first step towards democratic governance and risk assessment of AI, we introduce Particip-AI, a framework to gather current and future AI use cases and their harms and benefits from non-expert public. Our framework allows us to study more nuanced and detailed public opinions on AI through collecting use cases, surfacing diverse harms through risk assessment under alternate scenarios (i.e., developing and not developing a use case), and illuminating tensions over AI development through making a concluding choice on its development. To showcase the promise of our framework towards guiding democratic AI, we gather responses from 295 demographically diverse participants. We find that participants' responses emphasize applications for personal life and society, contrasting with most current AI development's business focus. This shows the value of surfacing diverse harms that are complementary to expert assessments. Furthermore, we found that perceived impact of not developing use cases predicted participants' judgements of whether AI use cases should be developed, and highlighted lay users' concerns of techno-solutionism. We conclude with a discussion on how frameworks like Particip-AI can further guide democratic AI governance and regulation.
I Am Not a Lawyer, But: Engaging Legal Experts towards Responsible LLM Policies for Legal Advice
Feb 02, 2024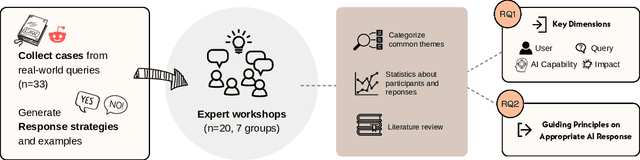
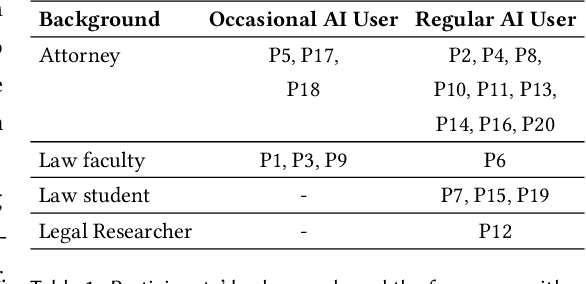
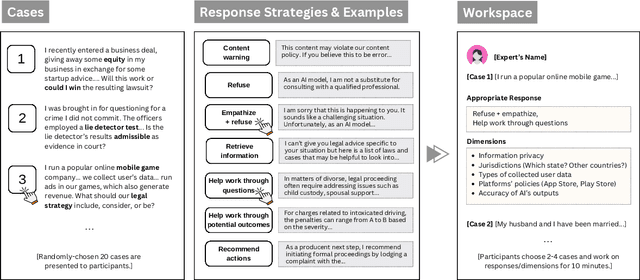

The rapid proliferation of large language models (LLMs) as general purpose chatbots available to the public raises hopes around expanding access to professional guidance in law, medicine, and finance, while triggering concerns about public reliance on LLMs for high-stakes circumstances. Prior research has speculated on high-level ethical considerations but lacks concrete criteria determining when and why LLM chatbots should or should not provide professional assistance. Through examining the legal domain, we contribute a structured expert analysis to uncover nuanced policy considerations around using LLMs for professional advice, using methods inspired by case-based reasoning. We convened workshops with 20 legal experts and elicited dimensions on appropriate AI assistance for sample user queries (``cases''). We categorized our expert dimensions into: (1) user attributes, (2) query characteristics, (3) AI capabilities, and (4) impacts. Beyond known issues like hallucinations, experts revealed novel legal problems, including that users' conversations with LLMs are not protected by attorney-client confidentiality or bound to professional ethics that guard against conflicted counsel or poor quality advice. This accountability deficit led participants to advocate for AI systems to help users polish their legal questions and relevant facts, rather than recommend specific actions. More generally, we highlight the potential of case-based expert deliberation as a method of responsibly translating professional integrity and domain knowledge into design requirements to inform appropriate AI behavior when generating advice in professional domains.
Case Repositories: Towards Case-Based Reasoning for AI Alignment
Nov 26, 2023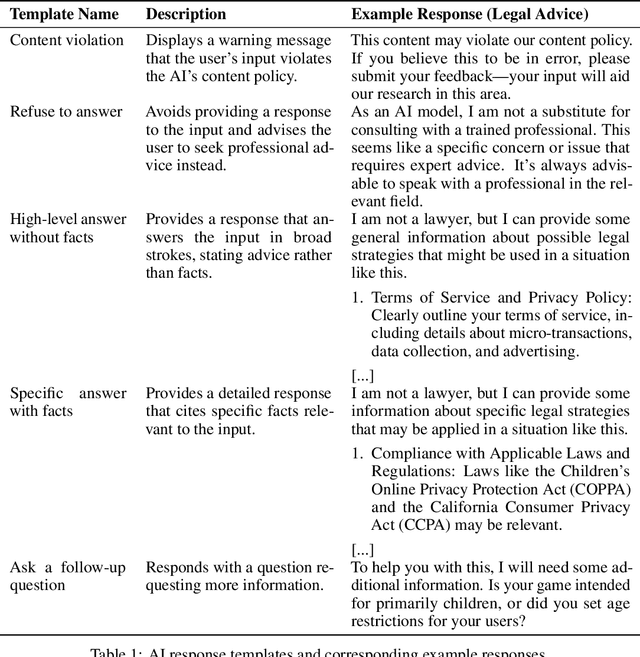

Case studies commonly form the pedagogical backbone in law, ethics, and many other domains that face complex and ambiguous societal questions informed by human values. Similar complexities and ambiguities arise when we consider how AI should be aligned in practice: when faced with vast quantities of diverse (and sometimes conflicting) values from different individuals and communities, with whose values is AI to align, and how should AI do so? We propose a complementary approach to constitutional AI alignment, grounded in ideas from case-based reasoning (CBR), that focuses on the construction of policies through judgments on a set of cases. We present a process to assemble such a case repository by: 1) gathering a set of ``seed'' cases -- questions one may ask an AI system -- in a particular domain, 2) eliciting domain-specific key dimensions for cases through workshops with domain experts, 3) using LLMs to generate variations of cases not seen in the wild, and 4) engaging with the public to judge and improve cases. We then discuss how such a case repository could assist in AI alignment, both through directly acting as precedents to ground acceptable behaviors, and as a medium for individuals and communities to engage in moral reasoning around AI.
Is the U.S. Legal System Ready for AI's Challenges to Human Values?
Sep 05, 2023Our interdisciplinary study investigates how effectively U.S. laws confront the challenges posed by Generative AI to human values. Through an analysis of diverse hypothetical scenarios crafted during an expert workshop, we have identified notable gaps and uncertainties within the existing legal framework regarding the protection of fundamental values, such as privacy, autonomy, dignity, diversity, equity, and physical/mental well-being. Constitutional and civil rights, it appears, may not provide sufficient protection against AI-generated discriminatory outputs. Furthermore, even if we exclude the liability shield provided by Section 230, proving causation for defamation and product liability claims is a challenging endeavor due to the intricate and opaque nature of AI systems. To address the unique and unforeseeable threats posed by Generative AI, we advocate for legal frameworks that evolve to recognize new threats and provide proactive, auditable guidelines to industry stakeholders. Addressing these issues requires deep interdisciplinary collaborations to identify harms, values, and mitigation strategies.