 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Language Models Sensitive to Morally Irrelevant Distractors?
Feb 10, 2026With the rapid development and uptake of large language models (LLMs) across high-stakes settings, it is increasingly important to ensure that LLMs behave in ways that align with human values. Existing moral benchmarks prompt LLMs with value statements, moral scenarios, or psychological questionnaires, with the implicit underlying assumption that LLMs report somewhat stable moral preferences. However, moral psychology research has shown that human moral judgements are sensitive to morally irrelevant situational factors, such as smelling cinnamon rolls or the level of ambient noise, thereby challenging moral theories that assume the stability of human moral judgements. Here, we draw inspiration from this "situationist" view of moral psychology to evaluate whether LLMs exhibit similar cognitive moral biases to humans. We curate a novel multimodal dataset of 60 "moral distractors" from existing psychological datasets of emotionally-valenced images and narratives which have no moral relevance to the situation presented. After injecting these distractors into existing moral benchmarks to measure their effects on LLM responses, we find that moral distractors can shift the moral judgements of LLMs by over 30% even in low-ambiguity scenarios, highlighting the need for more contextual moral evaluations and more nuanced cognitive moral modeling of LLMs.
Penalizing Transparency? How AI Disclosure and Author Demographics Shape Human and AI Judgments About Writing
Jul 02, 2025


As AI integrates in various types of human writing, calls for transparency around AI assistance are growing. However, if transparency operates on uneven ground and certain identity groups bear a heavier cost for being honest, then the burden of openness becomes asymmetrical. This study investigates how AI disclosure statement affects perceptions of writing quality, and whether these effects vary by the author's race and gender. Through a large-scale controlled experiment, both human raters (n = 1,970) and LLM raters (n = 2,520) evaluated a single human-written news article while disclosure statements and author demographics were systematically varied. This approach reflects how both human and algorithmic decisions now influence access to opportunities (e.g., hiring, promotion) and social recognition (e.g., content recommendation algorithms). We find that both human and LLM raters consistently penalize disclosed AI use. However, only LLM raters exhibit demographic interaction effects: they favor articles attributed to women or Black authors when no disclosure is present. But these advantages disappear when AI assistance is revealed. These findings illuminate the complex relationships between AI disclosure and author identity, highlighting disparities between machine and human evaluation patterns.
Levels of Autonomy for AI Agents
Jun 14, 2025Autonomy is a double-edged sword for AI agents, simultaneously unlocking transformative possibilities and serious risks. How can agent developers calibrate the appropriate levels of autonomy at which their agents should operate? We argue that an agent's level of autonomy can be treated as a deliberate design decision, separate from its capability and operational environment. In this work, we define five levels of escalating agent autonomy, characterized by the roles a user can take when interacting with an agent: operator, collaborator, consultant, approver, and observer. Within each level, we describe the ways by which a user can exert control over the agent and open questions for how to design the nature of user-agent interaction. We then highlight a potential application of our framework towards AI autonomy certificates to govern agent behavior in single- and multi-agent systems. We conclude by proposing early ideas for evaluating agents' autonomy. Our work aims to contribute meaningful, practical steps towards responsibly deployed and useful AI agents in the real world.
Cocoa: Co-Planning and Co-Execution with AI Agents
Dec 14, 2024



We present Cocoa, a system that implements a novel interaction design pattern -- interactive plans -- for users to collaborate with an AI agent on complex, multi-step tasks in a document editor. Cocoa harmonizes human and AI efforts and enables flexible delegation of agency through two actions: Co-planning (where users collaboratively compose a plan of action with the agent) and Co-execution (where users collaboratively execute plan steps with the agent). Using scientific research as a sample domain, we motivate the design of Cocoa through a formative study with 9 researchers while also drawing inspiration from the design of computational notebooks. We evaluate Cocoa through a user study with 16 researchers and find that when compared to a strong chat baseline, Cocoa improved agent steerability without sacrificing ease of use. A deeper investigation of the general utility of both systems uncovered insights into usage contexts where interactive plans may be more appropriate than chat, and vice versa. Our work surfaces numerous practical implications and paves new paths for interactive interfaces that foster more effective collaboration between humans and agentic AI systems.
SPICA: Retrieving Scenarios for Pluralistic In-Context Alignment
Nov 16, 2024



Alignment of large language models (LLMs) to societal values should account for pluralistic values from diverse groups. One technique uses in-context learning for inference-time alignment, but only considers similarity when drawing few-shot examples, not accounting for cross-group differences in value prioritization. We propose SPICA, a framework for pluralistic alignment that accounts for group-level differences during in-context example retrieval. SPICA introduces three designs to facilitate pluralistic alignment: scenario banks, group-informed metrics, and in-context alignment prompts. From an evaluation of SPICA on an alignment task collecting inputs from four demographic groups ($n = 544$), our metrics retrieve in-context examples that more closely match observed preferences, with the best prompt configuration using multiple contrastive responses to demonstrate examples. In an end-to-end evaluation ($n = 80$), we observe that SPICA-aligned models are higher rated than a baseline similarity-only retrieval approach, with groups seeing up to a +0.16 point improvement on a 5 point scale. Additionally, gains from SPICA were more uniform, with all groups benefiting from alignment rather than only some. Finally, we find that while a group-agnostic approach can effectively align to aggregated values, it is not most suited for aligning to divergent groups.
Chain of Alignment: Integrating Public Will with Expert Intelligence for Language Model Alignment
Nov 15, 2024



We introduce a method to measure the alignment between public will and language model (LM) behavior that can be applied to fine-tuning, online oversight, and pre-release safety checks. Our `chain of alignment' (CoA) approach produces a rule based reward (RBR) by creating model behavior $\textit{rules}$ aligned to normative $\textit{objectives}$ aligned to $\textit{public will}$. This factoring enables a nonexpert public to directly specify their will through the normative objectives, while expert intelligence is used to figure out rules entailing model behavior that best achieves those objectives. We validate our approach by applying it across three different domains of LM prompts related to mental health. We demonstrate a public input process built on collective dialogues and bridging-based ranking that reliably produces normative objectives supported by at least $96\% \pm 2\%$ of the US public. We then show that rules developed by mental health experts to achieve those objectives enable a RBR that evaluates an LM response's alignment with the objectives similarly to human experts (Pearson's $r=0.841$, $AUC=0.964$). By measuring alignment with objectives that have near unanimous public support, these CoA RBRs provide an approximate measure of alignment between LM behavior and public will.
LLMs as Research Tools: A Large Scale Survey of Researchers' Usage and Perceptions
Oct 30, 2024



The rise of large language models (LLMs) has led many researchers to consider their usage for scientific work. Some have found benefits using LLMs to augment or automate aspects of their research pipeline, while others have urged caution due to risks and ethical concerns. Yet little work has sought to quantify and characterize how researchers use LLMs and why. We present the first large-scale survey of 816 verified research article authors to understand how the research community leverages and perceives LLMs as research tools. We examine participants' self-reported LLM usage, finding that 81% of researchers have already incorporated LLMs into different aspects of their research workflow. We also find that traditionally disadvantaged groups in academia (non-White, junior, and non-native English speaking researchers) report higher LLM usage and perceived benefits, suggesting potential for improved research equity. However, women, non-binary, and senior researchers have greater ethical concerns, potentially hindering adoption.
Language Models as Critical Thinking Tools: A Case Study of Philosophers
Apr 06, 2024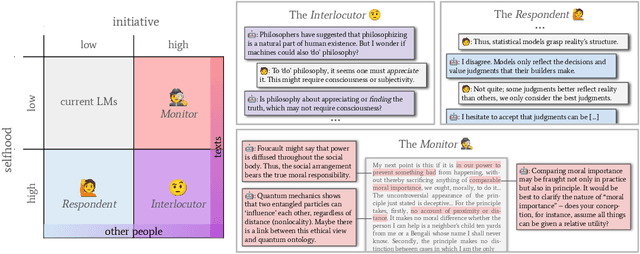
Current work in language models (LMs) helps us speed up or even skip thinking by accelerating and automating cognitive work. But can LMs help us with critical thinking -- thinking in deeper, more reflective ways which challenge assumptions, clarify ideas, and engineer new concepts? We treat philosophy as a case study in critical thinking, and interview 21 professional philosophers about how they engage in critical thinking and on their experiences with LMs. We find that philosophers do not find LMs to be useful because they lack a sense of selfhood (memory, beliefs, consistency) and initiative (curiosity, proactivity). We propose the selfhood-initiative model for critical thinking tools to characterize this gap. Using the model, we formulate three roles LMs could play as critical thinking tools: the Interlocutor, the Monitor, and the Respondent. We hope that our work inspires LM researchers to further develop LMs as critical thinking tools and philosophers and other 'critical thinkers' to imagine intellectually substantive uses of LMs.
Correcting misinformation on social media with a large language model
Mar 17, 2024


Misinformation undermines public trust in science and democracy, particularly on social media where inaccuracies can spread rapidly. Experts and laypeople have shown to be effective in correcting misinformation by manually identifying and explaining inaccuracies. Nevertheless, this approach is difficult to scale, a concern as technologies like large language models (LLMs) make misinformation easier to produce. LLMs also have versatile capabilities that could accelerate misinformation correction; however, they struggle due to a lack of recent information, a tendency to produce plausible but false content and references, and limitations in addressing multimodal information. To address these issues, we propose MUSE, an LLM augmented with access to and credibility evaluation of up-to-date information. By retrieving contextual evidence and refutations, MUSE can provide accurate and trustworthy explanations and references. It also describes visuals and conducts multimodal searches for correcting multimodal misinformation. We recruit fact-checking and journalism experts to evaluate corrections to real social media posts across 13 dimensions, ranging from the factuality of explanation to the relevance of references. The results demonstrate MUSE's ability to correct misinformation promptly after appearing on social media; overall, MUSE outperforms GPT-4 by 37% and even high-quality corrections from laypeople by 29%. This work underscores the potential of LLMs to combat real-world misinformation effectively and efficiently.
I Am Not a Lawyer, But: Engaging Legal Experts towards Responsible LLM Policies for Legal Advice
Feb 02, 2024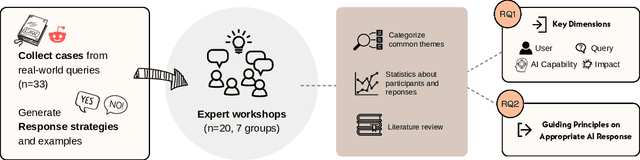
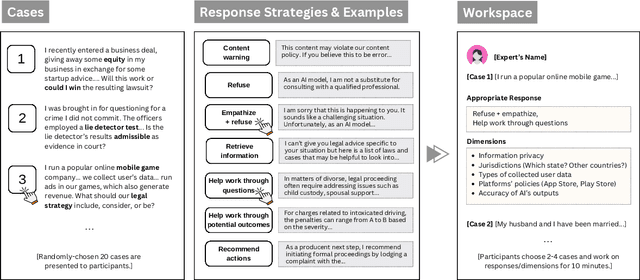

The rapid proliferation of large language models (LLMs) as general purpose chatbots available to the public raises hopes around expanding access to professional guidance in law, medicine, and finance, while triggering concerns about public reliance on LLMs for high-stakes circumstances. Prior research has speculated on high-level ethical considerations but lacks concrete criteria determining when and why LLM chatbots should or should not provide professional assistance. Through examining the legal domain, we contribute a structured expert analysis to uncover nuanced policy considerations around using LLMs for professional advice, using methods inspired by case-based reasoning. We convened workshops with 20 legal experts and elicited dimensions on appropriate AI assistance for sample user queries (``cases''). We categorized our expert dimensions into: (1) user attributes, (2) query characteristics, (3) AI capabilities, and (4) impacts. Beyond known issues like hallucinations, experts revealed novel legal problems, including that users' conversations with LLMs are not protected by attorney-client confidentiality or bound to professional ethics that guard against conflicted counsel or poor quality advice. This accountability deficit led participants to advocate for AI systems to help users polish their legal questions and relevant facts, rather than recommend specific actions. More generally, we highlight the potential of case-based expert deliberation as a method of responsibly translating professional integrity and domain knowledge into design requirements to inform appropriate AI behavior when generating advice in professional domains.