 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCTRL-Rec: Controlling Recommender Systems With Natural Language
Oct 14, 2025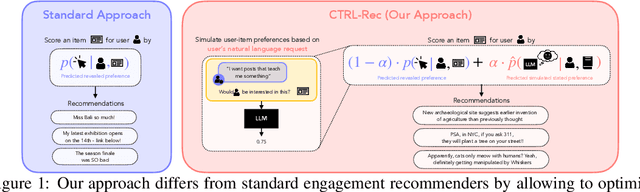



When users are dissatisfied with recommendations from a recommender system, they often lack fine-grained controls for changing them. Large language models (LLMs) offer a solution by allowing users to guide their recommendations through natural language requests (e.g., "I want to see respectful posts with a different perspective than mine"). We propose a method, CTRL-Rec, that allows for natural language control of traditional recommender systems in real-time with computational efficiency. Specifically, at training time, we use an LLM to simulate whether users would approve of items based on their language requests, and we train embedding models that approximate such simulated judgments. We then integrate these user-request-based predictions into the standard weighting of signals that traditional recommender systems optimize. At deployment time, we require only a single LLM embedding computation per user request, allowing for real-time control of recommendations. In experiments with the MovieLens dataset, our method consistently allows for fine-grained control across a diversity of requests. In a study with 19 Letterboxd users, we find that CTRL-Rec was positively received by users and significantly enhanced users' sense of control and satisfaction with recommendations compared to traditional controls.
Chain of Alignment: Integrating Public Will with Expert Intelligence for Language Model Alignment
Nov 15, 2024



We introduce a method to measure the alignment between public will and language model (LM) behavior that can be applied to fine-tuning, online oversight, and pre-release safety checks. Our `chain of alignment' (CoA) approach produces a rule based reward (RBR) by creating model behavior $\textit{rules}$ aligned to normative $\textit{objectives}$ aligned to $\textit{public will}$. This factoring enables a nonexpert public to directly specify their will through the normative objectives, while expert intelligence is used to figure out rules entailing model behavior that best achieves those objectives. We validate our approach by applying it across three different domains of LM prompts related to mental health. We demonstrate a public input process built on collective dialogues and bridging-based ranking that reliably produces normative objectives supported by at least $96\% \pm 2\%$ of the US public. We then show that rules developed by mental health experts to achieve those objectives enable a RBR that evaluates an LM response's alignment with the objectives similarly to human experts (Pearson's $r=0.841$, $AUC=0.964$). By measuring alignment with objectives that have near unanimous public support, these CoA RBRs provide an approximate measure of alignment between LM behavior and public will.
Saving the Sonorine: Photovisual Audio Recovery Using Image Processing and Computer Vision Techniques
May 22, 2020


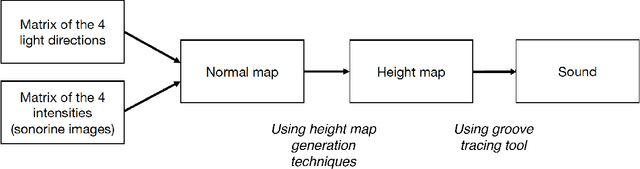
This paper presents a novel technique to recover audio from sonorines, an early 20th century form of analogue sound storage. Our method uses high resolution photographs of sonorines under different lighting conditions to observe the change in reflection behavior of the physical surface features and create a three-dimensional height map of the surface. Sound can then be extracted using height information within the surface's grooves, mimicking a physical stylus on a phonograph. Unlike traditional playback methods, our method has the advantage of being contactless: the medium will not incur damage and wear from being played repeatedly. We compare the results of our technique to a previously successful contactless method using flatbed scans of the sonorines, and conclude with future research that can be applied to this photovisual approach to audio recovery.