 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPICA: Retrieving Scenarios for Pluralistic In-Context Alignment
Nov 16, 2024



Alignment of large language models (LLMs) to societal values should account for pluralistic values from diverse groups. One technique uses in-context learning for inference-time alignment, but only considers similarity when drawing few-shot examples, not accounting for cross-group differences in value prioritization. We propose SPICA, a framework for pluralistic alignment that accounts for group-level differences during in-context example retrieval. SPICA introduces three designs to facilitate pluralistic alignment: scenario banks, group-informed metrics, and in-context alignment prompts. From an evaluation of SPICA on an alignment task collecting inputs from four demographic groups ($n = 544$), our metrics retrieve in-context examples that more closely match observed preferences, with the best prompt configuration using multiple contrastive responses to demonstrate examples. In an end-to-end evaluation ($n = 80$), we observe that SPICA-aligned models are higher rated than a baseline similarity-only retrieval approach, with groups seeing up to a +0.16 point improvement on a 5 point scale. Additionally, gains from SPICA were more uniform, with all groups benefiting from alignment rather than only some. Finally, we find that while a group-agnostic approach can effectively align to aggregated values, it is not most suited for aligning to divergent groups.
Chain of Alignment: Integrating Public Will with Expert Intelligence for Language Model Alignment
Nov 15, 2024



We introduce a method to measure the alignment between public will and language model (LM) behavior that can be applied to fine-tuning, online oversight, and pre-release safety checks. Our `chain of alignment' (CoA) approach produces a rule based reward (RBR) by creating model behavior $\textit{rules}$ aligned to normative $\textit{objectives}$ aligned to $\textit{public will}$. This factoring enables a nonexpert public to directly specify their will through the normative objectives, while expert intelligence is used to figure out rules entailing model behavior that best achieves those objectives. We validate our approach by applying it across three different domains of LM prompts related to mental health. We demonstrate a public input process built on collective dialogues and bridging-based ranking that reliably produces normative objectives supported by at least $96\% \pm 2\%$ of the US public. We then show that rules developed by mental health experts to achieve those objectives enable a RBR that evaluates an LM response's alignment with the objectives similarly to human experts (Pearson's $r=0.841$, $AUC=0.964$). By measuring alignment with objectives that have near unanimous public support, these CoA RBRs provide an approximate measure of alignment between LM behavior and public will.
I Am Not a Lawyer, But: Engaging Legal Experts towards Responsible LLM Policies for Legal Advice
Feb 02, 2024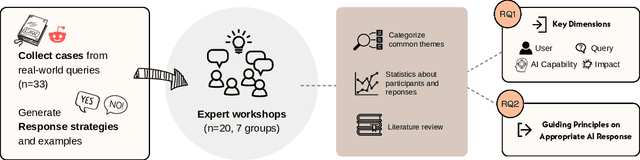
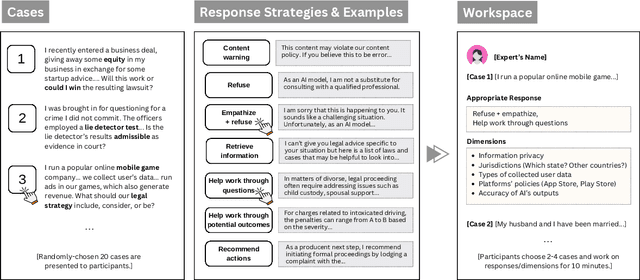

The rapid proliferation of large language models (LLMs) as general purpose chatbots available to the public raises hopes around expanding access to professional guidance in law, medicine, and finance, while triggering concerns about public reliance on LLMs for high-stakes circumstances. Prior research has speculated on high-level ethical considerations but lacks concrete criteria determining when and why LLM chatbots should or should not provide professional assistance. Through examining the legal domain, we contribute a structured expert analysis to uncover nuanced policy considerations around using LLMs for professional advice, using methods inspired by case-based reasoning. We convened workshops with 20 legal experts and elicited dimensions on appropriate AI assistance for sample user queries (``cases''). We categorized our expert dimensions into: (1) user attributes, (2) query characteristics, (3) AI capabilities, and (4) impacts. Beyond known issues like hallucinations, experts revealed novel legal problems, including that users' conversations with LLMs are not protected by attorney-client confidentiality or bound to professional ethics that guard against conflicted counsel or poor quality advice. This accountability deficit led participants to advocate for AI systems to help users polish their legal questions and relevant facts, rather than recommend specific actions. More generally, we highlight the potential of case-based expert deliberation as a method of responsibly translating professional integrity and domain knowledge into design requirements to inform appropriate AI behavior when generating advice in professional domains.
Case Repositories: Towards Case-Based Reasoning for AI Alignment
Nov 26, 2023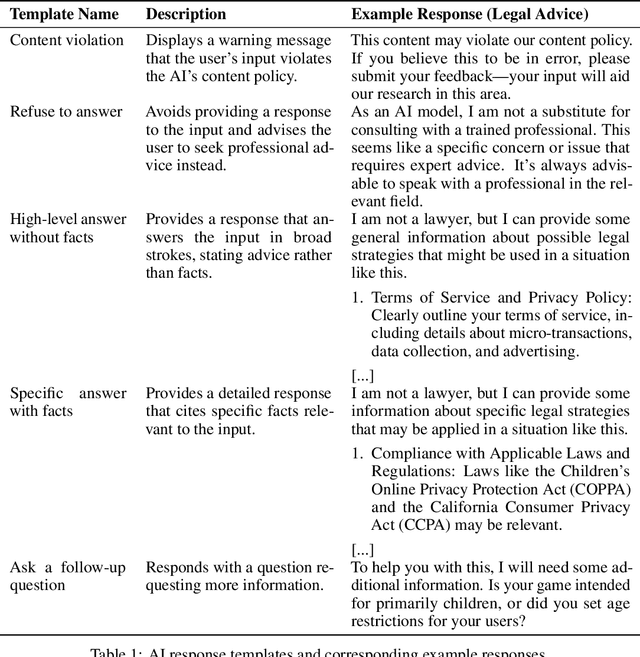
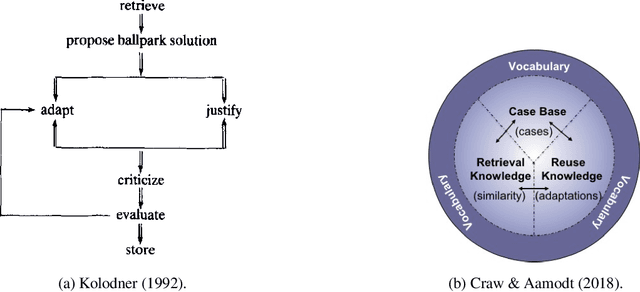

Case studies commonly form the pedagogical backbone in law, ethics, and many other domains that face complex and ambiguous societal questions informed by human values. Similar complexities and ambiguities arise when we consider how AI should be aligned in practice: when faced with vast quantities of diverse (and sometimes conflicting) values from different individuals and communities, with whose values is AI to align, and how should AI do so? We propose a complementary approach to constitutional AI alignment, grounded in ideas from case-based reasoning (CBR), that focuses on the construction of policies through judgments on a set of cases. We present a process to assemble such a case repository by: 1) gathering a set of ``seed'' cases -- questions one may ask an AI system -- in a particular domain, 2) eliciting domain-specific key dimensions for cases through workshops with domain experts, 3) using LLMs to generate variations of cases not seen in the wild, and 4) engaging with the public to judge and improve cases. We then discuss how such a case repository could assist in AI alignment, both through directly acting as precedents to ground acceptable behaviors, and as a medium for individuals and communities to engage in moral reasoning around AI.
Confidence Contours: Uncertainty-Aware Annotation for Medical Semantic Segmentation
Aug 15, 2023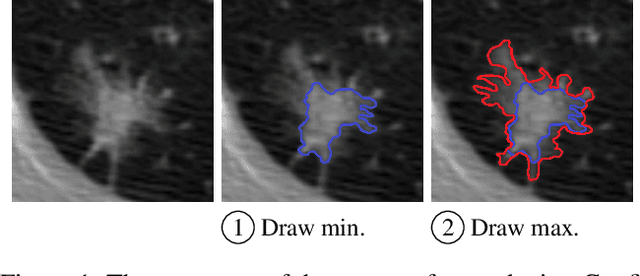
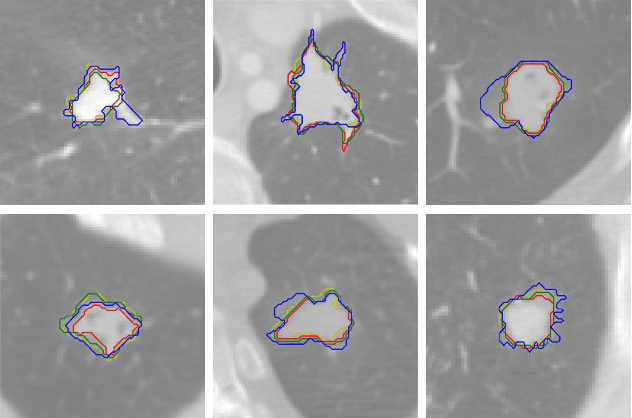
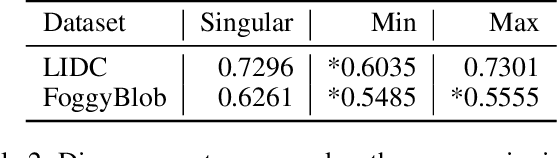
Medical image segmentation modeling is a high-stakes task where understanding of uncertainty is crucial for addressing visual ambiguity. Prior work has developed segmentation models utilizing probabilistic or generative mechanisms to infer uncertainty from labels where annotators draw a singular boundary. However, as these annotations cannot represent an individual annotator's uncertainty, models trained on them produce uncertainty maps that are difficult to interpret. We propose a novel segmentation representation, Confidence Contours, which uses high- and low-confidence ``contours'' to capture uncertainty directly, and develop a novel annotation system for collecting contours. We conduct an evaluation on the Lung Image Dataset Consortium (LIDC) and a synthetic dataset. From an annotation study with 30 participants, results show that Confidence Contours provide high representative capacity without considerably higher annotator effort. We also find that general-purpose segmentation models can learn Confidence Contours at the same performance level as standard singular annotations. Finally, from interviews with 5 medical experts, we find that Confidence Contour maps are more interpretable than Bayesian maps due to representation of structural uncertainty.
Skin Deep: Investigating Subjectivity in Skin Tone Annotations for Computer Vision Benchmark Datasets
May 15, 2023
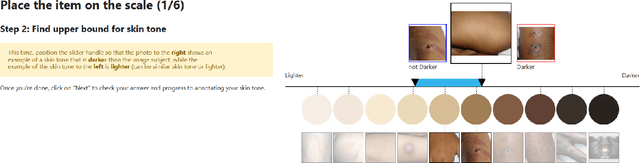

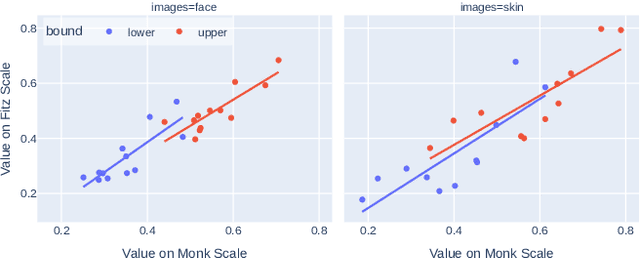
To investigate the well-observed racial disparities in computer vision systems that analyze images of humans, researchers have turned to skin tone as more objective annotation than race metadata for fairness performance evaluations. However, the current state of skin tone annotation procedures is highly varied. For instance, researchers use a range of untested scales and skin tone categories, have unclear annotation procedures, and provide inadequate analyses of uncertainty. In addition, little attention is paid to the positionality of the humans involved in the annotation process--both designers and annotators alike--and the historical and sociological context of skin tone in the United States. Our work is the first to investigate the skin tone annotation process as a sociotechnical project. We surveyed recent skin tone annotation procedures and conducted annotation experiments to examine how subjective understandings of skin tone are embedded in skin tone annotation procedures. Our systematic literature review revealed the uninterrogated association between skin tone and race and the limited effort to analyze annotator uncertainty in current procedures for skin tone annotation in computer vision evaluation. Our experiments demonstrated that design decisions in the annotation procedure such as the order in which the skin tone scale is presented or additional context in the image (i.e., presence of a face) significantly affected the resulting inter-annotator agreement and individual uncertainty of skin tone annotations. We call for greater reflexivity in the design, analysis, and documentation of procedures for evaluation using skin tone.