 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResponse-Aware User Memory Selection for LLM Personalization
Apr 15, 2026A common approach to personalization in large language models (LLMs) is to incorporate a subset of the user memory into the prompt at inference time to guide the model's generation. Existing methods select these subsets primarily using similarity between user memory items and input queries, ignoring how features actually affect the model's response distribution. We propose Response-Utility optimization for Memory Selection (RUMS), a novel method that selects user memory items by measuring the mutual information between a subset of memory and the model's outputs, identifying items that reduce response uncertainty and sharpen predictions beyond semantic similarity. We demonstrate that this information-theoretic foundation enables more principled user memory selection that aligns more closely with human selection compared to state-of-the-art methods, and models $400\times$ larger. Additionally, we show that memory items selected using RUMS result in better response quality compared to existing approaches, while having up to $95\%$ reduction in computational cost.
PrefPalette: Personalized Preference Modeling with Latent Attributes
Jul 17, 2025



Personalizing AI systems requires understanding not just what users prefer, but the reasons that underlie those preferences - yet current preference models typically treat human judgment as a black box. We introduce PrefPalette, a framework that decomposes preferences into attribute dimensions and tailors its preference prediction to distinct social community values in a human-interpretable manner. PrefPalette operationalizes a cognitive science principle known as multi-attribute decision making in two ways: (1) a scalable counterfactual attribute synthesis step that involves generating synthetic training data to isolate for individual attribute effects (e.g., formality, humor, cultural values), and (2) attention-based preference modeling that learns how different social communities dynamically weight these attributes. This approach moves beyond aggregate preference modeling to capture the diverse evaluation frameworks that drive human judgment. When evaluated on 45 social communities from the online platform Reddit, PrefPalette outperforms GPT-4o by 46.6% in average prediction accuracy. Beyond raw predictive improvements, PrefPalette also shed light on intuitive, community-specific profiles: scholarly communities prioritize verbosity and stimulation, conflict-oriented communities value sarcasm and directness, and support-based communities emphasize empathy. By modeling the attribute-mediated structure of human judgment, PrefPalette delivers both superior preference modeling and transparent, interpretable insights, and serves as a first step toward more trustworthy, value-aware personalized applications.
SPICA: Retrieving Scenarios for Pluralistic In-Context Alignment
Nov 16, 2024



Alignment of large language models (LLMs) to societal values should account for pluralistic values from diverse groups. One technique uses in-context learning for inference-time alignment, but only considers similarity when drawing few-shot examples, not accounting for cross-group differences in value prioritization. We propose SPICA, a framework for pluralistic alignment that accounts for group-level differences during in-context example retrieval. SPICA introduces three designs to facilitate pluralistic alignment: scenario banks, group-informed metrics, and in-context alignment prompts. From an evaluation of SPICA on an alignment task collecting inputs from four demographic groups ($n = 544$), our metrics retrieve in-context examples that more closely match observed preferences, with the best prompt configuration using multiple contrastive responses to demonstrate examples. In an end-to-end evaluation ($n = 80$), we observe that SPICA-aligned models are higher rated than a baseline similarity-only retrieval approach, with groups seeing up to a +0.16 point improvement on a 5 point scale. Additionally, gains from SPICA were more uniform, with all groups benefiting from alignment rather than only some. Finally, we find that while a group-agnostic approach can effectively align to aggregated values, it is not most suited for aligning to divergent groups.
ComPO: Community Preferences for Language Model Personalization
Oct 21, 2024


Conventional algorithms for training language models (LMs) with human feedback rely on preferences that are assumed to account for an "average" user, disregarding subjectivity and finer-grained variations. Recent studies have raised concerns that aggregating such diverse and often contradictory human feedback to finetune models results in generic models that generate outputs not preferred by many user groups, as they tend to average out styles and norms. To address this issue, we draw inspiration from recommendation systems and propose ComPO, a method to personalize preference optimization in LMs by contextualizing the probability distribution of model outputs with the preference provider. Focusing on group-level preferences rather than individuals, we collect and release ComPRed, a question answering dataset with community-level preferences from Reddit. This dataset facilitates studying diversity in preferences without incurring privacy concerns associated with individual feedback. Our experiments reveal that conditioning language models on a community identifier (i.e., subreddit name) during preference tuning substantially enhances model performance. Conversely, replacing this context with random subreddit identifiers significantly diminishes performance, highlighting the effectiveness of our approach in tailoring responses to communities' preferences.
Locating Information Gaps and Narrative Inconsistencies Across Languages: A Case Study of LGBT People Portrayals on Wikipedia
Oct 05, 2024



To explain social phenomena and identify systematic biases, much research in computational social science focuses on comparative text analyses. These studies often rely on coarse corpus-level statistics or local word-level analyses, mainly in English. We introduce the InfoGap method -- an efficient and reliable approach to locating information gaps and inconsistencies in articles at the fact level, across languages. We evaluate InfoGap by analyzing LGBT people's portrayals, across 2.7K biography pages on English, Russian, and French Wikipedias. We find large discrepancies in factual coverage across the languages. Moreover, our analysis reveals that biographical facts carrying negative connotations are more likely to be highlighted in Russian Wikipedia. Crucially, InfoGap both facilitates large scale analyses, and pinpoints local document- and fact-level information gaps, laying a new foundation for targeted and nuanced comparative language analysis at scale.
CulturalBench: a Robust, Diverse and Challenging Benchmark on Measuring the (Lack of) Cultural Knowledge of LLMs
Oct 03, 2024



To make large language models (LLMs) more helpful across diverse cultures, it is essential to have effective cultural knowledge benchmarks to measure and track our progress. Effective benchmarks need to be robust, diverse, and challenging. We introduce CulturalBench: a set of 1,227 human-written and human-verified questions for effectively assessing LLMs' cultural knowledge, covering 45 global regions including the underrepresented ones like Bangladesh, Zimbabwe, and Peru. Questions - each verified by five independent annotators - span 17 diverse topics ranging from food preferences to greeting etiquettes. We evaluate models on two setups: CulturalBench-Easy and CulturalBench-Hard which share the same questions but asked differently. We find that LLMs are sensitive to such difference in setups (e.g., GPT-4o with 27.3% difference). Compared to human performance (92.6% accuracy), CulturalBench-Hard is more challenging for frontier LLMs with the best performing model (GPT-4o) at only 61.5% and the worst (Llama3-8b) at 21.4%. Moreover, we find that LLMs often struggle with tricky questions that have multiple correct answers (e.g., What utensils do the Chinese usually use?), revealing a tendency to converge to a single answer. Our results also indicate that OpenAI GPT-4o substantially outperform other proprietary and open source models in questions related to all but one region (Oceania). Nonetheless, all models consistently underperform on questions related to South America and the Middle East.
ValueScope: Unveiling Implicit Norms and Values via Return Potential Model of Social Interactions
Jul 02, 2024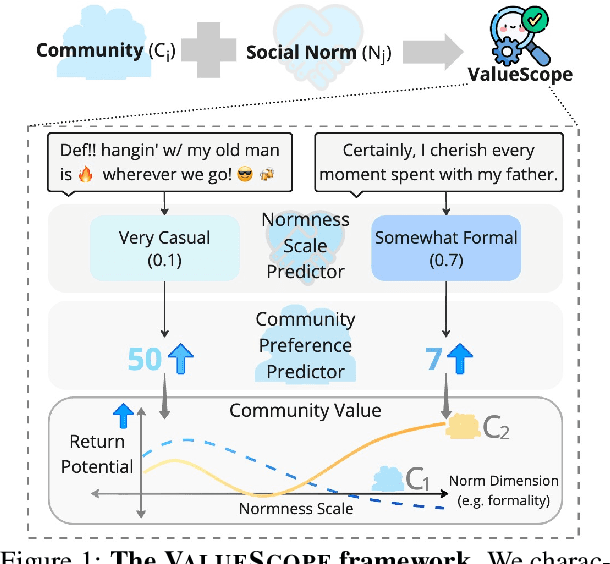
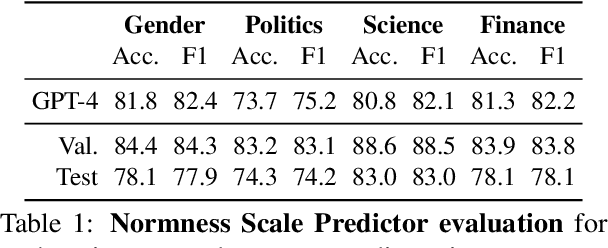

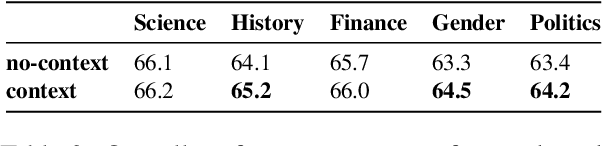
This study introduces ValueScope, a framework leveraging language models to quantify social norms and values within online communities, grounded in social science perspectives on normative structures. We employ ValueScope to dissect and analyze linguistic and stylistic expressions across 13 Reddit communities categorized under gender, politics, science, and finance. Our analysis provides a quantitative foundation showing that even closely related communities exhibit remarkably diverse norms. This diversity supports existing theories and adds a new dimension--community preference--to understanding community interactions. ValueScope not only delineates differing social norms among communities but also effectively traces their evolution and the influence of significant external events like the U.S. presidential elections and the emergence of new sub-communities. The framework thus highlights the pivotal role of social norms in shaping online interactions, presenting a substantial advance in both the theory and application of social norm studies in digital spaces.
Modular Pluralism: Pluralistic Alignment via Multi-LLM Collaboration
Jun 22, 2024While existing alignment paradigms have been integral in developing large language models (LLMs), LLMs often learn an averaged human preference and struggle to model diverse preferences across cultures, demographics, and communities. We propose Modular Pluralism, a modular framework based on multi-LLM collaboration for pluralistic alignment: it "plugs into" a base LLM a pool of smaller but specialized community LMs, where models collaborate in distinct modes to flexibility support three modes of pluralism: Overton, steerable, and distributional. Modular Pluralism is uniquely compatible with black-box LLMs and offers the modular control of adding new community LMs for previously underrepresented communities. We evaluate Modular Pluralism with six tasks and four datasets featuring questions/instructions with value-laden and perspective-informed responses. Extensive experiments demonstrate that Modular Pluralism advances the three pluralism objectives across six black-box and open-source LLMs. Further analysis reveals that LLMs are generally faithful to the inputs from smaller community LLMs, allowing seamless patching by adding a new community LM to better cover previously underrepresented communities.
CulturalTeaming: AI-Assisted Interactive Red-Teaming for Challenging LLMs' (Lack of) Multicultural Knowledge
Apr 10, 2024



Frontier large language models (LLMs) are developed by researchers and practitioners with skewed cultural backgrounds and on datasets with skewed sources. However, LLMs' (lack of) multicultural knowledge cannot be effectively assessed with current methods for developing benchmarks. Existing multicultural evaluations primarily rely on expensive and restricted human annotations or potentially outdated internet resources. Thus, they struggle to capture the intricacy, dynamics, and diversity of cultural norms. LLM-generated benchmarks are promising, yet risk propagating the same biases they are meant to measure. To synergize the creativity and expert cultural knowledge of human annotators and the scalability and standardizability of LLM-based automation, we introduce CulturalTeaming, an interactive red-teaming system that leverages human-AI collaboration to build truly challenging evaluation dataset for assessing the multicultural knowledge of LLMs, while improving annotators' capabilities and experiences. Our study reveals that CulturalTeaming's various modes of AI assistance support annotators in creating cultural questions, that modern LLMs fail at, in a gamified manner. Importantly, the increased level of AI assistance (e.g., LLM-generated revision hints) empowers users to create more difficult questions with enhanced perceived creativity of themselves, shedding light on the promises of involving heavier AI assistance in modern evaluation dataset creation procedures. Through a series of 1-hour workshop sessions, we gather CULTURALBENCH-V0.1, a compact yet high-quality evaluation dataset with users' red-teaming attempts, that different families of modern LLMs perform with accuracy ranging from 37.7% to 72.2%, revealing a notable gap in LLMs' multicultural proficiency.
What Constitutes a Faithful Summary? Preserving Author Perspectives in News Summarization
Nov 16, 2023



In this work, we take a first step towards designing summarization systems that are faithful to the author's opinions and perspectives. Focusing on a case study of preserving political perspectives in news summarization, we find that existing approaches alter the political opinions and stances of news articles in more than 50% of summaries, misrepresenting the intent and perspectives of the news authors. We thus propose P^3Sum, a diffusion model-based summarization approach controlled by political perspective classifiers. In P^3Sum, the political leaning of a generated summary is iteratively evaluated at each decoding step, and any drift from the article's original stance incurs a loss back-propagated to the embedding layers, steering the political stance of the summary at inference time. Extensive experiments on three news summarization datasets demonstrate that P^3Sum outperforms state-of-the-art summarization systems and large language models by up to 11.4% in terms of the success rate of stance preservation, with on-par performance on standard summarization utility metrics. These findings highlight the lacunae that even for state-of-the-art models it is still challenging to preserve author perspectives in news summarization, while P^3Sum presents an important first step towards evaluating and developing summarization systems that are faithful to author intent and perspectives.