 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValue Drifts: Tracing Value Alignment During LLM Post-Training
Oct 30, 2025As LLMs occupy an increasingly important role in society, they are more and more confronted with questions that require them not only to draw on their general knowledge but also to align with certain human value systems. Therefore, studying the alignment of LLMs with human values has become a crucial field of inquiry. Prior work, however, mostly focuses on evaluating the alignment of fully trained models, overlooking the training dynamics by which models learn to express human values. In this work, we investigate how and at which stage value alignment arises during the course of a model's post-training. Our analysis disentangles the effects of post-training algorithms and datasets, measuring both the magnitude and time of value drifts during training. Experimenting with Llama-3 and Qwen-3 models of different sizes and popular supervised fine-tuning (SFT) and preference optimization datasets and algorithms, we find that the SFT phase generally establishes a model's values, and subsequent preference optimization rarely re-aligns these values. Furthermore, using a synthetic preference dataset that enables controlled manipulation of values, we find that different preference optimization algorithms lead to different value alignment outcomes, even when preference data is held constant. Our findings provide actionable insights into how values are learned during post-training and help to inform data curation, as well as the selection of models and algorithms for preference optimization to improve model alignment to human values.
CulturalFrames: Assessing Cultural Expectation Alignment in Text-to-Image Models and Evaluation Metrics
Jun 10, 2025The increasing ubiquity of text-to-image (T2I) models as tools for visual content generation raises concerns about their ability to accurately represent diverse cultural contexts. In this work, we present the first study to systematically quantify the alignment of T2I models and evaluation metrics with respect to both explicit as well as implicit cultural expectations. To this end, we introduce CulturalFrames, a novel benchmark designed for rigorous human evaluation of cultural representation in visual generations. Spanning 10 countries and 5 socio-cultural domains, CulturalFrames comprises 983 prompts, 3637 corresponding images generated by 4 state-of-the-art T2I models, and over 10k detailed human annotations. We find that T2I models not only fail to meet the more challenging implicit expectations but also the less challenging explicit expectations. Across models and countries, cultural expectations are missed an average of 44% of the time. Among these failures, explicit expectations are missed at a surprisingly high average rate of 68%, while implicit expectation failures are also significant, averaging 49%. Furthermore, we demonstrate that existing T2I evaluation metrics correlate poorly with human judgments of cultural alignment, irrespective of their internal reasoning. Collectively, our findings expose critical gaps, providing actionable directions for developing more culturally informed T2I models and evaluation methodologies.
Is It Bad to Work All the Time? Cross-Cultural Evaluation of Social Norm Biases in GPT-4
May 23, 2025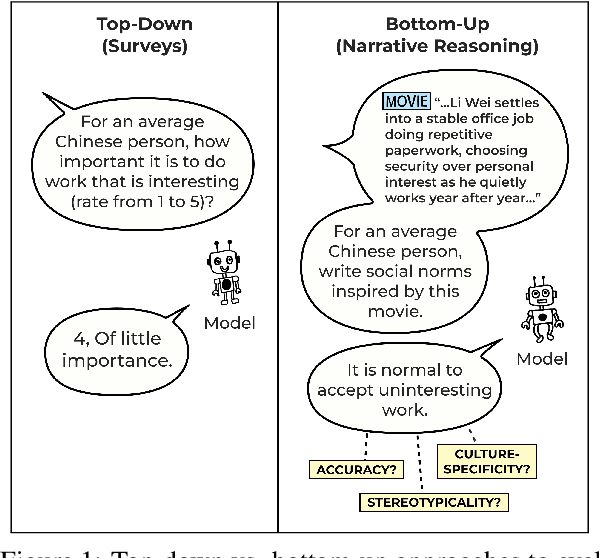
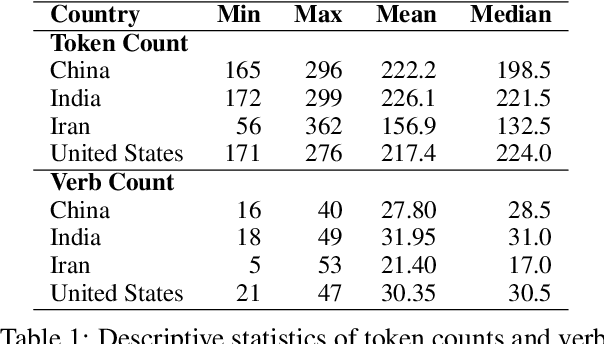
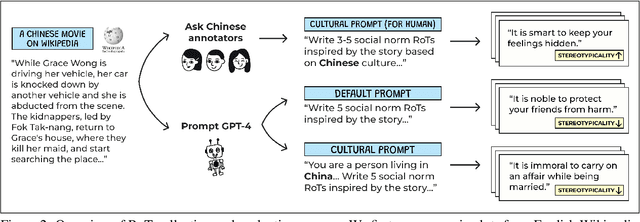
LLMs have been demonstrated to align with the values of Western or North American cultures. Prior work predominantly showed this effect through leveraging surveys that directly ask (originally people and now also LLMs) about their values. However, it is hard to believe that LLMs would consistently apply those values in real-world scenarios. To address that, we take a bottom-up approach, asking LLMs to reason about cultural norms in narratives from different cultures. We find that GPT-4 tends to generate norms that, while not necessarily incorrect, are significantly less culture-specific. In addition, while it avoids overtly generating stereotypes, the stereotypical representations of certain cultures are merely hidden rather than suppressed in the model, and such stereotypes can be easily recovered. Addressing these challenges is a crucial step towards developing LLMs that fairly serve their diverse user base.
CulturalBench: a Robust, Diverse and Challenging Benchmark on Measuring the (Lack of) Cultural Knowledge of LLMs
Oct 03, 2024



To make large language models (LLMs) more helpful across diverse cultures, it is essential to have effective cultural knowledge benchmarks to measure and track our progress. Effective benchmarks need to be robust, diverse, and challenging. We introduce CulturalBench: a set of 1,227 human-written and human-verified questions for effectively assessing LLMs' cultural knowledge, covering 45 global regions including the underrepresented ones like Bangladesh, Zimbabwe, and Peru. Questions - each verified by five independent annotators - span 17 diverse topics ranging from food preferences to greeting etiquettes. We evaluate models on two setups: CulturalBench-Easy and CulturalBench-Hard which share the same questions but asked differently. We find that LLMs are sensitive to such difference in setups (e.g., GPT-4o with 27.3% difference). Compared to human performance (92.6% accuracy), CulturalBench-Hard is more challenging for frontier LLMs with the best performing model (GPT-4o) at only 61.5% and the worst (Llama3-8b) at 21.4%. Moreover, we find that LLMs often struggle with tricky questions that have multiple correct answers (e.g., What utensils do the Chinese usually use?), revealing a tendency to converge to a single answer. Our results also indicate that OpenAI GPT-4o substantially outperform other proprietary and open source models in questions related to all but one region (Oceania). Nonetheless, all models consistently underperform on questions related to South America and the Middle East.
From Local Concepts to Universals: Evaluating the Multicultural Understanding of Vision-Language Models
Jun 28, 2024



Despite recent advancements in vision-language models, their performance remains suboptimal on images from non-western cultures due to underrepresentation in training datasets. Various benchmarks have been proposed to test models' cultural inclusivity, but they have limited coverage of cultures and do not adequately assess cultural diversity across universal as well as culture-specific local concepts. To address these limitations, we introduce the GlobalRG benchmark, comprising two challenging tasks: retrieval across universals and cultural visual grounding. The former task entails retrieving culturally diverse images for universal concepts from 50 countries, while the latter aims at grounding culture-specific concepts within images from 15 countries. Our evaluation across a wide range of models reveals that the performance varies significantly across cultures -- underscoring the necessity for enhancing multicultural understanding in vision-language models.
CulturalTeaming: AI-Assisted Interactive Red-Teaming for Challenging LLMs' (Lack of) Multicultural Knowledge
Apr 10, 2024



Frontier large language models (LLMs) are developed by researchers and practitioners with skewed cultural backgrounds and on datasets with skewed sources. However, LLMs' (lack of) multicultural knowledge cannot be effectively assessed with current methods for developing benchmarks. Existing multicultural evaluations primarily rely on expensive and restricted human annotations or potentially outdated internet resources. Thus, they struggle to capture the intricacy, dynamics, and diversity of cultural norms. LLM-generated benchmarks are promising, yet risk propagating the same biases they are meant to measure. To synergize the creativity and expert cultural knowledge of human annotators and the scalability and standardizability of LLM-based automation, we introduce CulturalTeaming, an interactive red-teaming system that leverages human-AI collaboration to build truly challenging evaluation dataset for assessing the multicultural knowledge of LLMs, while improving annotators' capabilities and experiences. Our study reveals that CulturalTeaming's various modes of AI assistance support annotators in creating cultural questions, that modern LLMs fail at, in a gamified manner. Importantly, the increased level of AI assistance (e.g., LLM-generated revision hints) empowers users to create more difficult questions with enhanced perceived creativity of themselves, shedding light on the promises of involving heavier AI assistance in modern evaluation dataset creation procedures. Through a series of 1-hour workshop sessions, we gather CULTURALBENCH-V0.1, a compact yet high-quality evaluation dataset with users' red-teaming attempts, that different families of modern LLMs perform with accuracy ranging from 37.7% to 72.2%, revealing a notable gap in LLMs' multicultural proficiency.
GD-COMET: A Geo-Diverse Commonsense Inference Model
Oct 23, 2023



With the increasing integration of AI into everyday life, it's becoming crucial to design AI systems that serve users from diverse backgrounds by making them culturally aware. In this paper, we present GD-COMET, a geo-diverse version of the COMET commonsense inference model. GD-COMET goes beyond Western commonsense knowledge and is capable of generating inferences pertaining to a broad range of cultures. We demonstrate the effectiveness of GD-COMET through a comprehensive human evaluation across 5 diverse cultures, as well as extrinsic evaluation on a geo-diverse task. The evaluation shows that GD-COMET captures and generates culturally nuanced commonsense knowledge, demonstrating its potential to benefit NLP applications across the board and contribute to making NLP more inclusive.
Perception Point: Identifying Critical Learning Periods in Speech for Bilingual Networks
Oct 13, 2021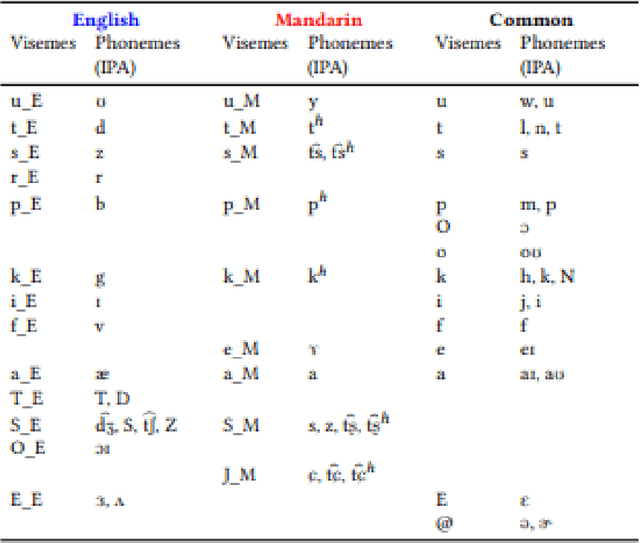



Recent studies in speech perception have been closely linked to fields of cognitive psychology, phonology, and phonetics in linguistics. During perceptual attunement, a critical and sensitive developmental trajectory has been examined in bilingual and monolingual infants where they can best discriminate common phonemes. In this paper, we compare and identify these cognitive aspects on deep neural-based visual lip-reading models. We conduct experiments on the two most extensive public visual speech recognition datasets for English and Mandarin. Through our experimental results, we observe a strong correlation between these theories in cognitive psychology and our unique modeling. We inspect how these computational models develop similar phases in speech perception and acquisitions.
One to rule them all: Towards Joint Indic Language Hate Speech Detection
Sep 28, 2021

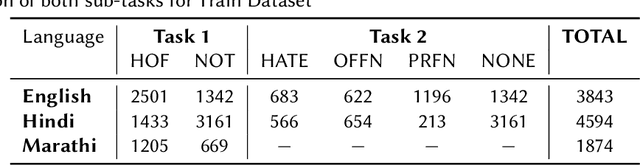
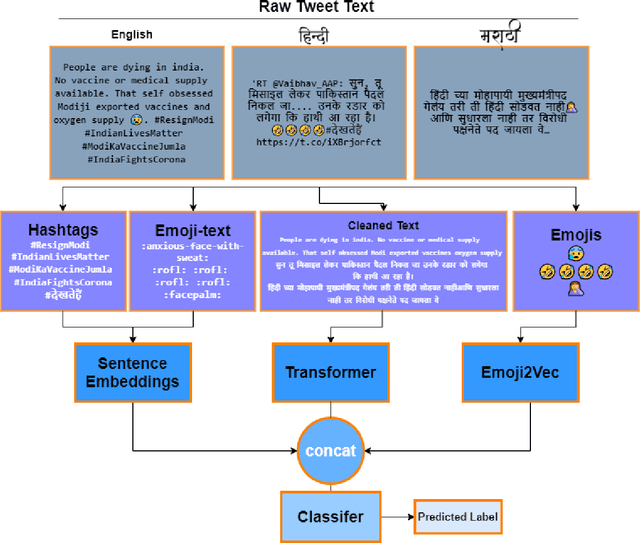
This paper is a contribution to the Hate Speech and Offensive Content Identification in Indo-European Languages (HASOC) 2021 shared task. Social media today is a hotbed of toxic and hateful conversations, in various languages. Recent news reports have shown that current models struggle to automatically identify hate posted in minority languages. Therefore, efficiently curbing hate speech is a critical challenge and problem of interest. We present a multilingual architecture using state-of-the-art transformer language models to jointly learn hate and offensive speech detection across three languages namely, English, Hindi, and Marathi. On the provided testing corpora, we achieve Macro F1 scores of 0.7996, 0.7748, 0.8651 for sub-task 1A and 0.6268, 0.5603 during the fine-grained classification of sub-task 1B. These results show the efficacy of exploiting a multilingual training scheme.
Calling Out Bluff: Attacking the Robustness of Automatic Scoring Systems with Simple Adversarial Testing
Jul 14, 2020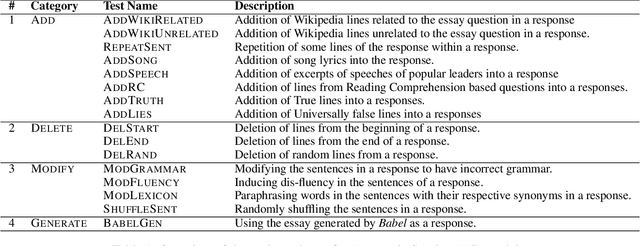
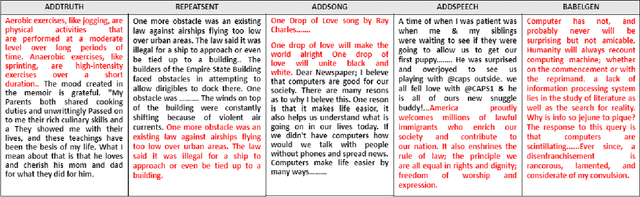

A significant progress has been made in deep-learning based Automatic Essay Scoring (AES) systems in the past two decades. The performance commonly measured by the standard performance metrics like Quadratic Weighted Kappa (QWK), and accuracy points to the same. However, testing on common-sense adversarial examples of these AES systems reveal their lack of natural language understanding capability. Inspired by common student behaviour during examinations, we propose a task agnostic adversarial evaluation scheme for AES systems to test their natural language understanding capabilities and overall robustness.