 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying and Mitigating Gender Bias in Hyperbolic Word Embeddings
Sep 28, 2021
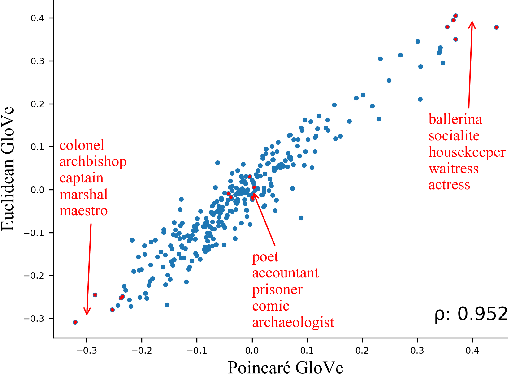

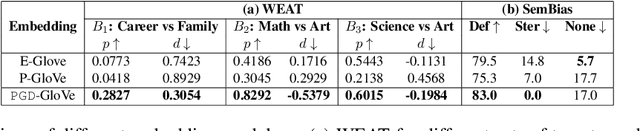
Euclidean word embedding models such as GloVe and Word2Vec have been shown to reflect human-like gender biases. In this paper, we extend the study of gender bias to the recently popularized hyperbolic word embeddings. We propose gyrocosine bias, a novel measure for quantifying gender bias in hyperbolic word representations and observe a significant presence of gender bias. To address this problem, we propose Poincar\'e Gender Debias (PGD), a novel debiasing procedure for hyperbolic word representations. Experiments on a suit of evaluation tests show that PGD effectively reduces bias while adding a minimal semantic offset.
One to rule them all: Towards Joint Indic Language Hate Speech Detection
Sep 28, 2021

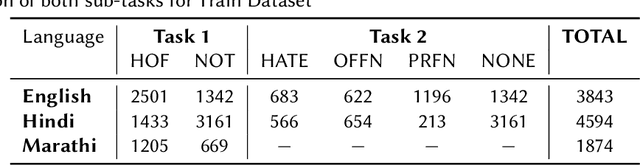
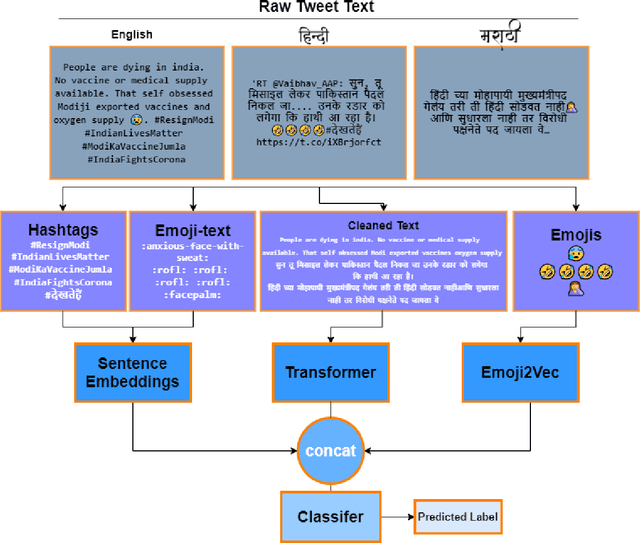
This paper is a contribution to the Hate Speech and Offensive Content Identification in Indo-European Languages (HASOC) 2021 shared task. Social media today is a hotbed of toxic and hateful conversations, in various languages. Recent news reports have shown that current models struggle to automatically identify hate posted in minority languages. Therefore, efficiently curbing hate speech is a critical challenge and problem of interest. We present a multilingual architecture using state-of-the-art transformer language models to jointly learn hate and offensive speech detection across three languages namely, English, Hindi, and Marathi. On the provided testing corpora, we achieve Macro F1 scores of 0.7996, 0.7748, 0.8651 for sub-task 1A and 0.6268, 0.5603 during the fine-grained classification of sub-task 1B. These results show the efficacy of exploiting a multilingual training scheme.
Fair Embedding Engine: A Library for Analyzing and Mitigating Gender Bias in Word Embeddings
Oct 25, 2020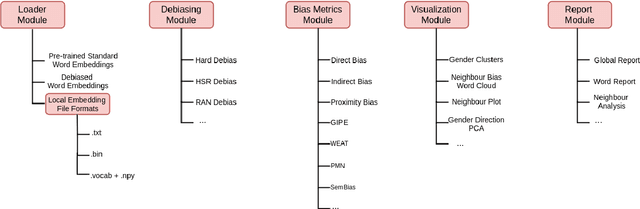

Non-contextual word embedding models have been shown to inherit human-like stereotypical biases of gender, race and religion from the training corpora. To counter this issue, a large body of research has emerged which aims to mitigate these biases while keeping the syntactic and semantic utility of embeddings intact. This paper describes Fair Embedding Engine (FEE), a library for analysing and mitigating gender bias in word embeddings. FEE combines various state of the art techniques for quantifying, visualising and mitigating gender bias in word embeddings under a standard abstraction. FEE will aid practitioners in fast track analysis of existing debiasing methods on their embedding models. Further, it will allow rapid prototyping of new methods by evaluating their performance on a suite of standard metrics.
Nurse is Closer to Woman than Surgeon? Mitigating Gender-Biased Proximities in Word Embeddings
Jun 02, 2020

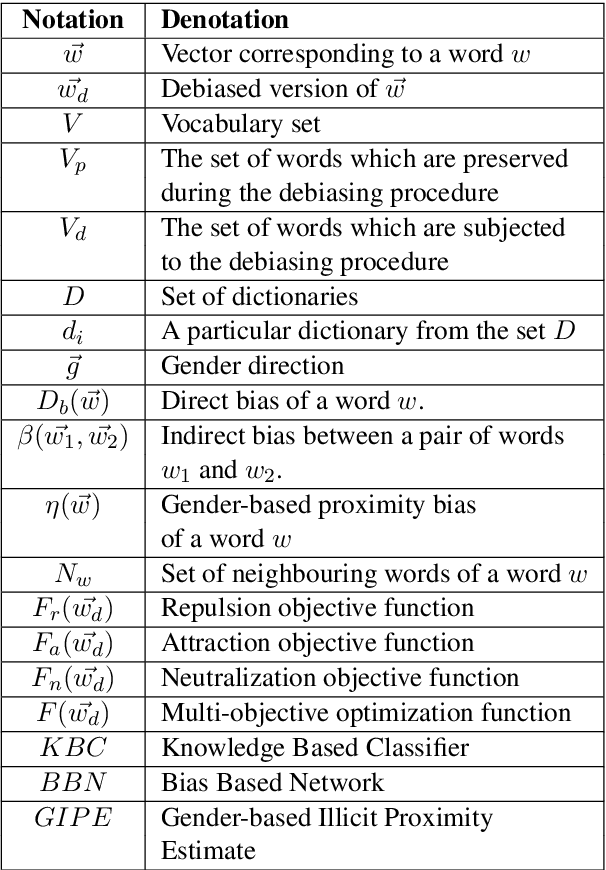

Word embeddings are the standard model for semantic and syntactic representations of words. Unfortunately, these models have been shown to exhibit undesirable word associations resulting from gender, racial, and religious biases. Existing post-processing methods for debiasing word embeddings are unable to mitigate gender bias hidden in the spatial arrangement of word vectors. In this paper, we propose RAN-Debias, a novel gender debiasing methodology which not only eliminates the bias present in a word vector but also alters the spatial distribution of its neighbouring vectors, achieving a bias-free setting while maintaining minimal semantic offset. We also propose a new bias evaluation metric - Gender-based Illicit Proximity Estimate (GIPE), which measures the extent of undue proximity in word vectors resulting from the presence of gender-based predilections. Experiments based on a suite of evaluation metrics show that RAN-Debias significantly outperforms the state-of-the-art in reducing proximity bias (GIPE) by at least 42.02%. It also reduces direct bias, adding minimal semantic disturbance, and achieves the best performance in a downstream application task (coreference resolution).