 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne to rule them all: Towards Joint Indic Language Hate Speech Detection
Sep 28, 2021

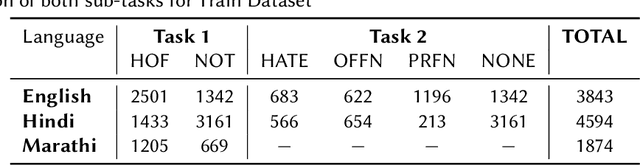
This paper is a contribution to the Hate Speech and Offensive Content Identification in Indo-European Languages (HASOC) 2021 shared task. Social media today is a hotbed of toxic and hateful conversations, in various languages. Recent news reports have shown that current models struggle to automatically identify hate posted in minority languages. Therefore, efficiently curbing hate speech is a critical challenge and problem of interest. We present a multilingual architecture using state-of-the-art transformer language models to jointly learn hate and offensive speech detection across three languages namely, English, Hindi, and Marathi. On the provided testing corpora, we achieve Macro F1 scores of 0.7996, 0.7748, 0.8651 for sub-task 1A and 0.6268, 0.5603 during the fine-grained classification of sub-task 1B. These results show the efficacy of exploiting a multilingual training scheme.
Indic-Transformers: An Analysis of Transformer Language Models for Indian Languages
Nov 04, 2020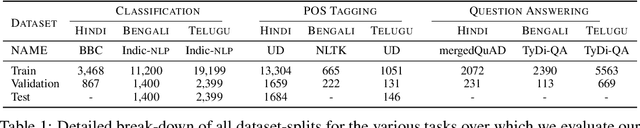
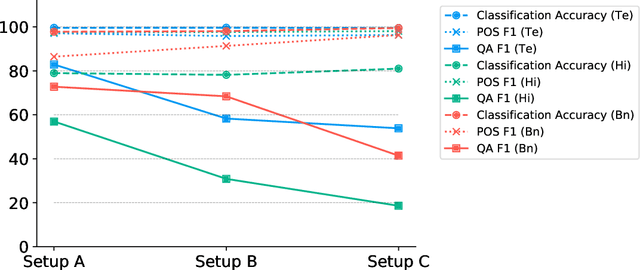
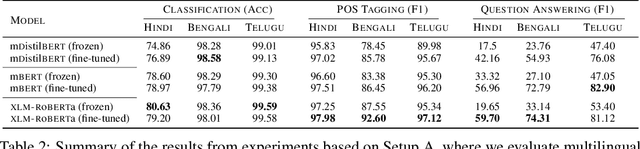

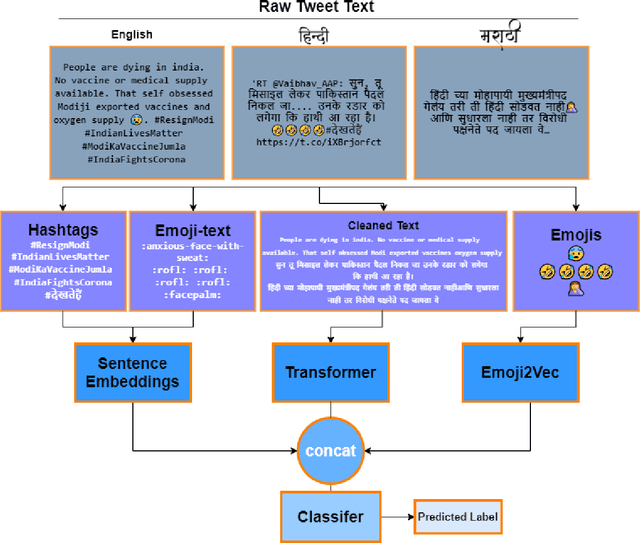
Language models based on the Transformer architecture have achieved state-of-the-art performance on a wide range of NLP tasks such as text classification, question-answering, and token classification. However, this performance is usually tested and reported on high-resource languages, like English, French, Spanish, and German. Indian languages, on the other hand, are underrepresented in such benchmarks. Despite some Indian languages being included in training multilingual Transformer models, they have not been the primary focus of such work. In order to evaluate the performance on Indian languages specifically, we analyze these language models through extensive experiments on multiple downstream tasks in Hindi, Bengali, and Telugu language. Here, we compare the efficacy of fine-tuning model parameters of pre-trained models against that of training a language model from scratch. Moreover, we empirically argue against the strict dependency between the dataset size and model performance, but rather encourage task-specific model and method selection. We achieve state-of-the-art performance on Hindi and Bengali languages for text classification task. Finally, we present effective strategies for handling the modeling of Indian languages and we release our model checkpoints for the community : https://huggingface.co/neuralspace-reverie.
Subword Semantic Hashing for Intent Classification on Small Datasets
Oct 16, 2018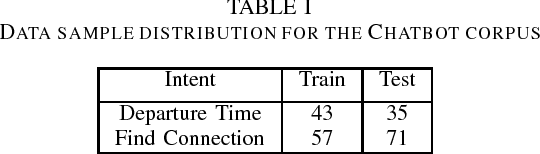

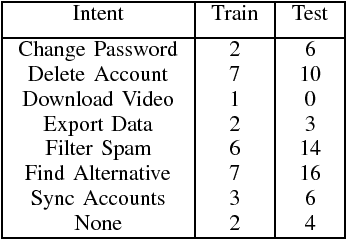
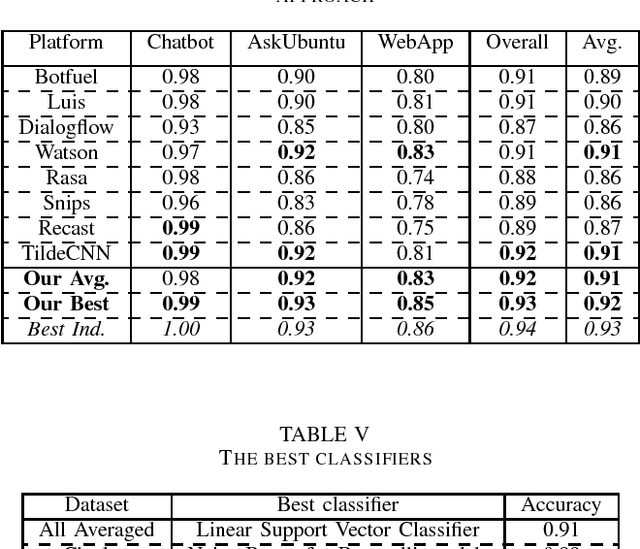
In this paper, we introduce the use of Semantic Hashing as embedding for the task of Intent Classification and outperform previous state-of-the-art methods on three frequently used benchmarks. Intent Classification on a small dataset is a challenging task for data-hungry state-of-the-art Deep Learning based systems. Semantic Hashing is an attempt to overcome such a challenge and learn robust text classification. Current word embedding based methods are dependent on vocabularies. One of the major drawbacks of such methods is out-of-vocabulary terms, especially when having small training datasets and using a wider vocabulary. This is the case in Intent Classification for chatbots, where typically small datasets are extracted from internet communication. Two problems arise by the use of internet communication. First, such datasets miss a lot of terms in the vocabulary to use word embeddings efficiently. Second, users frequently make spelling errors. Typically, the models for intent classification are not trained with spelling errors and it is difficult to think about ways in which users will make mistakes. Models depending on a word vocabulary will always face such issues. An ideal classifier should handle spelling errors inherently. With Semantic Hashing, we overcome these challenges and achieve state-of-the-art results on three datasets: AskUbuntu, Chatbot, and Web Application. Our benchmarks are available online: https://github.com/kumar-shridhar/Know-Your-Intent
TAC-GAN - Text Conditioned Auxiliary Classifier Generative Adversarial Network
Mar 26, 2017
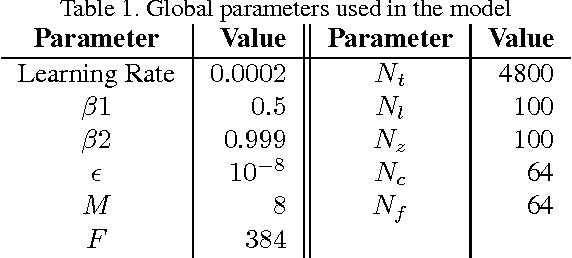
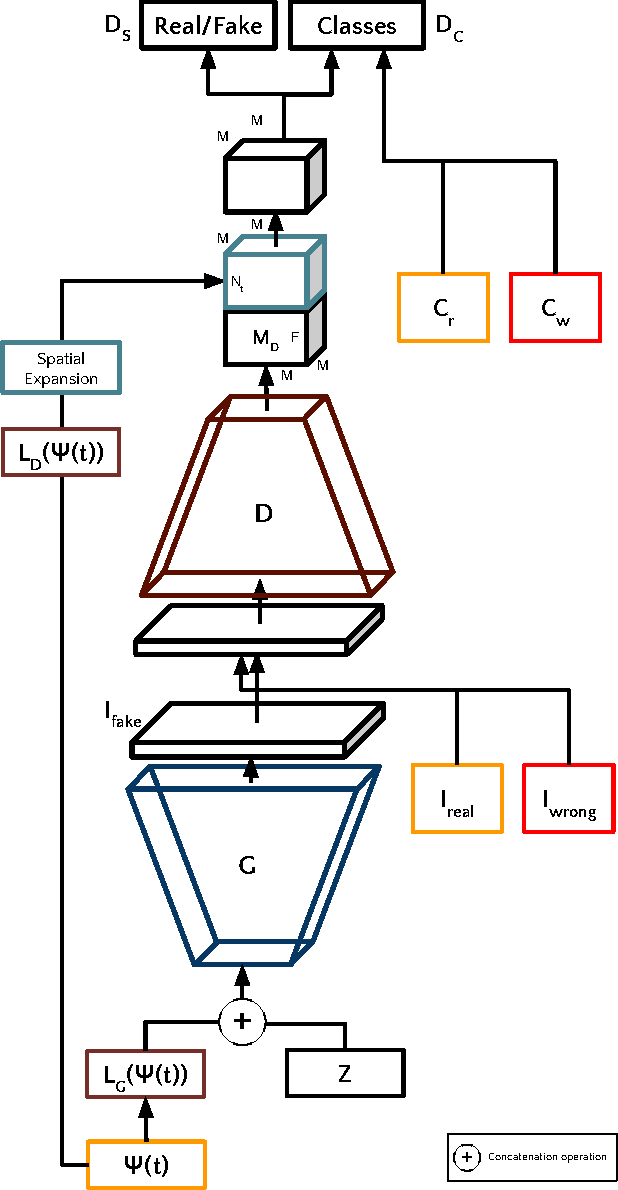

In this work, we present the Text Conditioned Auxiliary Classifier Generative Adversarial Network, (TAC-GAN) a text to image Generative Adversarial Network (GAN) for synthesizing images from their text descriptions. Former approaches have tried to condition the generative process on the textual data; but allying it to the usage of class information, known to diversify the generated samples and improve their structural coherence, has not been explored. We trained the presented TAC-GAN model on the Oxford-102 dataset of flowers, and evaluated the discriminability of the generated images with Inception-Score, as well as their diversity using the Multi-Scale Structural Similarity Index (MS-SSIM). Our approach outperforms the state-of-the-art models, i.e., its inception score is 3.45, corresponding to a relative increase of 7.8% compared to the recently introduced StackGan. A comparison of the mean MS-SSIM scores of the training and generated samples per class shows that our approach is able to generate highly diverse images with an average MS-SSIM of 0.14 over all generated classes.