 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePBP: Path-based Trajectory Prediction for Autonomous Driving
Sep 07, 2023



Trajectory prediction plays a crucial role in the autonomous driving stack by enabling autonomous vehicles to anticipate the motion of surrounding agents. Goal-based prediction models have gained traction in recent years for addressing the multimodal nature of future trajectories. Goal-based prediction models simplify multimodal prediction by first predicting 2D goal locations of agents and then predicting trajectories conditioned on each goal. However, a single 2D goal location serves as a weak inductive bias for predicting the whole trajectory, often leading to poor map compliance, i.e., part of the trajectory going off-road or breaking traffic rules. In this paper, we improve upon goal-based prediction by proposing the Path-based prediction (PBP) approach. PBP predicts a discrete probability distribution over reference paths in the HD map using the path features and predicts trajectories in the path-relative Frenet frame. We applied the PBP trajectory decoder on top of the HiVT scene encoder and report results on the Argoverse dataset. Our experiments show that PBP achieves competitive performance on the standard trajectory prediction metrics, while significantly outperforming state-of-the-art baselines in terms of map compliance.
Indic-Transformers: An Analysis of Transformer Language Models for Indian Languages
Nov 04, 2020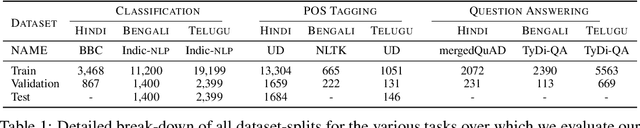
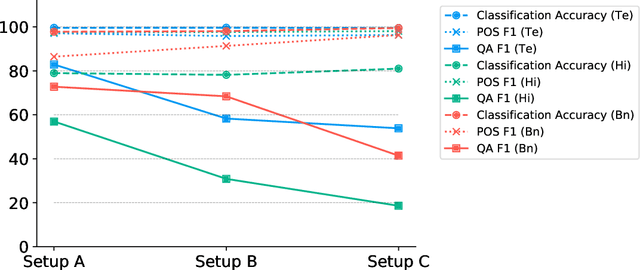
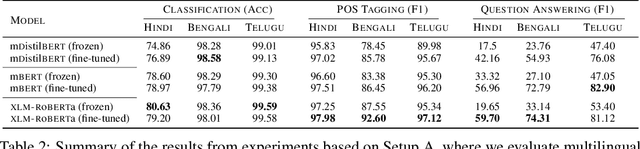

Language models based on the Transformer architecture have achieved state-of-the-art performance on a wide range of NLP tasks such as text classification, question-answering, and token classification. However, this performance is usually tested and reported on high-resource languages, like English, French, Spanish, and German. Indian languages, on the other hand, are underrepresented in such benchmarks. Despite some Indian languages being included in training multilingual Transformer models, they have not been the primary focus of such work. In order to evaluate the performance on Indian languages specifically, we analyze these language models through extensive experiments on multiple downstream tasks in Hindi, Bengali, and Telugu language. Here, we compare the efficacy of fine-tuning model parameters of pre-trained models against that of training a language model from scratch. Moreover, we empirically argue against the strict dependency between the dataset size and model performance, but rather encourage task-specific model and method selection. We achieve state-of-the-art performance on Hindi and Bengali languages for text classification task. Finally, we present effective strategies for handling the modeling of Indian languages and we release our model checkpoints for the community : https://huggingface.co/neuralspace-reverie.