 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUNDO: Understanding Distillation as Optimization
Apr 03, 2025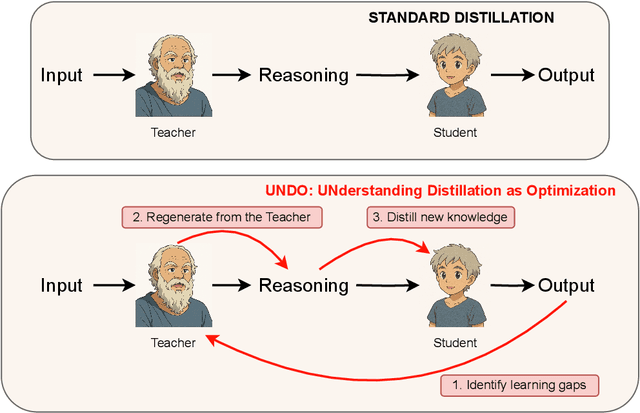
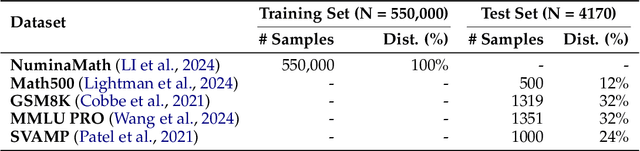
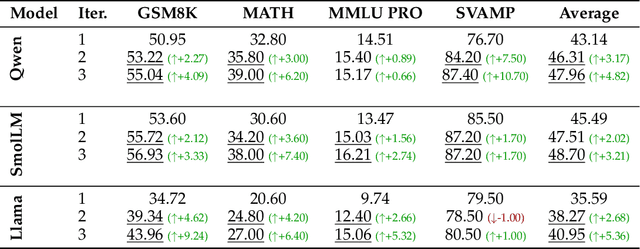
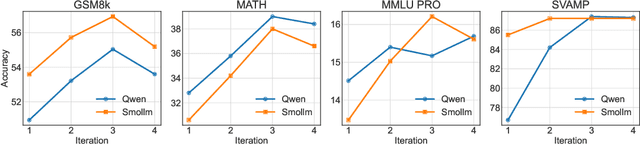
Knowledge distillation has emerged as an effective strategy for compressing large language models' (LLMs) knowledge into smaller, more efficient student models. However, standard one-shot distillation methods often produce suboptimal results due to a mismatch between teacher-generated rationales and the student's specific learning requirements. In this paper, we introduce the UNDO: UNderstanding Distillation as Optimization framework, designed to bridge this gap by iteratively identifying the student's errors and prompting the teacher to refine its explanations accordingly. Each iteration directly targets the student's learning deficiencies, motivating the teacher to provide tailored and enhanced rationales that specifically address these weaknesses. Empirical evaluations on various challenging mathematical and commonsense reasoning tasks demonstrate that our iterative distillation method, UNDO, significantly outperforms standard one-step distillation methods, achieving performance gains of up to 20%. Additionally, we show that teacher-generated data refined through our iterative process remains effective even when applied to different student models, underscoring the broad applicability of our approach. Our work fundamentally reframes knowledge distillation as an iterative teacher-student interaction, effectively leveraging dynamic refinement by the teacher for better knowledge distillation.
First Step Advantage: Importance of Starting Right in Multi-Step Reasoning
Nov 14, 2023


Large Language Models (LLMs) can solve complex reasoning tasks by generating rationales for their predictions. Distilling these capabilities into a smaller, compact model can facilitate the creation of specialized, cost-effective models tailored for specific tasks. However, smaller models often face challenges in complex reasoning tasks and often deviate from the correct reasoning path. We show that LLMs can guide smaller models and bring them back to the correct reasoning path only if they intervene at the right time. We show that smaller models fail to reason primarily due to their difficulty in initiating the process, and that guiding them in the right direction can lead to a performance gain of over 100%. We explore different model sizes and evaluate the benefits of providing guidance to improve reasoning in smaller models.
Face Cartoonisation For Various Poses Using StyleGAN
Sep 26, 2023This paper presents an innovative approach to achieve face cartoonisation while preserving the original identity and accommodating various poses. Unlike previous methods in this field that relied on conditional-GANs, which posed challenges related to dataset requirements and pose training, our approach leverages the expressive latent space of StyleGAN. We achieve this by introducing an encoder that captures both pose and identity information from images and generates a corresponding embedding within the StyleGAN latent space. By subsequently passing this embedding through a pre-trained generator, we obtain the desired cartoonised output. While many other approaches based on StyleGAN necessitate a dedicated and fine-tuned StyleGAN model, our method stands out by utilizing an already-trained StyleGAN designed to produce realistic facial images. We show by extensive experimentation how our encoder adapts the StyleGAN output to better preserve identity when the objective is cartoonisation.
Optimized EEG based mood detection with signal processing and deep neural networks for brain-computer interface
Mar 30, 2023Electroencephalogram (EEG) is a very promising and widely implemented procedure to study brain signals and activities by amplifying and measuring the post-synaptical potential arising from electrical impulses produced by neurons and detected by specialized electrodes attached to specific points in the scalp. It can be studied for detecting brain abnormalities, headaches, and other conditions. However, there are limited studies performed to establish a smart decision-making model to identify EEG's relation with the mood of the subject. In this experiment, EEG signals of 28 healthy human subjects have been observed with consent and attempts have been made to study and recognise moods. Savitzky-Golay band-pass filtering and Independent Component Analysis have been used for data filtration.Different neural network algorithms have been implemented to analyze and classify the EEG data based on the mood of the subject. The model is further optimised by the usage of Blackman window-based Fourier Transformation and extracting the most significant frequencies for each electrode. Using these techniques, up to 96.01% detection accuracy has been obtained.
Learning to Drop Out: An Adversarial Approach to Training Sequence VAEs
Sep 26, 2022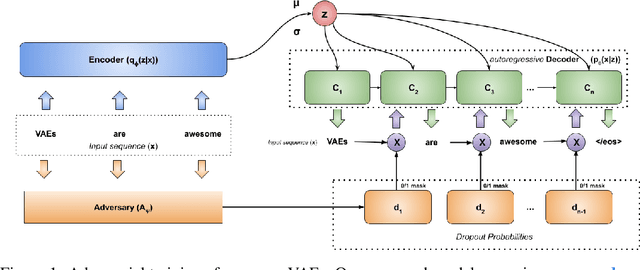
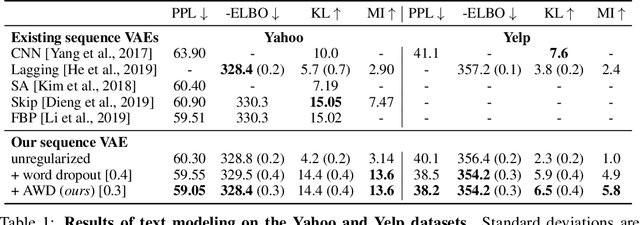
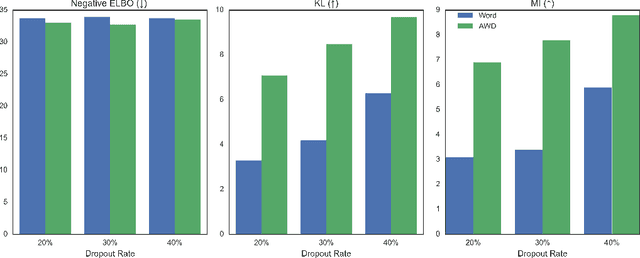

In principle, applying variational autoencoders (VAEs) to sequential data offers a method for controlled sequence generation, manipulation, and structured representation learning. However, training sequence VAEs is challenging: autoregressive decoders can often explain the data without utilizing the latent space, known as posterior collapse. To mitigate this, state-of-the-art models weaken the powerful decoder by applying uniformly random dropout to the decoder input. We show theoretically that this removes pointwise mutual information provided by the decoder input, which is compensated for by utilizing the latent space. We then propose an adversarial training strategy to achieve information-based stochastic dropout. Compared to uniform dropout on standard text benchmark datasets, our targeted approach increases both sequence modeling performance and the information captured in the latent space.
Indic-Transformers: An Analysis of Transformer Language Models for Indian Languages
Nov 04, 2020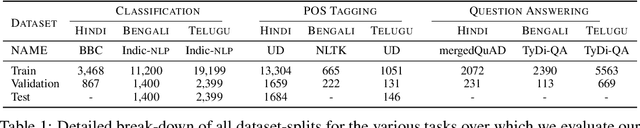
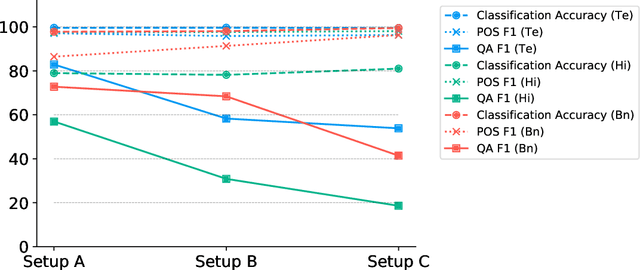
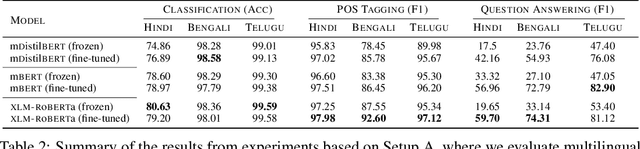

Language models based on the Transformer architecture have achieved state-of-the-art performance on a wide range of NLP tasks such as text classification, question-answering, and token classification. However, this performance is usually tested and reported on high-resource languages, like English, French, Spanish, and German. Indian languages, on the other hand, are underrepresented in such benchmarks. Despite some Indian languages being included in training multilingual Transformer models, they have not been the primary focus of such work. In order to evaluate the performance on Indian languages specifically, we analyze these language models through extensive experiments on multiple downstream tasks in Hindi, Bengali, and Telugu language. Here, we compare the efficacy of fine-tuning model parameters of pre-trained models against that of training a language model from scratch. Moreover, we empirically argue against the strict dependency between the dataset size and model performance, but rather encourage task-specific model and method selection. We achieve state-of-the-art performance on Hindi and Bengali languages for text classification task. Finally, we present effective strategies for handling the modeling of Indian languages and we release our model checkpoints for the community : https://huggingface.co/neuralspace-reverie.