 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Robustness in Machine Learning: A Posterior Agreement Approach
Mar 20, 2025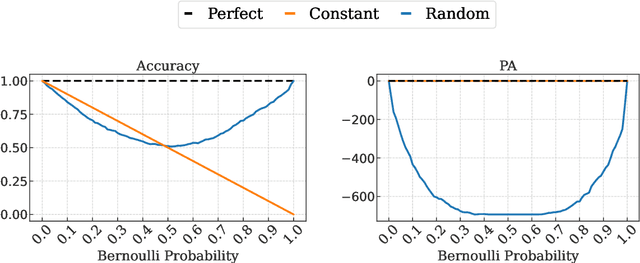

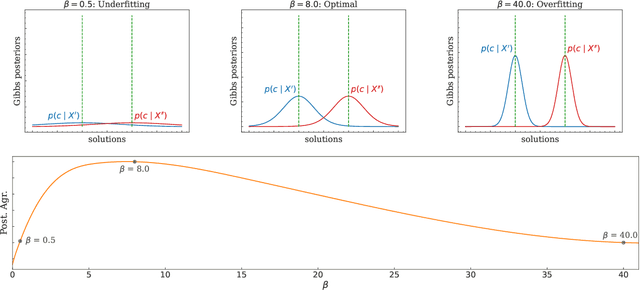

The robustness of algorithms against covariate shifts is a fundamental problem with critical implications for the deployment of machine learning algorithms in the real world. Current evaluation methods predominantly match the robustness definition to that of standard generalization, relying on standard metrics like accuracy-based scores, which, while designed for performance assessment, lack a theoretical foundation encompassing their application in estimating robustness to distribution shifts. In this work, we set the desiderata for a robustness metric, and we propose a novel principled framework for the robustness assessment problem that directly follows the Posterior Agreement (PA) theory of model validation. Specifically, we extend the PA framework to the covariate shift setting by proposing a PA metric for robustness evaluation in supervised classification tasks. We assess the soundness of our metric in controlled environments and through an empirical robustness analysis in two different covariate shift scenarios: adversarial learning and domain generalization. We illustrate the suitability of PA by evaluating several models under different nature and magnitudes of shift, and proportion of affected observations. The results show that the PA metric provides a sensible and consistent analysis of the vulnerabilities in learning algorithms, even in the presence of few perturbed observations.
Learning Causally Invariant Reward Functions from Diverse Demonstrations
Sep 12, 2024
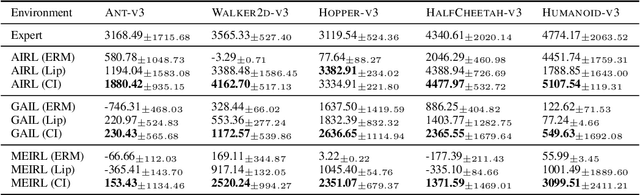

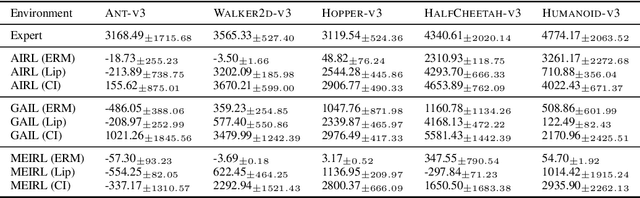
Inverse reinforcement learning methods aim to retrieve the reward function of a Markov decision process based on a dataset of expert demonstrations. The commonplace scarcity and heterogeneous sources of such demonstrations can lead to the absorption of spurious correlations in the data by the learned reward function. Consequently, this adaptation often exhibits behavioural overfitting to the expert data set when a policy is trained on the obtained reward function under distribution shift of the environment dynamics. In this work, we explore a novel regularization approach for inverse reinforcement learning methods based on the causal invariance principle with the goal of improved reward function generalization. By applying this regularization to both exact and approximate formulations of the learning task, we demonstrate superior policy performance when trained using the recovered reward functions in a transfer setting
Measuring Orthogonality in Representations of Generative Models
Jul 04, 2024In unsupervised representation learning, models aim to distill essential features from high-dimensional data into lower-dimensional learned representations, guided by inductive biases. Understanding the characteristics that make a good representation remains a topic of ongoing research. Disentanglement of independent generative processes has long been credited with producing high-quality representations. However, focusing solely on representations that adhere to the stringent requirements of most disentanglement metrics, may result in overlooking many high-quality representations, well suited for various downstream tasks. These metrics often demand that generative factors be encoded in distinct, single dimensions aligned with the canonical basis of the representation space. Motivated by these observations, we propose two novel metrics: Importance-Weighted Orthogonality (IWO) and Importance-Weighted Rank (IWR). These metrics evaluate the mutual orthogonality and rank of generative factor subspaces. Throughout extensive experiments on common downstream tasks, over several benchmark datasets and models, IWO and IWR consistently show stronger correlations with downstream task performance than traditional disentanglement metrics. Our findings suggest that representation quality is closer related to the orthogonality of independent generative processes rather than their disentanglement, offering a new direction for evaluating and improving unsupervised learning models.
Breeding Programs Optimization with Reinforcement Learning
Jun 06, 2024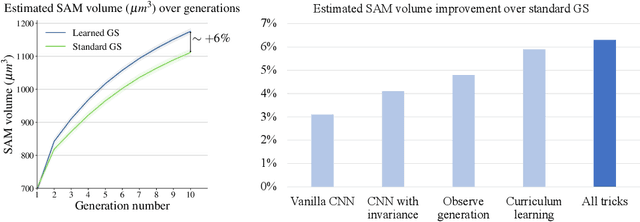
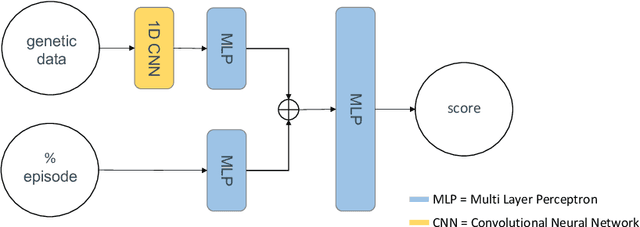
Crop breeding is crucial in improving agricultural productivity while potentially decreasing land usage, greenhouse gas emissions, and water consumption. However, breeding programs are challenging due to long turnover times, high-dimensional decision spaces, long-term objectives, and the need to adapt to rapid climate change. This paper introduces the use of Reinforcement Learning (RL) to optimize simulated crop breeding programs. RL agents are trained to make optimal crop selection and cross-breeding decisions based on genetic information. To benchmark RL-based breeding algorithms, we introduce a suite of Gym environments. The study demonstrates the superiority of RL techniques over standard practices in terms of genetic gain when simulated in silico using real-world genomic maize data.
TAMBRIDGE: Bridging Frame-Centered Tracking and 3D Gaussian Splatting for Enhanced SLAM
May 30, 2024



The limited robustness of 3D Gaussian Splatting (3DGS) to motion blur and camera noise, along with its poor real-time performance, restricts its application in robotic SLAM tasks. Upon analysis, the primary causes of these issues are the density of views with motion blur and the cumulative errors in dense pose estimation from calculating losses based on noisy original images and rendering results, which increase the difficulty of 3DGS rendering convergence. Thus, a cutting-edge 3DGS-based SLAM system is introduced, leveraging the efficiency and flexibility of 3DGS to achieve real-time performance while remaining robust against sensor noise, motion blur, and the challenges posed by long-session SLAM. Central to this approach is the Fusion Bridge module, which seamlessly integrates tracking-centered ORB Visual Odometry with mapping-centered online 3DGS. Precise pose initialization is enabled by this module through joint optimization of re-projection and rendering loss, as well as strategic view selection, enhancing rendering convergence in large-scale scenes. Extensive experiments demonstrate state-of-the-art rendering quality and localization accuracy, positioning this system as a promising solution for real-world robotics applications that require stable, near-real-time performance. Our project is available at https://ZeldaFromHeaven.github.io/TAMBRIDGE/
Point-In-Context: Understanding Point Cloud via In-Context Learning
Apr 18, 2024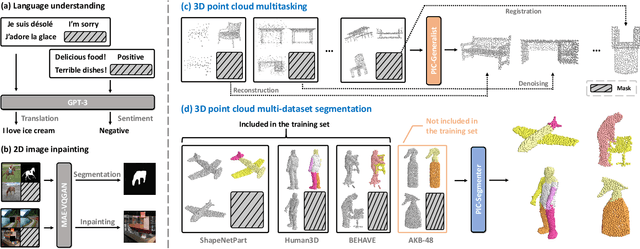
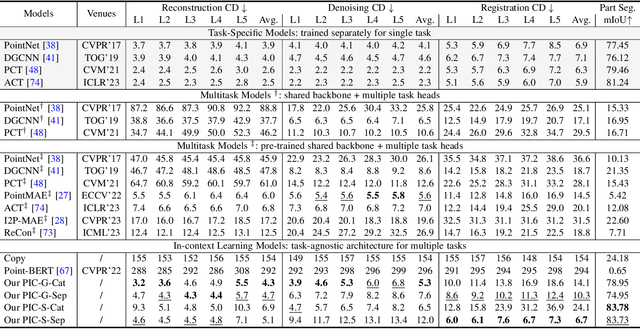
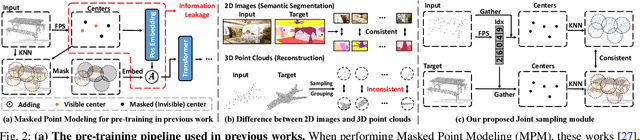
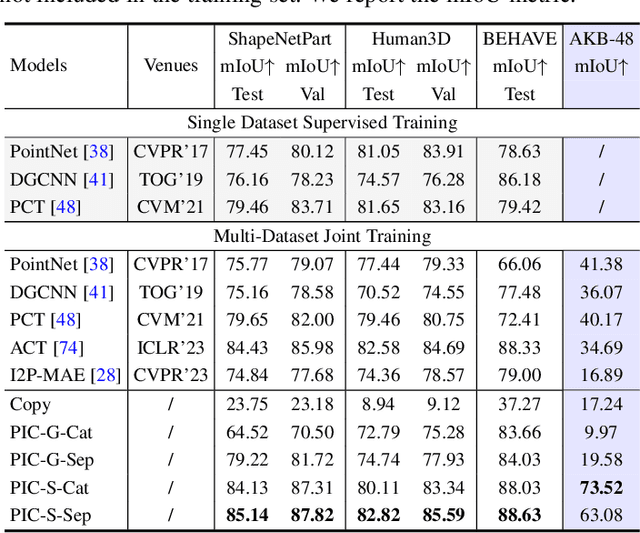
With the emergence of large-scale models trained on diverse datasets, in-context learning has emerged as a promising paradigm for multitasking, notably in natural language processing and image processing. However, its application in 3D point cloud tasks remains largely unexplored. In this work, we introduce Point-In-Context (PIC), a novel framework for 3D point cloud understanding via in-context learning. We address the technical challenge of effectively extending masked point modeling to 3D point clouds by introducing a Joint Sampling module and proposing a vanilla version of PIC called Point-In-Context-Generalist (PIC-G). PIC-G is designed as a generalist model for various 3D point cloud tasks, with inputs and outputs modeled as coordinates. In this paradigm, the challenging segmentation task is achieved by assigning label points with XYZ coordinates for each category; the final prediction is then chosen based on the label point closest to the predictions. To break the limitation by the fixed label-coordinate assignment, which has poor generalization upon novel classes, we propose two novel training strategies, In-Context Labeling and In-Context Enhancing, forming an extended version of PIC named Point-In-Context-Segmenter (PIC-S), targeting improving dynamic context labeling and model training. By utilizing dynamic in-context labels and extra in-context pairs, PIC-S achieves enhanced performance and generalization capability in and across part segmentation datasets. PIC is a general framework so that other tasks or datasets can be seamlessly introduced into our PIC through a unified data format. We conduct extensive experiments to validate the versatility and adaptability of our proposed methods in handling a wide range of tasks and segmenting multi-datasets. Our PIC-S is capable of generalizing unseen datasets and performing novel part segmentation by customizing prompts.
Non-linear Fusion in Federated Learning: A Hypernetwork Approach to Federated Domain Generalization
Feb 13, 2024
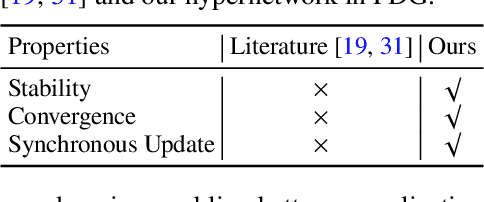
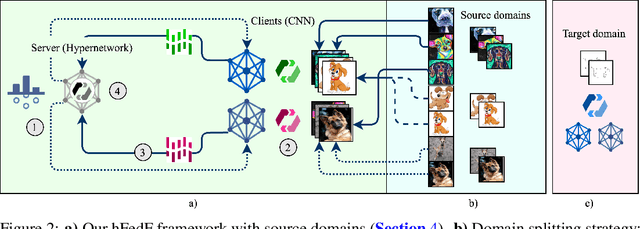
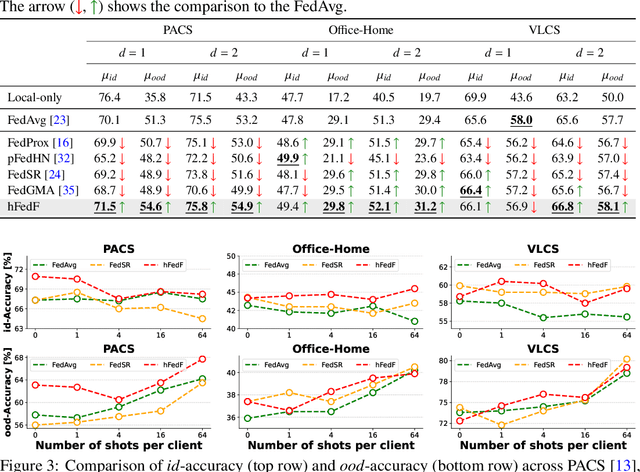
Federated Learning (FL) has emerged as a promising paradigm in which multiple clients collaboratively train a shared global model while preserving data privacy. To create a robust and practicable FL framework, it is crucial to extend its ability to generalize well to unseen domains - a problem referred to as federated Domain Generalization (FDG), being still under-explored. We propose an innovative federated algorithm, termed hFedF for hypernetwork-based Federated Fusion, designed to bridge the performance gap between generalization and personalization, capable of addressing various degrees of domain shift. Essentially, the hypernetwork supports a non-linear fusion of client models enabling a comprehensive understanding of the underlying data distribution. We encompass an extensive discussion and provide novel insights into the tradeoff between personalization and generalization in FL. The proposed algorithm outperforms strong benchmarks on three widely-used data sets for DG in an exceeding number of cases.
Invariant Anomaly Detection under Distribution Shifts: A Causal Perspective
Dec 21, 2023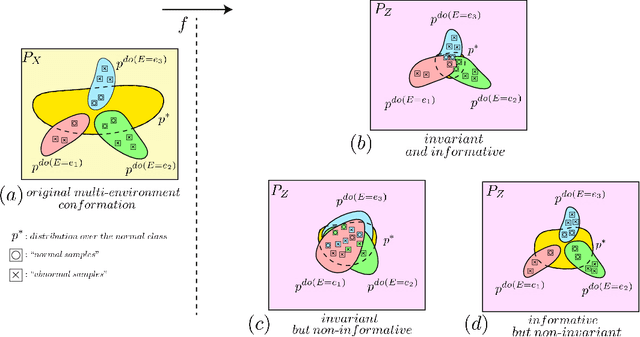
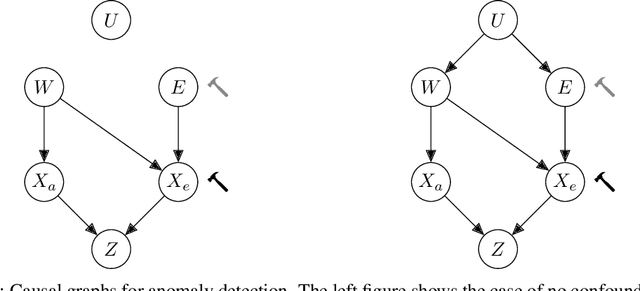
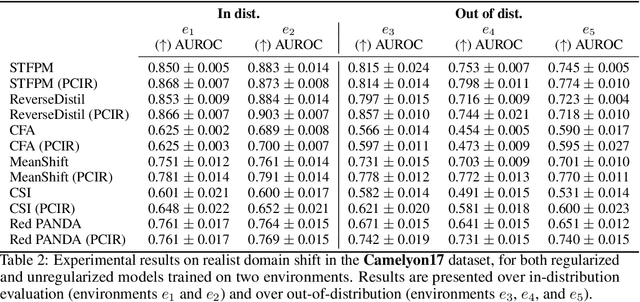
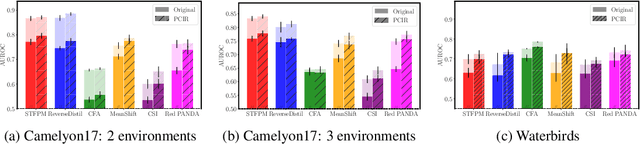
Anomaly detection (AD) is the machine learning task of identifying highly discrepant abnormal samples by solely relying on the consistency of the normal training samples. Under the constraints of a distribution shift, the assumption that training samples and test samples are drawn from the same distribution breaks down. In this work, by leveraging tools from causal inference we attempt to increase the resilience of anomaly detection models to different kinds of distribution shifts. We begin by elucidating a simple yet necessary statistical property that ensures invariant representations, which is critical for robust AD under both domain and covariate shifts. From this property, we derive a regularization term which, when minimized, leads to partial distribution invariance across environments. Through extensive experimental evaluation on both synthetic and real-world tasks, covering a range of six different AD methods, we demonstrated significant improvements in out-of-distribution performance. Under both covariate and domain shift, models regularized with our proposed term showed marked increased robustness. Code is available at: https://github.com/JoaoCarv/invariant-anomaly-detection.
Regularizing Adversarial Imitation Learning Using Causal Invariance
Aug 17, 2023

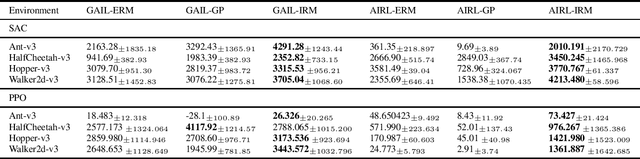
Imitation learning methods are used to infer a policy in a Markov decision process from a dataset of expert demonstrations by minimizing a divergence measure between the empirical state occupancy measures of the expert and the policy. The guiding signal to the policy is provided by the discriminator used as part of an versarial optimization procedure. We observe that this model is prone to absorbing spurious correlations present in the expert data. To alleviate this issue, we propose to use causal invariance as a regularization principle for adversarial training of these models. The regularization objective is applicable in a straightforward manner to existing adversarial imitation frameworks. We demonstrate the efficacy of the regularized formulation in an illustrative two-dimensional setting as well as a number of high-dimensional robot locomotion benchmark tasks.
Improving Explainability of Disentangled Representations using Multipath-Attribution Mappings
Jun 15, 2023Explainable AI aims to render model behavior understandable by humans, which can be seen as an intermediate step in extracting causal relations from correlative patterns. Due to the high risk of possible fatal decisions in image-based clinical diagnostics, it is necessary to integrate explainable AI into these safety-critical systems. Current explanatory methods typically assign attribution scores to pixel regions in the input image, indicating their importance for a model's decision. However, they fall short when explaining why a visual feature is used. We propose a framework that utilizes interpretable disentangled representations for downstream-task prediction. Through visualizing the disentangled representations, we enable experts to investigate possible causation effects by leveraging their domain knowledge. Additionally, we deploy a multi-path attribution mapping for enriching and validating explanations. We demonstrate the effectiveness of our approach on a synthetic benchmark suite and two medical datasets. We show that the framework not only acts as a catalyst for causal relation extraction but also enhances model robustness by enabling shortcut detection without the need for testing under distribution shifts.