 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Causally Invariant Reward Functions from Diverse Demonstrations
Paper and Code
Sep 12, 2024
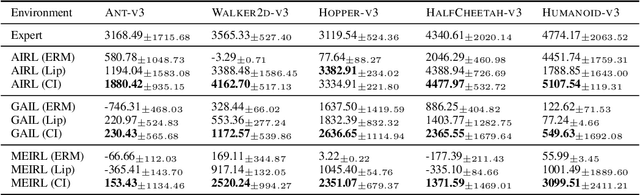

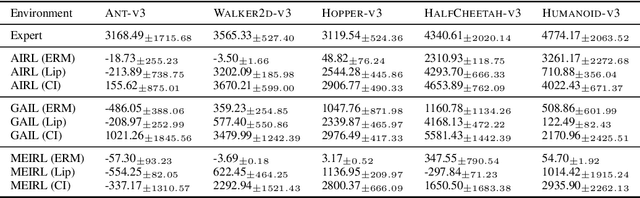
Inverse reinforcement learning methods aim to retrieve the reward function of a Markov decision process based on a dataset of expert demonstrations. The commonplace scarcity and heterogeneous sources of such demonstrations can lead to the absorption of spurious correlations in the data by the learned reward function. Consequently, this adaptation often exhibits behavioural overfitting to the expert data set when a policy is trained on the obtained reward function under distribution shift of the environment dynamics. In this work, we explore a novel regularization approach for inverse reinforcement learning methods based on the causal invariance principle with the goal of improved reward function generalization. By applying this regularization to both exact and approximate formulations of the learning task, we demonstrate superior policy performance when trained using the recovered reward functions in a transfer setting