 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Causally Invariant Reward Functions from Diverse Demonstrations
Sep 12, 2024
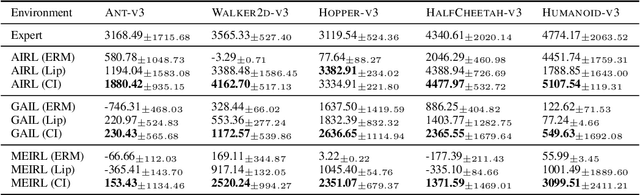

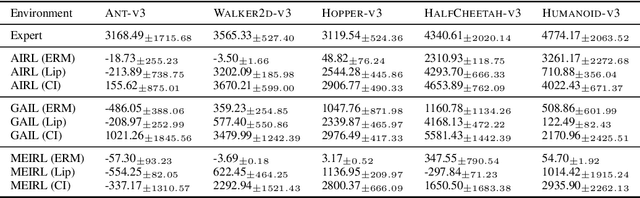
Inverse reinforcement learning methods aim to retrieve the reward function of a Markov decision process based on a dataset of expert demonstrations. The commonplace scarcity and heterogeneous sources of such demonstrations can lead to the absorption of spurious correlations in the data by the learned reward function. Consequently, this adaptation often exhibits behavioural overfitting to the expert data set when a policy is trained on the obtained reward function under distribution shift of the environment dynamics. In this work, we explore a novel regularization approach for inverse reinforcement learning methods based on the causal invariance principle with the goal of improved reward function generalization. By applying this regularization to both exact and approximate formulations of the learning task, we demonstrate superior policy performance when trained using the recovered reward functions in a transfer setting
How to Enable Uncertainty Estimation in Proximal Policy Optimization
Oct 07, 2022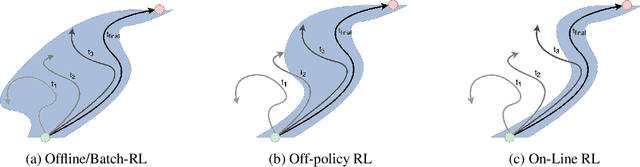
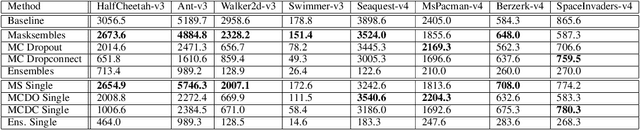
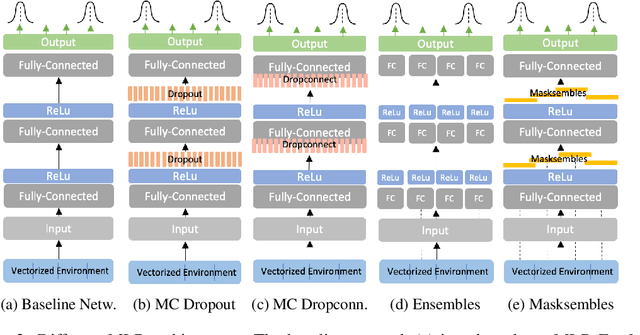
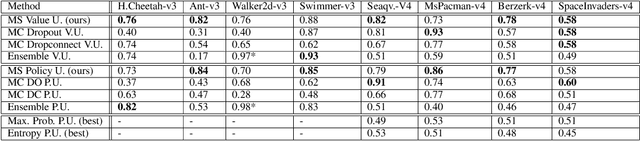
While deep reinforcement learning (RL) agents have showcased strong results across many domains, a major concern is their inherent opaqueness and the safety of such systems in real-world use cases. To overcome these issues, we need agents that can quantify their uncertainty and detect out-of-distribution (OOD) states. Existing uncertainty estimation techniques, like Monte-Carlo Dropout or Deep Ensembles, have not seen widespread adoption in on-policy deep RL. We posit that this is due to two reasons: concepts like uncertainty and OOD states are not well defined compared to supervised learning, especially for on-policy RL methods. Secondly, available implementations and comparative studies for uncertainty estimation methods in RL have been limited. To overcome the first gap, we propose definitions of uncertainty and OOD for Actor-Critic RL algorithms, namely, proximal policy optimization (PPO), and present possible applicable measures. In particular, we discuss the concepts of value and policy uncertainty. The second point is addressed by implementing different uncertainty estimation methods and comparing them across a number of environments. The OOD detection performance is evaluated via a custom evaluation benchmark of in-distribution (ID) and OOD states for various RL environments. We identify a trade-off between reward and OOD detection performance. To overcome this, we formulate a Pareto optimization problem in which we simultaneously optimize for reward and OOD detection performance. We show experimentally that the recently proposed method of Masksembles strikes a favourable balance among the survey methods, enabling high-quality uncertainty estimation and OOD detection while matching the performance of original RL agents.
BARReL: Bottleneck Attention for Adversarial Robustness in Vision-Based Reinforcement Learning
Aug 22, 2022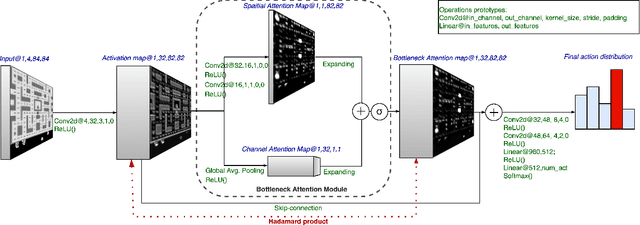



Robustness to adversarial perturbations has been explored in many areas of computer vision. This robustness is particularly relevant in vision-based reinforcement learning, as the actions of autonomous agents might be safety-critic or impactful in the real world. We investigate the susceptibility of vision-based reinforcement learning agents to gradient-based adversarial attacks and evaluate a potential defense. We observe that Bottleneck Attention Modules (BAM) included in CNN architectures can act as potential tools to increase robustness against adversarial attacks. We show how learned attention maps can be used to recover activations of a convolutional layer by restricting the spatial activations to salient regions. Across a number of RL environments, BAM-enhanced architectures show increased robustness during inference. Finally, we discuss potential future research directions.
Inverse Reinforcement Learning via Matching of Optimality Profiles
Nov 19, 2020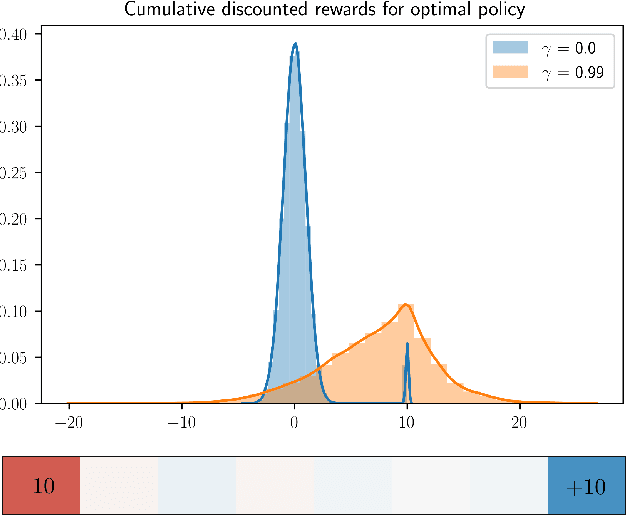
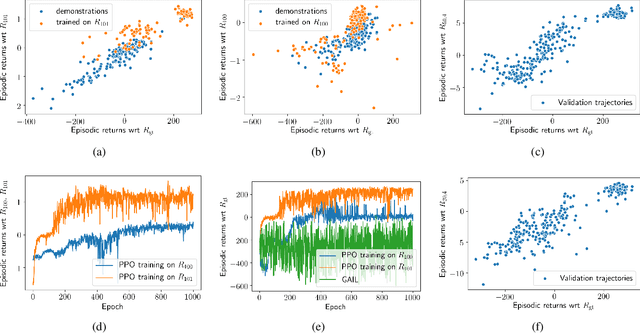
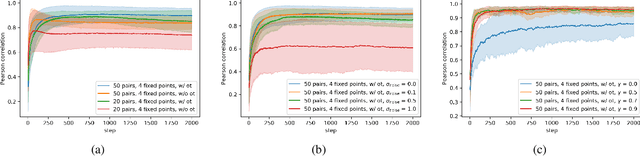

The goal of inverse reinforcement learning (IRL) is to infer a reward function that explains the behavior of an agent performing a task. The assumption that most approaches make is that the demonstrated behavior is near-optimal. In many real-world scenarios, however, examples of truly optimal behavior are scarce, and it is desirable to effectively leverage sets of demonstrations of suboptimal or heterogeneous performance, which are easier to obtain. We propose an algorithm that learns a reward function from such demonstrations together with a weak supervision signal in the form of a distribution over rewards collected during the demonstrations (or, more generally, a distribution over cumulative discounted future rewards). We view such distributions, which we also refer to as optimality profiles, as summaries of the degree of optimality of the demonstrations that may, for example, reflect the opinion of a human expert. Given an optimality profile and a small amount of additional supervision, our algorithm fits a reward function, modeled as a neural network, by essentially minimizing the Wasserstein distance between the corresponding induced distribution and the optimality profile. We show that our method is capable of learning reward functions such that policies trained to optimize them outperform the demonstrations used for fitting the reward functions.