 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInverse Reinforcement Learning via Matching of Optimality Profiles
Nov 19, 2020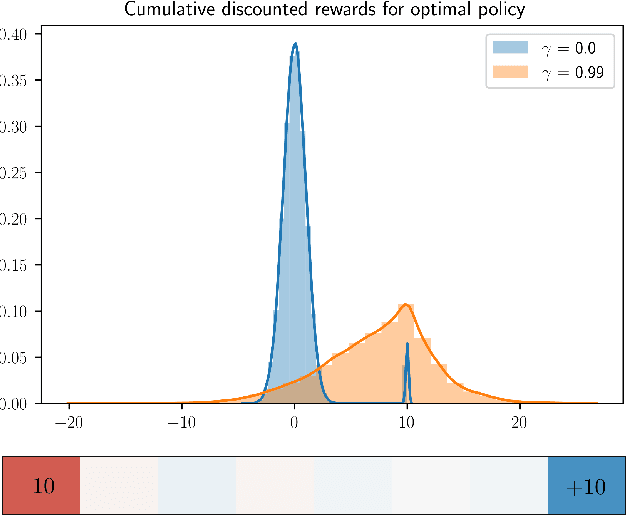
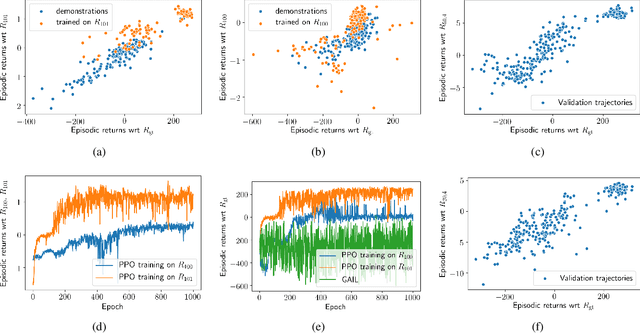
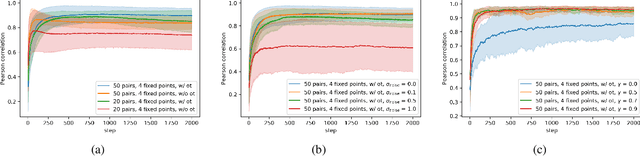

The goal of inverse reinforcement learning (IRL) is to infer a reward function that explains the behavior of an agent performing a task. The assumption that most approaches make is that the demonstrated behavior is near-optimal. In many real-world scenarios, however, examples of truly optimal behavior are scarce, and it is desirable to effectively leverage sets of demonstrations of suboptimal or heterogeneous performance, which are easier to obtain. We propose an algorithm that learns a reward function from such demonstrations together with a weak supervision signal in the form of a distribution over rewards collected during the demonstrations (or, more generally, a distribution over cumulative discounted future rewards). We view such distributions, which we also refer to as optimality profiles, as summaries of the degree of optimality of the demonstrations that may, for example, reflect the opinion of a human expert. Given an optimality profile and a small amount of additional supervision, our algorithm fits a reward function, modeled as a neural network, by essentially minimizing the Wasserstein distance between the corresponding induced distribution and the optimality profile. We show that our method is capable of learning reward functions such that policies trained to optimize them outperform the demonstrations used for fitting the reward functions.
Semantic Segmentation of Histopathological Slides for the Classification of Cutaneous Lymphoma and Eczema
Sep 10, 2020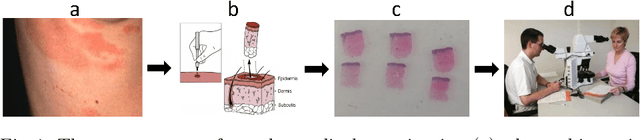
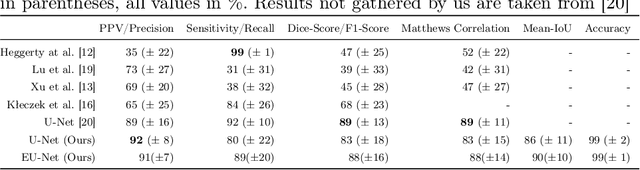
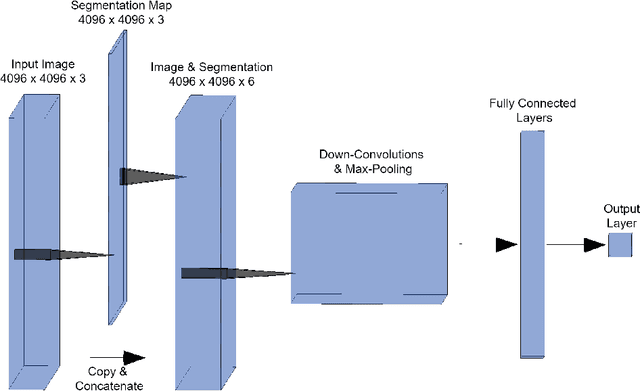

Mycosis fungoides (MF) is a rare, potentially life threatening skin disease, which in early stages clinically and histologically strongly resembles Eczema, a very common and benign skin condition. In order to increase the survival rate, one needs to provide the appropriate treatment early on. To this end, one crucial step for specialists is the evaluation of histopathological slides (glass slides), or Whole Slide Images (WSI), of the patients' skin tissue. We introduce a deep learning aided diagnostics tool that brings a two-fold value to the decision process of pathologists. First, our algorithm accurately segments WSI into regions that are relevant for an accurate diagnosis, achieving a Mean-IoU of 69% and a Matthews Correlation score of 83% on a novel dataset. Additionally, we also show that our model is competitive with the state of the art on a reference dataset. Second, using the segmentation map and the original image, we are able to predict if a patient has MF or Eczema. We created two models that can be applied in different stages of the diagnostic pipeline, potentially eliminating life-threatening mistakes. The classification outcome is considerably more interpretable than using only the WSI as the input, since it is also based on the segmentation map. Our segmentation model, which we call EU-Net, extends a classical U-Net with an EfficientNet-B7 encoder which was pre-trained on the Imagenet dataset.
* Submitted to https://link.springer.com/chapter/10.1007/978-3-030-52791-4_3
Understanding the Power and Limitations of Teaching with Imperfect Knowledge
Mar 21, 2020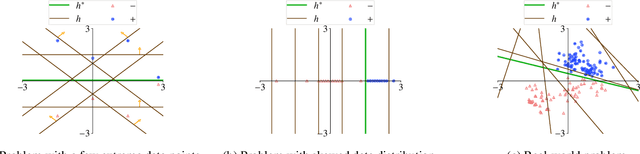
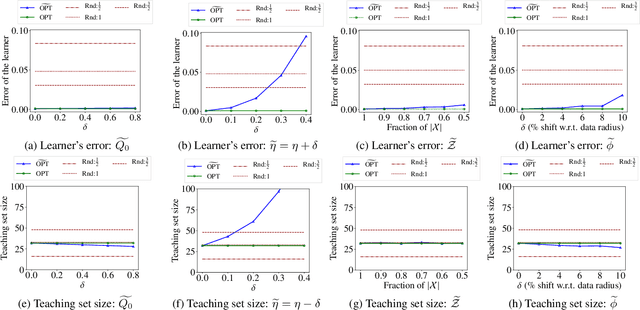
Machine teaching studies the interaction between a teacher and a student/learner where the teacher selects training examples for the learner to learn a specific task. The typical assumption is that the teacher has perfect knowledge of the task---this knowledge comprises knowing the desired learning target, having the exact task representation used by the learner, and knowing the parameters capturing the learning dynamics of the learner. Inspired by real-world applications of machine teaching in education, we consider the setting where teacher's knowledge is limited and noisy, and the key research question we study is the following: When does a teacher succeed or fail in effectively teaching a learner using its imperfect knowledge? We answer this question by showing connections to how imperfect knowledge affects the teacher's solution of the corresponding machine teaching problem when constructing optimal teaching sets. Our results have important implications for designing robust teaching algorithms for real-world applications.
Learner-aware Teaching: Inverse Reinforcement Learning with Preferences and Constraints
Jun 02, 2019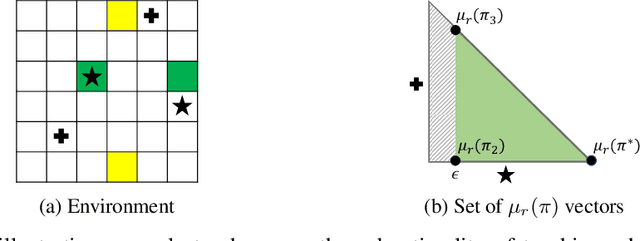

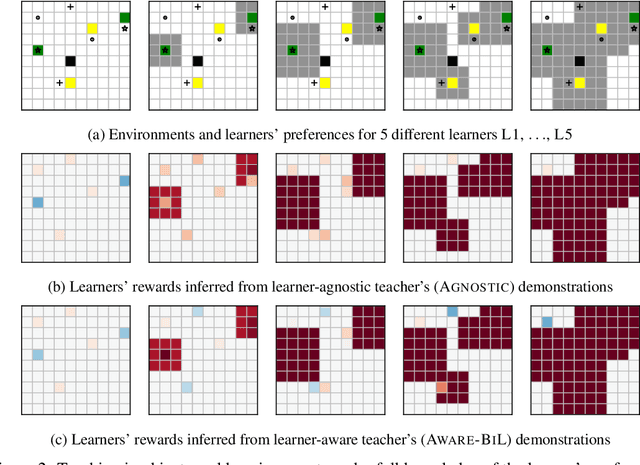

Inverse reinforcement learning (IRL) enables an agent to learn complex behavior by observing demonstrations from a (near-)optimal policy. The typical assumption is that the learner's goal is to match the teacher's demonstrated behavior. In this paper, we consider the setting where the learner has her own preferences that she additionally takes into consideration. These preferences can for example capture behavioral biases, mismatched worldviews, or physical constraints. We study two teaching approaches: learner-agnostic teaching, where the teacher provides demonstrations from an optimal policy ignoring the learner's preferences, and learner-aware teaching, where the teacher accounts for the learner's preferences. We design learner-aware teaching algorithms and show that significant performance improvements can be achieved over learner-agnostic teaching.
Teaching Inverse Reinforcement Learners via Features and Demonstrations
Oct 23, 2018

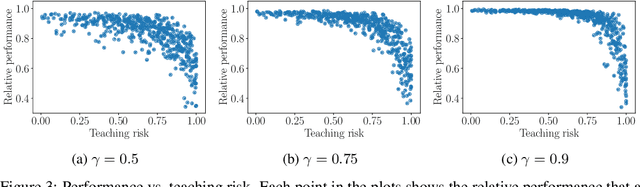
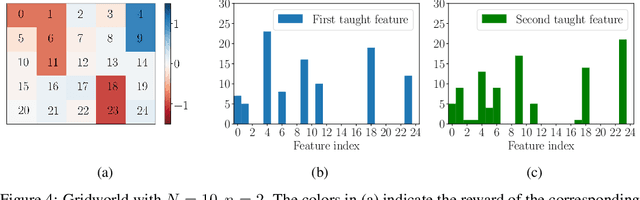
Learning near-optimal behaviour from an expert's demonstrations typically relies on the assumption that the learner knows the features that the true reward function depends on. In this paper, we study the problem of learning from demonstrations in the setting where this is not the case, i.e., where there is a mismatch between the worldviews of the learner and the expert. We introduce a natural quantity, the teaching risk, which measures the potential suboptimality of policies that look optimal to the learner in this setting. We show that bounds on the teaching risk guarantee that the learner is able to find a near-optimal policy using standard algorithms based on inverse reinforcement learning. Based on these findings, we suggest a teaching scheme in which the expert can decrease the teaching risk by updating the learner's worldview, and thus ultimately enable her to find a near-optimal policy.