 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreeTalk: Emotional Topology-Free 3D Talking Heads
Mar 16, 2026Speech-driven 3D facial animation has advanced rapidly, yet most approaches remain tied to registered template meshes, preventing effective deployment on raw 3D scans with arbitrary topology. At the same time, modeling controllable emotional dynamics beyond lip articulation remains challenging, and is often tied to template-based parameterizations. We address these challenges by proposing FreeTalk, a two-stage framework for emotion-conditioned 3D talking-head animation that generalizes to unregistered face meshes with arbitrary vertex count and connectivity. First, Audio-To-Sparse (ATS) predicts a temporally coherent sequence of 3D landmark displacements from speech audio, conditioned on an emotion category and intensity. This sparse representation captures both articulatory and affective motion while remaining independent of mesh topology. Second, Sparse-To-Mesh (STM) transfers the predicted landmark motion to a target mesh by combining intrinsic surface features with landmark-to-vertex conditioning, producing dense per-vertex deformations without template fitting or correspondence supervision at test time. Extensive experiments show that FreeTalk matches specialized baselines when trained in-domain, while providing substantially improved robustness to unseen identities and mesh topologies. Code and pre-trained models will be made publicly available.
Revisiting Emotions Representation for Recognition in the Wild
Feb 06, 2026Facial emotion recognition has been typically cast as a single-label classification problem of one out of six prototypical emotions. However, that is an oversimplification that is unsuitable for representing the multifaceted spectrum of spontaneous emotional states, which are most often the result of a combination of multiple emotions contributing at different intensities. Building on this, a promising direction that was explored recently is to cast emotion recognition as a distribution learning problem. Still, such approaches are limited in that research datasets are typically annotated with a single emotion class. In this paper, we contribute a novel approach to describe complex emotional states as probability distributions over a set of emotion classes. To do so, we propose a solution to automatically re-label existing datasets by exploiting the result of a study in which a large set of both basic and compound emotions is mapped to probability distributions in the Valence-Arousal-Dominance (VAD) space. In this way, given a face image annotated with VAD values, we can estimate the likelihood of it belonging to each of the distributions, so that emotional states can be described as a mixture of emotions, enriching their description, while also accounting for the ambiguous nature of their perception. In a preliminary set of experiments, we illustrate the advantages of this solution and a new possible direction of investigation. Data annotations are available at https://github.com/jbcnrlz/affectnet-b-annotation.
3D Face Reconstruction Error Decomposed: A Modular Benchmark for Fair and Fast Method Evaluation
May 23, 2025Computing the standard benchmark metric for 3D face reconstruction, namely geometric error, requires a number of steps, such as mesh cropping, rigid alignment, or point correspondence. Current benchmark tools are monolithic (they implement a specific combination of these steps), even though there is no consensus on the best way to measure error. We present a toolkit for a Modularized 3D Face reconstruction Benchmark (M3DFB), where the fundamental components of error computation are segregated and interchangeable, allowing one to quantify the effect of each. Furthermore, we propose a new component, namely correction, and present a computationally efficient approach that penalizes for mesh topology inconsistency. Using this toolkit, we test 16 error estimators with 10 reconstruction methods on two real and two synthetic datasets. Critically, the widely used ICP-based estimator provides the worst benchmarking performance, as it significantly alters the true ranking of the top-5 reconstruction methods. Notably, the correlation of ICP with the true error can be as low as 0.41. Moreover, non-rigid alignment leads to significant improvement (correlation larger than 0.90), highlighting the importance of annotating 3D landmarks on datasets. Finally, the proposed correction scheme, together with non-rigid warping, leads to an accuracy on a par with the best non-rigid ICP-based estimators, but runs an order of magnitude faster. Our open-source codebase is designed for researchers to easily compare alternatives for each component, thus helping accelerating progress in benchmarking for 3D face reconstruction and, furthermore, supporting the improvement of learned reconstruction methods, which depend on accurate error estimation for effective training.
U-Shape Mamba: State Space Model for faster diffusion
Apr 18, 2025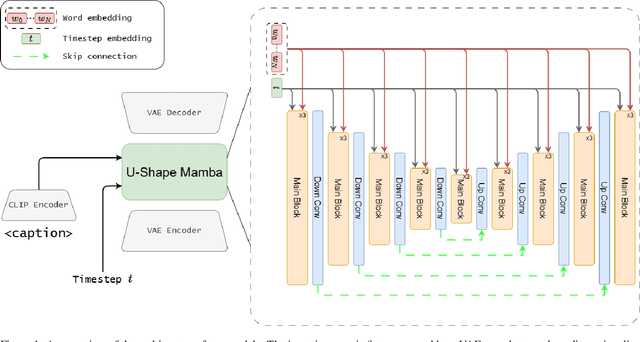

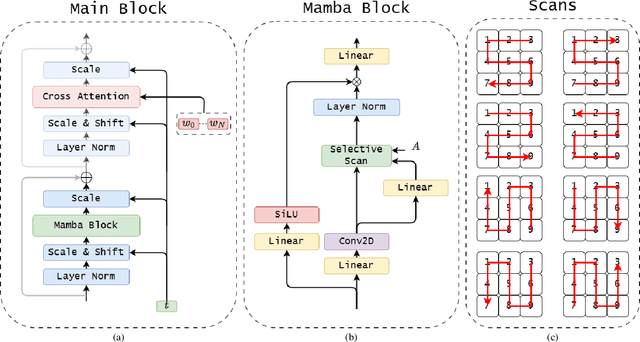

Diffusion models have become the most popular approach for high-quality image generation, but their high computational cost still remains a significant challenge. To address this problem, we propose U-Shape Mamba (USM), a novel diffusion model that leverages Mamba-based layers within a U-Net-like hierarchical structure. By progressively reducing sequence length in the encoder and restoring it in the decoder through Mamba blocks, USM significantly lowers computational overhead while maintaining strong generative capabilities. Experimental results against Zigma, which is currently the most efficient Mamba-based diffusion model, demonstrate that USM achieves one-third the GFlops, requires less memory and is faster, while outperforming Zigma in image quality. Frechet Inception Distance (FID) is improved by 15.3, 0.84 and 2.7 points on AFHQ, CelebAHQ and COCO datasets, respectively. These findings highlight USM as a highly efficient and scalable solution for diffusion-based generative models, making high-quality image synthesis more accessible to the research community while reducing computational costs.
$^R$FLAV: Rolling Flow matching for infinite Audio Video generation
Mar 12, 2025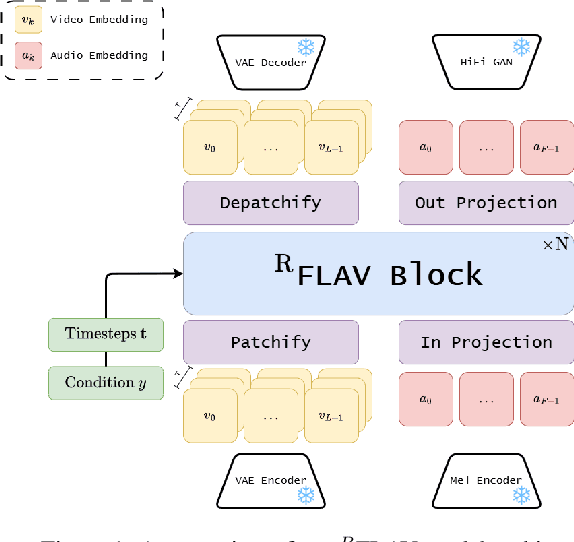

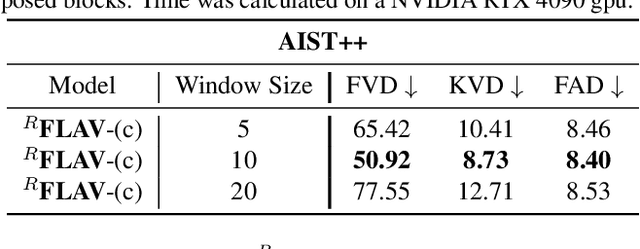

Joint audio-video (AV) generation is still a significant challenge in generative AI, primarily due to three critical requirements: quality of the generated samples, seamless multimodal synchronization and temporal coherence, with audio tracks that match the visual data and vice versa, and limitless video duration. In this paper, we present $^R$-FLAV, a novel transformer-based architecture that addresses all the key challenges of AV generation. We explore three distinct cross modality interaction modules, with our lightweight temporal fusion module emerging as the most effective and computationally efficient approach for aligning audio and visual modalities. Our experimental results demonstrate that $^R$-FLAV outperforms existing state-of-the-art models in multimodal AV generation tasks. Our code and checkpoints are available at https://github.com/ErgastiAlex/R-FLAV.
Spatio-temporal Transformers for Action Unit Classification with Event Cameras
Oct 29, 2024



Face analysis has been studied from different angles to infer emotion, poses, shapes, and landmarks. Traditionally RGB cameras are used, yet for fine-grained tasks standard sensors might not be up to the task due to their latency, making it impossible to record and detect micro-movements that carry a highly informative signal, which is necessary for inferring the true emotions of a subject. Event cameras have been increasingly gaining interest as a possible solution to this and similar high-frame rate tasks. We propose a novel spatiotemporal Vision Transformer model that uses Shifted Patch Tokenization (SPT) and Locality Self-Attention (LSA) to enhance the accuracy of Action Unit classification from event streams. We also address the lack of labeled event data in the literature, which can be considered one of the main causes of an existing gap between the maturity of RGB and neuromorphic vision models. Gathering data is harder in the event domain since it cannot be crawled from the web and labeling frames should take into account event aggregation rates and the fact that static parts might not be visible in certain frames. To this end, we present FACEMORPHIC, a temporally synchronized multimodal face dataset composed of RGB videos and event streams. The dataset is annotated at a video level with facial Action Units and contains streams collected with various possible applications, ranging from 3D shape estimation to lip-reading. We then show how temporal synchronization can allow effective neuromorphic face analysis without the need to manually annotate videos: we instead leverage cross-modal supervision bridging the domain gap by representing face shapes in a 3D space. Our proposed model outperforms baseline methods by effectively capturing spatial and temporal information, crucial for recognizing subtle facial micro-expressions.
Beyond Fixed Topologies: Unregistered Training and Comprehensive Evaluation Metrics for 3D Talking Heads
Oct 14, 2024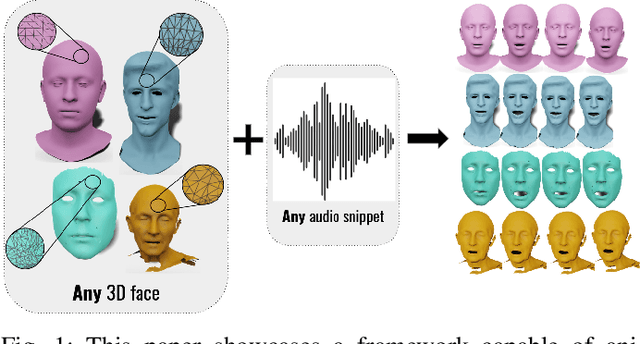
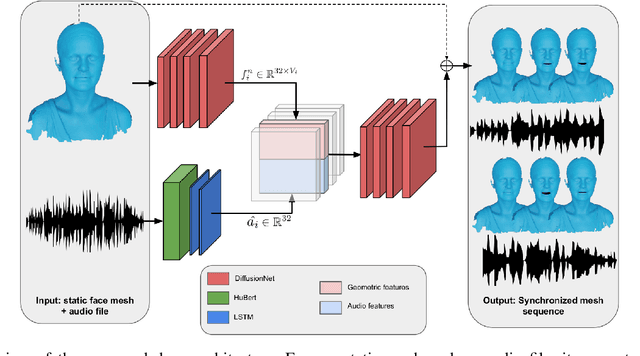
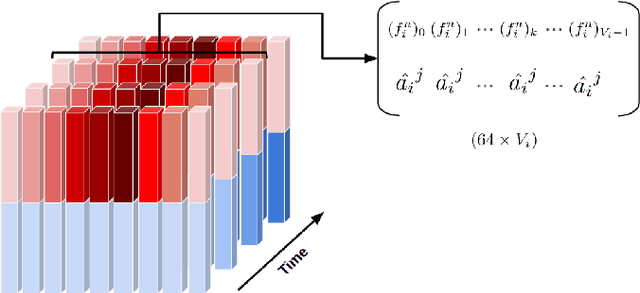

Generating speech-driven 3D talking heads presents numerous challenges; among those is dealing with varying mesh topologies. Existing methods require a registered setting, where all meshes share a common topology: a point-wise correspondence across all meshes the model can animate. While simplifying the problem, it limits applicability as unseen meshes must adhere to the training topology. This work presents a framework capable of animating 3D faces in arbitrary topologies, including real scanned data. Our approach relies on a model leveraging heat diffusion over meshes to overcome the fixed topology constraint. We explore two training settings: a supervised one, in which training sequences share a fixed topology within a sequence but any mesh can be animated at test time, and an unsupervised one, which allows effective training with varying mesh structures. Additionally, we highlight the limitations of current evaluation metrics and propose new metrics for better lip-syncing evaluation between speech and facial movements. Our extensive evaluation shows our approach performs favorably compared to fixed topology techniques, setting a new benchmark by offering a versatile and high-fidelity solution for 3D talking head generation.
Mamba-ST: State Space Model for Efficient Style Transfer
Sep 16, 2024
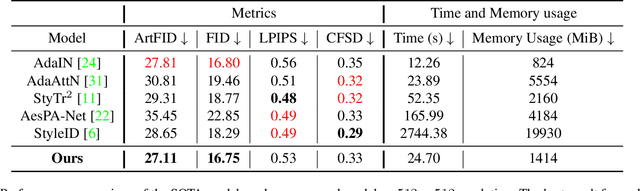
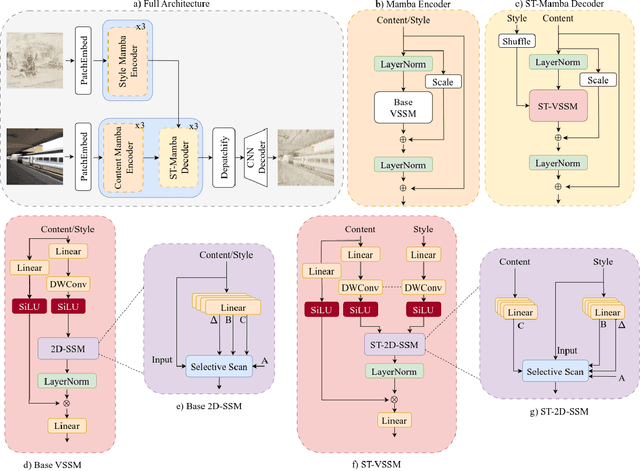
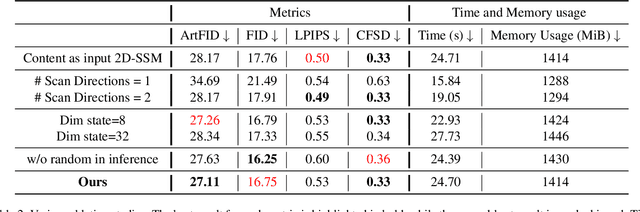
The goal of style transfer is, given a content image and a style source, generating a new image preserving the content but with the artistic representation of the style source. Most of the state-of-the-art architectures use transformers or diffusion-based models to perform this task, despite the heavy computational burden that they require. In particular, transformers use self- and cross-attention layers which have large memory footprint, while diffusion models require high inference time. To overcome the above, this paper explores a novel design of Mamba, an emergent State-Space Model (SSM), called Mamba-ST, to perform style transfer. To do so, we adapt Mamba linear equation to simulate the behavior of cross-attention layers, which are able to combine two separate embeddings into a single output, but drastically reducing memory usage and time complexity. We modified the Mamba's inner equations so to accept inputs from, and combine, two separate data streams. To the best of our knowledge, this is the first attempt to adapt the equations of SSMs to a vision task like style transfer without requiring any other module like cross-attention or custom normalization layers. An extensive set of experiments demonstrates the superiority and efficiency of our method in performing style transfer compared to transformers and diffusion models. Results show improved quality in terms of both ArtFID and FID metrics. Code is available at https://github.com/FilippoBotti/MambaST.
Neuromorphic Facial Analysis with Cross-Modal Supervision
Sep 16, 2024



Traditional approaches for analyzing RGB frames are capable of providing a fine-grained understanding of a face from different angles by inferring emotions, poses, shapes, landmarks. However, when it comes to subtle movements standard RGB cameras might fall behind due to their latency, making it hard to detect micro-movements that carry highly informative cues to infer the true emotions of a subject. To address this issue, the usage of event cameras to analyze faces is gaining increasing interest. Nonetheless, all the expertise matured for RGB processing is not directly transferrable to neuromorphic data due to a strong domain shift and intrinsic differences in how data is represented. The lack of labeled data can be considered one of the main causes of this gap, yet gathering data is harder in the event domain since it cannot be crawled from the web and labeling frames should take into account event aggregation rates and the fact that static parts might not be visible in certain frames. In this paper, we first present FACEMORPHIC, a multimodal temporally synchronized face dataset comprising both RGB videos and event streams. The data is labeled at a video level with facial Action Units and also contains streams collected with a variety of applications in mind, ranging from 3D shape estimation to lip-reading. We then show how temporal synchronization can allow effective neuromorphic face analysis without the need to manually annotate videos: we instead leverage cross-modal supervision bridging the domain gap by representing face shapes in a 3D space.
MARS: Paying more attention to visual attributes for text-based person search
Jul 05, 2024Text-based person search (TBPS) is a problem that gained significant interest within the research community. The task is that of retrieving one or more images of a specific individual based on a textual description. The multi-modal nature of the task requires learning representations that bridge text and image data within a shared latent space. Existing TBPS systems face two major challenges. One is defined as inter-identity noise that is due to the inherent vagueness and imprecision of text descriptions and it indicates how descriptions of visual attributes can be generally associated to different people; the other is the intra-identity variations, which are all those nuisances e.g. pose, illumination, that can alter the visual appearance of the same textual attributes for a given subject. To address these issues, this paper presents a novel TBPS architecture named MARS (Mae-Attribute-Relation-Sensitive), which enhances current state-of-the-art models by introducing two key components: a Visual Reconstruction Loss and an Attribute Loss. The former employs a Masked AutoEncoder trained to reconstruct randomly masked image patches with the aid of the textual description. In doing so the model is encouraged to learn more expressive representations and textual-visual relations in the latent space. The Attribute Loss, instead, balances the contribution of different types of attributes, defined as adjective-noun chunks of text. This loss ensures that every attribute is taken into consideration in the person retrieval process. Extensive experiments on three commonly used datasets, namely CUHK-PEDES, ICFG-PEDES, and RSTPReid, report performance improvements, with significant gains in the mean Average Precision (mAP) metric w.r.t. the current state of the art.