 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Stationary (and Therefore Compatible) Representation is All You Need
Jun 10, 2026Learning compatible representations aims to learn feature representations that can be used interchangeably over time whenever a model undergoes updates. In this paper, we demonstrate that stationary representations learned by d-Simplex fixed classifiers imply compatibility as in its formal definition. This result establishes a foundation for future works and can be directly exploited in practical learning scenarios. We address the challenge of learning compatibility using $d$-Simplex fixed classifiers when the model is sequentially fine-tuned. Learning according to a d-Simplex fixed classifier with the cross-entropy loss aligns feature distributions at the first-order statistics. Consequently, it may not fully capture higher-order dependencies in the representation between model updates. To address this issue, we demonstrate that training the model using a $d$-Simplex fixed classifier through a convex combination of the cross-entropy loss and a contrastive loss not only captures higher-order dependencies, but is also equivalent to learning with the cross-entropy under the compatibility constraints. We confirm our findings with extensive experiments also considering a new scenario where a pre-trained model is sequentially fine-tuned and occasionally replaced with an improved model. We show that stationary representations enable uninterrupted retrieval services (without reprocessing gallery images) while improving performance during model updates and replacements, achieving state-of-the-art. Code at https://github.com/miccunifi/iamcl2r.
Mitigating Negative Flips via Margin Preserving Training
Nov 15, 2025Minimizing inconsistencies across successive versions of an AI system is as crucial as reducing the overall error. In image classification, such inconsistencies manifest as negative flips, where an updated model misclassifies test samples that were previously classified correctly. This issue becomes increasingly pronounced as the number of training classes grows over time, since adding new categories reduces the margin of each class and may introduce conflicting patterns that undermine their learning process, thereby degrading performance on the original subset. To mitigate negative flips, we propose a novel approach that preserves the margins of the original model while learning an improved one. Our method encourages a larger relative margin between the previously learned and newly introduced classes by introducing an explicit margin-calibration term on the logits. However, overly constraining the logit margin for the new classes can significantly degrade their accuracy compared to a new independently trained model. To address this, we integrate a double-source focal distillation loss with the previous model and a new independently trained model, learning an appropriate decision margin from both old and new data, even under a logit margin calibration. Extensive experiments on image classification benchmarks demonstrate that our approach consistently reduces the negative flip rate with high overall accuracy.
FRED: The Florence RGB-Event Drone Dataset
Jun 05, 2025Small, fast, and lightweight drones present significant challenges for traditional RGB cameras due to their limitations in capturing fast-moving objects, especially under challenging lighting conditions. Event cameras offer an ideal solution, providing high temporal definition and dynamic range, yet existing benchmarks often lack fine temporal resolution or drone-specific motion patterns, hindering progress in these areas. This paper introduces the Florence RGB-Event Drone dataset (FRED), a novel multimodal dataset specifically designed for drone detection, tracking, and trajectory forecasting, combining RGB video and event streams. FRED features more than 7 hours of densely annotated drone trajectories, using 5 different drone models and including challenging scenarios such as rain and adverse lighting conditions. We provide detailed evaluation protocols and standard metrics for each task, facilitating reproducible benchmarking. The authors hope FRED will advance research in high-speed drone perception and multimodal spatiotemporal understanding.
Spike-TBR: a Noise Resilient Neuromorphic Event Representation
Jun 05, 2025Event cameras offer significant advantages over traditional frame-based sensors, including higher temporal resolution, lower latency and dynamic range. However, efficiently converting event streams into formats compatible with standard computer vision pipelines remains a challenging problem, particularly in the presence of noise. In this paper, we propose Spike-TBR, a novel event-based encoding strategy based on Temporal Binary Representation (TBR), addressing its vulnerability to noise by integrating spiking neurons. Spike-TBR combines the frame-based advantages of TBR with the noise-filtering capabilities of spiking neural networks, creating a more robust representation of event streams. We evaluate four variants of Spike-TBR, each using different spiking neurons, across multiple datasets, demonstrating superior performance in noise-affected scenarios while improving the results on clean data. Our method bridges the gap between spike-based and frame-based processing, offering a simple noise-resilient solution for event-driven vision applications.
Spatio-temporal Transformers for Action Unit Classification with Event Cameras
Oct 29, 2024



Face analysis has been studied from different angles to infer emotion, poses, shapes, and landmarks. Traditionally RGB cameras are used, yet for fine-grained tasks standard sensors might not be up to the task due to their latency, making it impossible to record and detect micro-movements that carry a highly informative signal, which is necessary for inferring the true emotions of a subject. Event cameras have been increasingly gaining interest as a possible solution to this and similar high-frame rate tasks. We propose a novel spatiotemporal Vision Transformer model that uses Shifted Patch Tokenization (SPT) and Locality Self-Attention (LSA) to enhance the accuracy of Action Unit classification from event streams. We also address the lack of labeled event data in the literature, which can be considered one of the main causes of an existing gap between the maturity of RGB and neuromorphic vision models. Gathering data is harder in the event domain since it cannot be crawled from the web and labeling frames should take into account event aggregation rates and the fact that static parts might not be visible in certain frames. To this end, we present FACEMORPHIC, a temporally synchronized multimodal face dataset composed of RGB videos and event streams. The dataset is annotated at a video level with facial Action Units and contains streams collected with various possible applications, ranging from 3D shape estimation to lip-reading. We then show how temporal synchronization can allow effective neuromorphic face analysis without the need to manually annotate videos: we instead leverage cross-modal supervision bridging the domain gap by representing face shapes in a 3D space. Our proposed model outperforms baseline methods by effectively capturing spatial and temporal information, crucial for recognizing subtle facial micro-expressions.
Neuromorphic Drone Detection: an Event-RGB Multimodal Approach
Sep 24, 2024In recent years, drone detection has quickly become a subject of extreme interest: the potential for fast-moving objects of contained dimensions to be used for malicious intents or even terrorist attacks has posed attention to the necessity for precise and resilient systems for detecting and identifying such elements. While extensive literature and works exist on object detection based on RGB data, it is also critical to recognize the limits of such modality when applied to UAVs detection. Detecting drones indeed poses several challenges such as fast-moving objects and scenes with a high dynamic range or, even worse, scarce illumination levels. Neuromorphic cameras, on the other hand, can retain precise and rich spatio-temporal information in situations that are challenging for RGB cameras. They are resilient to both high-speed moving objects and scarce illumination settings, while prone to suffer a rapid loss of information when the objects in the scene are static. In this context, we present a novel model for integrating both domains together, leveraging multimodal data to take advantage of the best of both worlds. To this end, we also release NeRDD (Neuromorphic-RGB Drone Detection), a novel spatio-temporally synchronized Event-RGB Drone detection dataset of more than 3.5 hours of multimodal annotated recordings.
Garment Attribute Manipulation with Multi-level Attention
Sep 16, 2024



In the rapidly evolving field of online fashion shopping, the need for more personalized and interactive image retrieval systems has become paramount. Existing methods often struggle with precisely manipulating specific garment attributes without inadvertently affecting others. To address this challenge, we propose GAMMA (Garment Attribute Manipulation with Multi-level Attention), a novel framework that integrates attribute-disentangled representations with a multi-stage attention-based architecture. GAMMA enables targeted manipulation of fashion image attributes, allowing users to refine their searches with high accuracy. By leveraging a dual-encoder Transformer and memory block, our model achieves state-of-the-art performance on popular datasets like Shopping100k and DeepFashion.
Neuromorphic Facial Analysis with Cross-Modal Supervision
Sep 16, 2024



Traditional approaches for analyzing RGB frames are capable of providing a fine-grained understanding of a face from different angles by inferring emotions, poses, shapes, landmarks. However, when it comes to subtle movements standard RGB cameras might fall behind due to their latency, making it hard to detect micro-movements that carry highly informative cues to infer the true emotions of a subject. To address this issue, the usage of event cameras to analyze faces is gaining increasing interest. Nonetheless, all the expertise matured for RGB processing is not directly transferrable to neuromorphic data due to a strong domain shift and intrinsic differences in how data is represented. The lack of labeled data can be considered one of the main causes of this gap, yet gathering data is harder in the event domain since it cannot be crawled from the web and labeling frames should take into account event aggregation rates and the fact that static parts might not be visible in certain frames. In this paper, we first present FACEMORPHIC, a multimodal temporally synchronized face dataset comprising both RGB videos and event streams. The data is labeled at a video level with facial Action Units and also contains streams collected with a variety of applications in mind, ranging from 3D shape estimation to lip-reading. We then show how temporal synchronization can allow effective neuromorphic face analysis without the need to manually annotate videos: we instead leverage cross-modal supervision bridging the domain gap by representing face shapes in a 3D space.
Backward-Compatible Aligned Representations via an Orthogonal Transformation Layer
Aug 16, 2024
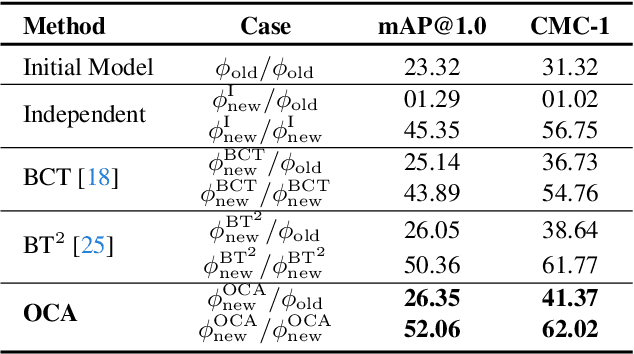

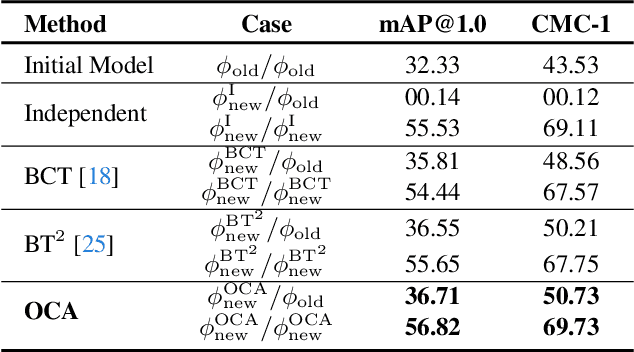
Visual retrieval systems face significant challenges when updating models with improved representations due to misalignment between the old and new representations. The costly and resource-intensive backfilling process involves recalculating feature vectors for images in the gallery set whenever a new model is introduced. To address this, prior research has explored backward-compatible training methods that enable direct comparisons between new and old representations without backfilling. Despite these advancements, achieving a balance between backward compatibility and the performance of independently trained models remains an open problem. In this paper, we address it by expanding the representation space with additional dimensions and learning an orthogonal transformation to achieve compatibility with old models and, at the same time, integrate new information. This transformation preserves the original feature space's geometry, ensuring that our model aligns with previous versions while also learning new data. Our Orthogonal Compatible Aligned (OCA) approach eliminates the need for re-indexing during model updates and ensures that features can be compared directly across different model updates without additional mapping functions. Experimental results on CIFAR-100 and ImageNet-1k demonstrate that our method not only maintains compatibility with previous models but also achieves state-of-the-art accuracy, outperforming several existing methods.
Prompt and Prejudice
Aug 07, 2024This paper investigates the impact of using first names in Large Language Models (LLMs) and Vision Language Models (VLMs), particularly when prompted with ethical decision-making tasks. We propose an approach that appends first names to ethically annotated text scenarios to reveal demographic biases in model outputs. Our study involves a curated list of more than 300 names representing diverse genders and ethnic backgrounds, tested across thousands of moral scenarios. Following the auditing methodologies from social sciences we propose a detailed analysis involving popular LLMs/VLMs to contribute to the field of responsible AI by emphasizing the importance of recognizing and mitigating biases in these systems. Furthermore, we introduce a novel benchmark, the Pratical Scenarios Benchmark (PSB), designed to assess the presence of biases involving gender or demographic prejudices in everyday decision-making scenarios as well as practical scenarios where an LLM might be used to make sensible decisions (e.g., granting mortgages or insurances). This benchmark allows for a comprehensive comparison of model behaviors across different demographic categories, highlighting the risks and biases that may arise in practical applications of LLMs and VLMs.