 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDrone Detection with Event Cameras
Aug 06, 2025The diffusion of drones presents significant security and safety challenges. Traditional surveillance systems, particularly conventional frame-based cameras, struggle to reliably detect these targets due to their small size, high agility, and the resulting motion blur and poor performance in challenging lighting conditions. This paper surveys the emerging field of event-based vision as a robust solution to these problems. Event cameras virtually eliminate motion blur and enable consistent detection in extreme lighting. Their sparse, asynchronous output suppresses static backgrounds, enabling low-latency focus on motion cues. We review the state-of-the-art in event-based drone detection, from data representation methods to advanced processing pipelines using spiking neural networks. The discussion extends beyond simple detection to cover more sophisticated tasks such as real-time tracking, trajectory forecasting, and unique identification through propeller signature analysis. By examining current methodologies, available datasets, and the distinct advantages of the technology, this work demonstrates that event-based vision provides a powerful foundation for the next generation of reliable, low-latency, and efficient counter-UAV systems.
Spike-TBR: a Noise Resilient Neuromorphic Event Representation
Jun 05, 2025Event cameras offer significant advantages over traditional frame-based sensors, including higher temporal resolution, lower latency and dynamic range. However, efficiently converting event streams into formats compatible with standard computer vision pipelines remains a challenging problem, particularly in the presence of noise. In this paper, we propose Spike-TBR, a novel event-based encoding strategy based on Temporal Binary Representation (TBR), addressing its vulnerability to noise by integrating spiking neurons. Spike-TBR combines the frame-based advantages of TBR with the noise-filtering capabilities of spiking neural networks, creating a more robust representation of event streams. We evaluate four variants of Spike-TBR, each using different spiking neurons, across multiple datasets, demonstrating superior performance in noise-affected scenarios while improving the results on clean data. Our method bridges the gap between spike-based and frame-based processing, offering a simple noise-resilient solution for event-driven vision applications.
Spatio-temporal Transformers for Action Unit Classification with Event Cameras
Oct 29, 2024



Face analysis has been studied from different angles to infer emotion, poses, shapes, and landmarks. Traditionally RGB cameras are used, yet for fine-grained tasks standard sensors might not be up to the task due to their latency, making it impossible to record and detect micro-movements that carry a highly informative signal, which is necessary for inferring the true emotions of a subject. Event cameras have been increasingly gaining interest as a possible solution to this and similar high-frame rate tasks. We propose a novel spatiotemporal Vision Transformer model that uses Shifted Patch Tokenization (SPT) and Locality Self-Attention (LSA) to enhance the accuracy of Action Unit classification from event streams. We also address the lack of labeled event data in the literature, which can be considered one of the main causes of an existing gap between the maturity of RGB and neuromorphic vision models. Gathering data is harder in the event domain since it cannot be crawled from the web and labeling frames should take into account event aggregation rates and the fact that static parts might not be visible in certain frames. To this end, we present FACEMORPHIC, a temporally synchronized multimodal face dataset composed of RGB videos and event streams. The dataset is annotated at a video level with facial Action Units and contains streams collected with various possible applications, ranging from 3D shape estimation to lip-reading. We then show how temporal synchronization can allow effective neuromorphic face analysis without the need to manually annotate videos: we instead leverage cross-modal supervision bridging the domain gap by representing face shapes in a 3D space. Our proposed model outperforms baseline methods by effectively capturing spatial and temporal information, crucial for recognizing subtle facial micro-expressions.
Neuromorphic Facial Analysis with Cross-Modal Supervision
Sep 16, 2024



Traditional approaches for analyzing RGB frames are capable of providing a fine-grained understanding of a face from different angles by inferring emotions, poses, shapes, landmarks. However, when it comes to subtle movements standard RGB cameras might fall behind due to their latency, making it hard to detect micro-movements that carry highly informative cues to infer the true emotions of a subject. To address this issue, the usage of event cameras to analyze faces is gaining increasing interest. Nonetheless, all the expertise matured for RGB processing is not directly transferrable to neuromorphic data due to a strong domain shift and intrinsic differences in how data is represented. The lack of labeled data can be considered one of the main causes of this gap, yet gathering data is harder in the event domain since it cannot be crawled from the web and labeling frames should take into account event aggregation rates and the fact that static parts might not be visible in certain frames. In this paper, we first present FACEMORPHIC, a multimodal temporally synchronized face dataset comprising both RGB videos and event streams. The data is labeled at a video level with facial Action Units and also contains streams collected with a variety of applications in mind, ranging from 3D shape estimation to lip-reading. We then show how temporal synchronization can allow effective neuromorphic face analysis without the need to manually annotate videos: we instead leverage cross-modal supervision bridging the domain gap by representing face shapes in a 3D space.
Garment Attribute Manipulation with Multi-level Attention
Sep 16, 2024



In the rapidly evolving field of online fashion shopping, the need for more personalized and interactive image retrieval systems has become paramount. Existing methods often struggle with precisely manipulating specific garment attributes without inadvertently affecting others. To address this challenge, we propose GAMMA (Garment Attribute Manipulation with Multi-level Attention), a novel framework that integrates attribute-disentangled representations with a multi-stage attention-based architecture. GAMMA enables targeted manipulation of fashion image attributes, allowing users to refine their searches with high accuracy. By leveraging a dual-encoder Transformer and memory block, our model achieves state-of-the-art performance on popular datasets like Shopping100k and DeepFashion.
Prompt and Prejudice
Aug 07, 2024This paper investigates the impact of using first names in Large Language Models (LLMs) and Vision Language Models (VLMs), particularly when prompted with ethical decision-making tasks. We propose an approach that appends first names to ethically annotated text scenarios to reveal demographic biases in model outputs. Our study involves a curated list of more than 300 names representing diverse genders and ethnic backgrounds, tested across thousands of moral scenarios. Following the auditing methodologies from social sciences we propose a detailed analysis involving popular LLMs/VLMs to contribute to the field of responsible AI by emphasizing the importance of recognizing and mitigating biases in these systems. Furthermore, we introduce a novel benchmark, the Pratical Scenarios Benchmark (PSB), designed to assess the presence of biases involving gender or demographic prejudices in everyday decision-making scenarios as well as practical scenarios where an LLM might be used to make sensible decisions (e.g., granting mortgages or insurances). This benchmark allows for a comprehensive comparison of model behaviors across different demographic categories, highlighting the risks and biases that may arise in practical applications of LLMs and VLMs.
Neuromorphic Face Analysis: a Survey
Feb 18, 2024Neuromorphic sensors, also known as event cameras, are a class of imaging devices mimicking the function of biological visual systems. Unlike traditional frame-based cameras, which capture fixed images at discrete intervals, neuromorphic sensors continuously generate events that represent changes in light intensity or motion in the visual field with high temporal resolution and low latency. These properties have proven to be interesting in modeling human faces, both from an effectiveness and a privacy-preserving point of view. Neuromorphic face analysis however is still a raw and unstructured field of research, with several attempts at addressing different tasks with no clear standard or benchmark. This survey paper presents a comprehensive overview of capabilities, challenges and emerging applications in the domain of neuromorphic face analysis, to outline promising directions and open issues. After discussing the fundamental working principles of neuromorphic vision and presenting an in-depth overview of the related research, we explore the current state of available data, standard data representations, emerging challenges, and limitations that require further investigation. This paper aims to highlight the recent process in this evolving field to provide to both experienced and newly come researchers an all-encompassing analysis of the state of the art along with its problems and shortcomings.
Neuromorphic Valence and Arousal Estimation
Jan 29, 2024



Recognizing faces and their underlying emotions is an important aspect of biometrics. In fact, estimating emotional states from faces has been tackled from several angles in the literature. In this paper, we follow the novel route of using neuromorphic data to predict valence and arousal values from faces. Due to the difficulty of gathering event-based annotated videos, we leverage an event camera simulator to create the neuromorphic counterpart of an existing RGB dataset. We demonstrate that not only training models on simulated data can still yield state-of-the-art results in valence-arousal estimation, but also that our trained models can be directly applied to real data without further training to address the downstream task of emotion recognition. In the paper we propose several alternative models to solve the task, both frame-based and video-based.
Addressing Limitations of State-Aware Imitation Learning for Autonomous Driving
Oct 31, 2023



Conditional Imitation learning is a common and effective approach to train autonomous driving agents. However, two issues limit the full potential of this approach: (i) the inertia problem, a special case of causal confusion where the agent mistakenly correlates low speed with no acceleration, and (ii) low correlation between offline and online performance due to the accumulation of small errors that brings the agent in a previously unseen state. Both issues are critical for state-aware models, yet informing the driving agent of its internal state as well as the state of the environment is of crucial importance. In this paper we propose a multi-task learning agent based on a multi-stage vision transformer with state token propagation. We feed the state of the vehicle along with the representation of the environment as a special token of the transformer and propagate it throughout the network. This allows us to tackle the aforementioned issues from different angles: guiding the driving policy with learned stop/go information, performing data augmentation directly on the state of the vehicle and visually explaining the model's decisions. We report a drastic decrease in inertia and a high correlation between offline and online metrics.
Neuromorphic Event-based Facial Expression Recognition
Apr 13, 2023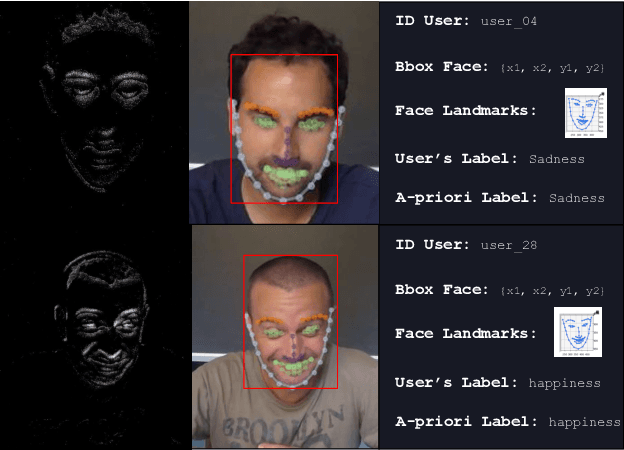

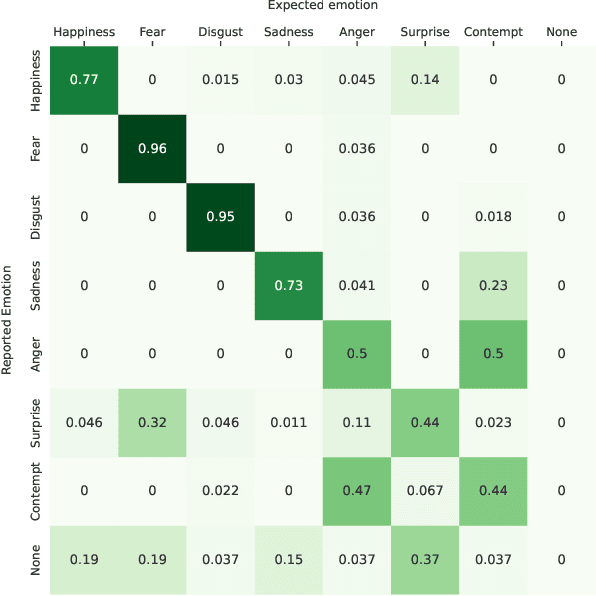

Recently, event cameras have shown large applicability in several computer vision fields especially concerning tasks that require high temporal resolution. In this work, we investigate the usage of such kind of data for emotion recognition by presenting NEFER, a dataset for Neuromorphic Event-based Facial Expression Recognition. NEFER is composed of paired RGB and event videos representing human faces labeled with the respective emotions and also annotated with face bounding boxes and facial landmarks. We detail the data acquisition process as well as providing a baseline method for RGB and event data. The collected data captures subtle micro-expressions, which are hard to spot with RGB data, yet emerge in the event domain. We report a double recognition accuracy for the event-based approach, proving the effectiveness of a neuromorphic approach for analyzing fast and hardly detectable expressions and the emotions they conceal.