 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGarment Attribute Manipulation with Multi-level Attention
Sep 16, 2024



In the rapidly evolving field of online fashion shopping, the need for more personalized and interactive image retrieval systems has become paramount. Existing methods often struggle with precisely manipulating specific garment attributes without inadvertently affecting others. To address this challenge, we propose GAMMA (Garment Attribute Manipulation with Multi-level Attention), a novel framework that integrates attribute-disentangled representations with a multi-stage attention-based architecture. GAMMA enables targeted manipulation of fashion image attributes, allowing users to refine their searches with high accuracy. By leveraging a dual-encoder Transformer and memory block, our model achieves state-of-the-art performance on popular datasets like Shopping100k and DeepFashion.
Visual Question Answering: which investigated applications?
Mar 04, 2021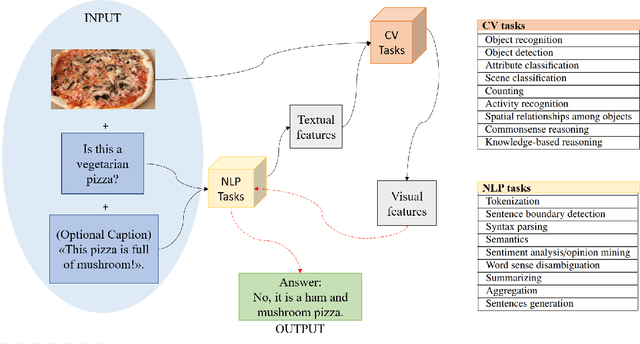
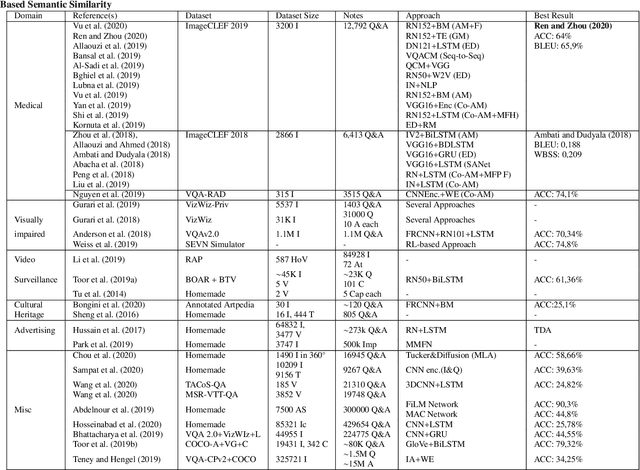

Visual Question Answering (VQA) is an extremely stimulating and challenging research area where Computer Vision (CV) and Natural Language Processig (NLP) have recently met. In image captioning and video summarization, the semantic information is completely contained in still images or video dynamics, and it has only to be mined and expressed in a human-consistent way. Differently from this, in VQA semantic information in the same media must be compared with the semantics implied by a question expressed in natural language, doubling the artificial intelligence-related effort. Some recent surveys about VQA approaches have focused on methods underlying either the image-related processing or the verbal-related one, or on the way to consistently fuse the conveyed information. Possible applications are only suggested, and, in fact, most cited works rely on general-purpose datasets that are used to assess the building blocks of a VQA system. This paper rather considers the proposals that focus on real-world applications, possibly using as benchmarks suitable data bound to the application domain. The paper also reports about some recent challenges in VQA research.
HP2IFS: Head Pose estimation exploiting Partitioned Iterated Function Systems
Mar 25, 2020
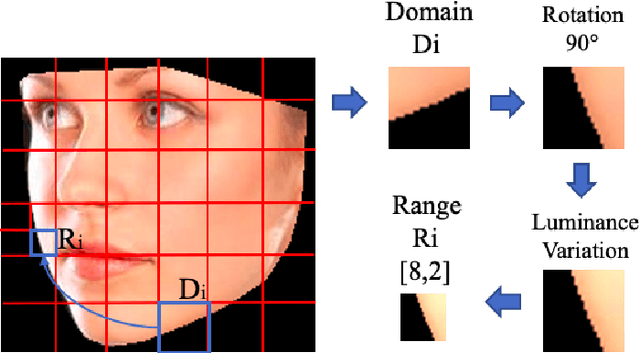

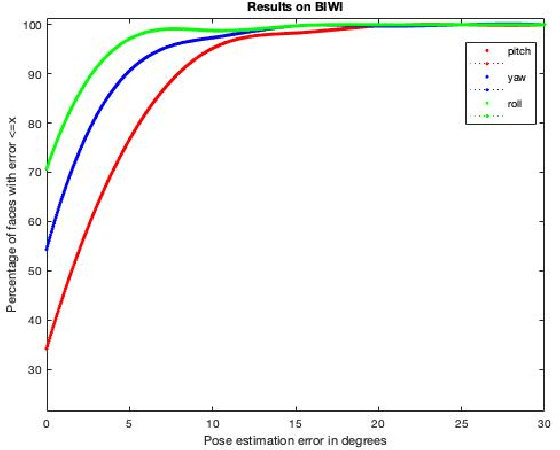
Estimating the actual head orientation from 2D images, with regard to its three degrees of freedom, is a well known problem that is highly significant for a large number of applications involving head pose knowledge. Consequently, this topic has been tackled by a plethora of methods and algorithms the most part of which exploits neural networks. Machine learning methods, indeed, achieve accurate head rotation values yet require an adequate training stage and, to that aim, a relevant number of positive and negative examples. In this paper we take a different approach to this topic by using fractal coding theory and particularly Partitioned Iterated Function Systems to extract the fractal code from the input head image and to compare this representation to the fractal code of a reference model through Hamming distance. According to experiments conducted on both the BIWI and the AFLW2000 databases, the proposed PIFS based head pose estimation method provides accurate yaw/pitch/roll angular values, with a performance approaching that of state of the art of machine-learning based algorithms and exceeding most of non-training based approaches.