 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuralLVC: Neural Lossless Video Compression via Masked Diffusion with Temporal Conditioning
Apr 03, 2026While neural lossless image compression has advanced significantly with learned entropy models, lossless video compression remains largely unexplored in the neural setting. We present NeuralLVC, a neural lossless video codec that combines masked diffusion with an I/P-frame architecture for exploiting temporal redundancy. Our I-frame model compresses individual frames using bijective linear tokenization that guarantees exact pixel reconstruction. The P-frame model compresses temporal differences between consecutive frames, conditioned on the previous decoded frame via a lightweight reference embedding that adds only 1.3% trainable parameters. Group-wise decoding enables controllable speed-compression trade-offs. Our codec is lossless in the input domain: for video, it reconstructs YUV420 planes exactly; for image evaluation, RGB channels are reconstructed exactly. Experiments on 9 Xiph CIF sequences show that NeuralLVC outperforms H.264 and H.265 lossless by a significant margin. We verify exact reconstruction through end-to-end encode-decode testing with arithmetic coding. These results suggest that masked diffusion with temporal conditioning is a promising direction for neural lossless video compression.
A document processing pipeline for the construction of a dataset for topic modeling based on the judgments of the Italian Supreme Court
May 13, 2025Topic modeling in Italian legal research is hindered by the lack of public datasets, limiting the analysis of legal themes in Supreme Court judgments. To address this, we developed a document processing pipeline that produces an anonymized dataset optimized for topic modeling. The pipeline integrates document layout analysis (YOLOv8x), optical character recognition, and text anonymization. The DLA module achieved a mAP@50 of 0.964 and a mAP@50-95 of 0.800. The OCR detector reached a mAP@50-95 of 0.9022, and the text recognizer (TrOCR) obtained a character error rate of 0.0047 and a word error rate of 0.0248. Compared to OCR-only methods, our dataset improved topic modeling with a diversity score of 0.6198 and a coherence score of 0.6638. We applied BERTopic to extract topics and used large language models to generate labels and summaries. Outputs were evaluated against domain expert interpretations. Claude Sonnet 3.7 achieved a BERTScore F1 of 0.8119 for labeling and 0.9130 for summarization.
ComicsPAP: understanding comic strips by picking the correct panel
Mar 11, 2025Large multimodal models (LMMs) have made impressive strides in image captioning, VQA, and video comprehension, yet they still struggle with the intricate temporal and spatial cues found in comics. To address this gap, we introduce ComicsPAP, a large-scale benchmark designed for comic strip understanding. Comprising over 100k samples and organized into 5 subtasks under a Pick-a-Panel framework, ComicsPAP demands models to identify the missing panel in a sequence. Our evaluations, conducted under both multi-image and single-image protocols, reveal that current state-of-the-art LMMs perform near chance on these tasks, underscoring significant limitations in capturing sequential and contextual dependencies. To close the gap, we adapted LMMs for comic strip understanding, obtaining better results on ComicsPAP than 10x bigger models, demonstrating that ComicsPAP offers a robust resource to drive future research in multimodal comic comprehension.
HoloMine: A Synthetic Dataset for Buried Landmines Recognition using Microwave Holographic Imaging
Feb 28, 2025The detection and removal of landmines is a complex and risky task that requires advanced remote sensing techniques to reduce the risk for the professionals involved in this task. In this paper, we propose a novel synthetic dataset for buried landmine detection to provide researchers with a valuable resource to observe, measure, locate, and address issues in landmine detection. The dataset consists of 41,800 microwave holographic images (2D) and their holographic inverted scans (3D) of different types of buried objects, including landmines, clutter, and pottery objects, and is collected by means of a microwave holography sensor. We evaluate the performance of several state-of-the-art deep learning models trained on our synthetic dataset for various classification tasks. While the results do not yield yet high performances, showing the difficulty of the proposed task, we believe that our dataset has significant potential to drive progress in the field of landmine detection thanks to the accuracy and resolution obtainable using holographic radars. To the best of our knowledge, our dataset is the first of its kind and will help drive further research on computer vision methods to automatize mine detection, with the overall goal of reducing the risks and the costs of the demining process.
Cross the Gap: Exposing the Intra-modal Misalignment in CLIP via Modality Inversion
Feb 06, 2025



Pre-trained multi-modal Vision-Language Models like CLIP are widely used off-the-shelf for a variety of applications. In this paper, we show that the common practice of individually exploiting the text or image encoders of these powerful multi-modal models is highly suboptimal for intra-modal tasks like image-to-image retrieval. We argue that this is inherently due to the CLIP-style inter-modal contrastive loss that does not enforce any intra-modal constraints, leading to what we call intra-modal misalignment. To demonstrate this, we leverage two optimization-based modality inversion techniques that map representations from their input modality to the complementary one without any need for auxiliary data or additional trained adapters. We empirically show that, in the intra-modal tasks of image-to-image and text-to-text retrieval, approaching these tasks inter-modally significantly improves performance with respect to intra-modal baselines on more than fifteen datasets. Additionally, we demonstrate that approaching a native inter-modal task (e.g. zero-shot image classification) intra-modally decreases performance, further validating our findings. Finally, we show that incorporating an intra-modal term in the pre-training objective or narrowing the modality gap between the text and image feature embedding spaces helps reduce the intra-modal misalignment. The code is publicly available at: https://github.com/miccunifi/Cross-the-Gap.
ComiCap: A VLMs pipeline for dense captioning of Comic Panels
Sep 24, 2024The comic domain is rapidly advancing with the development of single- and multi-page analysis and synthesis models. Recent benchmarks and datasets have been introduced to support and assess models' capabilities in tasks such as detection (panels, characters, text), linking (character re-identification and speaker identification), and analysis of comic elements (e.g., dialog transcription). However, to provide a comprehensive understanding of the storyline, a model must not only extract elements but also understand their relationships and generate highly informative captions. In this work, we propose a pipeline that leverages Vision-Language Models (VLMs) to obtain dense, grounded captions. To construct our pipeline, we introduce an attribute-retaining metric that assesses whether all important attributes are identified in the caption. Additionally, we created a densely annotated test set to fairly evaluate open-source VLMs and select the best captioning model according to our metric. Our pipeline generates dense captions with bounding boxes that are quantitatively and qualitatively superior to those produced by specifically trained models, without requiring any additional training. Using this pipeline, we annotated over 2 million panels across 13,000 books, which will be available on the project page https://github.com/emanuelevivoli/ComiCap.
Garment Attribute Manipulation with Multi-level Attention
Sep 16, 2024



In the rapidly evolving field of online fashion shopping, the need for more personalized and interactive image retrieval systems has become paramount. Existing methods often struggle with precisely manipulating specific garment attributes without inadvertently affecting others. To address this challenge, we propose GAMMA (Garment Attribute Manipulation with Multi-level Attention), a novel framework that integrates attribute-disentangled representations with a multi-stage attention-based architecture. GAMMA enables targeted manipulation of fashion image attributes, allowing users to refine their searches with high accuracy. By leveraging a dual-encoder Transformer and memory block, our model achieves state-of-the-art performance on popular datasets like Shopping100k and DeepFashion.
One missing piece in Vision and Language: A Survey on Comics Understanding
Sep 14, 2024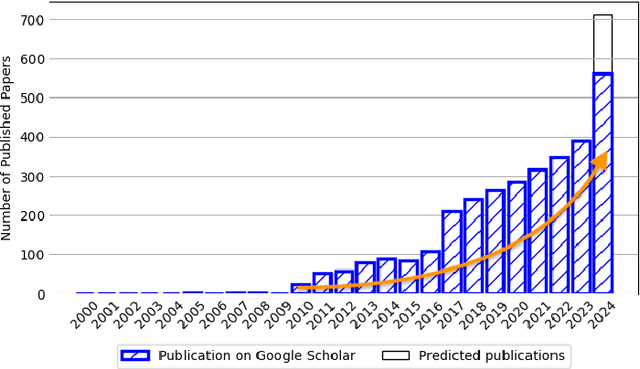
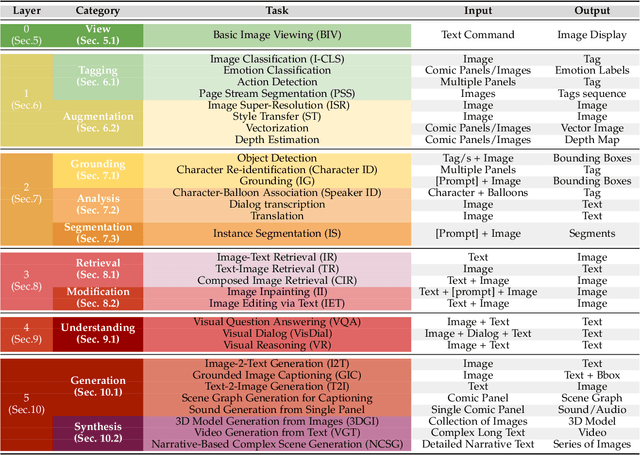
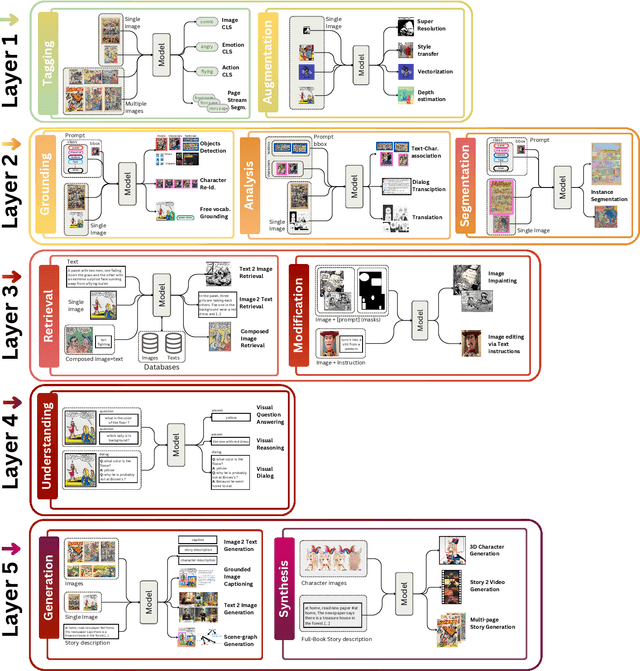
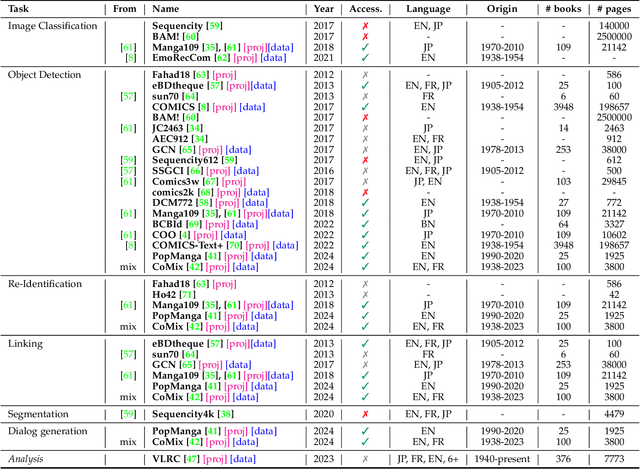
Vision-language models have recently evolved into versatile systems capable of high performance across a range of tasks, such as document understanding, visual question answering, and grounding, often in zero-shot settings. Comics Understanding, a complex and multifaceted field, stands to greatly benefit from these advances. Comics, as a medium, combine rich visual and textual narratives, challenging AI models with tasks that span image classification, object detection, instance segmentation, and deeper narrative comprehension through sequential panels. However, the unique structure of comics -- characterized by creative variations in style, reading order, and non-linear storytelling -- presents a set of challenges distinct from those in other visual-language domains. In this survey, we present a comprehensive review of Comics Understanding from both dataset and task perspectives. Our contributions are fivefold: (1) We analyze the structure of the comics medium, detailing its distinctive compositional elements; (2) We survey the widely used datasets and tasks in comics research, emphasizing their role in advancing the field; (3) We introduce the Layer of Comics Understanding (LoCU) framework, a novel taxonomy that redefines vision-language tasks within comics and lays the foundation for future work; (4) We provide a detailed review and categorization of existing methods following the LoCU framework; (5) Finally, we highlight current research challenges and propose directions for future exploration, particularly in the context of vision-language models applied to comics. This survey is the first to propose a task-oriented framework for comics intelligence and aims to guide future research by addressing critical gaps in data availability and task definition. A project associated with this survey is available at https://github.com/emanuelevivoli/awesome-comics-understanding.
Prompt and Prejudice
Aug 07, 2024This paper investigates the impact of using first names in Large Language Models (LLMs) and Vision Language Models (VLMs), particularly when prompted with ethical decision-making tasks. We propose an approach that appends first names to ethically annotated text scenarios to reveal demographic biases in model outputs. Our study involves a curated list of more than 300 names representing diverse genders and ethnic backgrounds, tested across thousands of moral scenarios. Following the auditing methodologies from social sciences we propose a detailed analysis involving popular LLMs/VLMs to contribute to the field of responsible AI by emphasizing the importance of recognizing and mitigating biases in these systems. Furthermore, we introduce a novel benchmark, the Pratical Scenarios Benchmark (PSB), designed to assess the presence of biases involving gender or demographic prejudices in everyday decision-making scenarios as well as practical scenarios where an LLM might be used to make sensible decisions (e.g., granting mortgages or insurances). This benchmark allows for a comprehensive comparison of model behaviors across different demographic categories, highlighting the risks and biases that may arise in practical applications of LLMs and VLMs.
CoMix: A Comprehensive Benchmark for Multi-Task Comic Understanding
Jul 04, 2024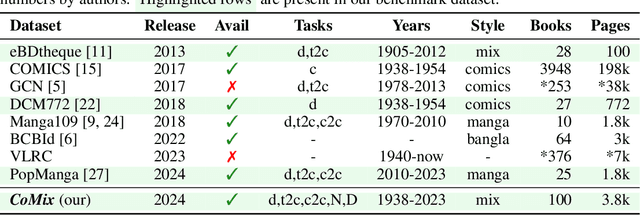



The comic domain is rapidly advancing with the development of single-page analysis and synthesis models. However, evaluation metrics and datasets lag behind, often limited to small-scale or single-style test sets. We introduce a novel benchmark, CoMix, designed to evaluate the multi-task capabilities of models in comic analysis. Unlike existing benchmarks that focus on isolated tasks such as object detection or text recognition, CoMix addresses a broader range of tasks including object detection, speaker identification, character re-identification, reading order, and multi-modal reasoning tasks like character naming and dialogue generation. Our benchmark comprises three existing datasets with expanded annotations to support multi-task evaluation. To mitigate the over-representation of manga-style data, we have incorporated a new dataset of carefully selected American comic-style books, thereby enriching the diversity of comic styles. CoMix is designed to assess pre-trained models in zero-shot and limited fine-tuning settings, probing their transfer capabilities across different comic styles and tasks. The validation split of the benchmark is publicly available for research purposes, and an evaluation server for the held-out test split is also provided. Comparative results between human performance and state-of-the-art models reveal a significant performance gap, highlighting substantial opportunities for advancements in comic understanding. The dataset, baseline models, and code are accessible at the repository link. This initiative sets a new standard for comprehensive comic analysis, providing the community with a common benchmark for evaluation on a large and varied set.