 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePEPR: Privileged Event-based Predictive Regularization for Domain Generalization
Feb 04, 2026Deep neural networks for visual perception are highly susceptible to domain shift, which poses a critical challenge for real-world deployment under conditions that differ from the training data. To address this domain generalization challenge, we propose a cross-modal framework under the learning using privileged information (LUPI) paradigm for training a robust, single-modality RGB model. We leverage event cameras as a source of privileged information, available only during training. The two modalities exhibit complementary characteristics: the RGB stream is semantically dense but domain-dependent, whereas the event stream is sparse yet more domain-invariant. Direct feature alignment between them is therefore suboptimal, as it forces the RGB encoder to mimic the sparse event representation, thereby losing semantic detail. To overcome this, we introduce Privileged Event-based Predictive Regularization (PEPR), which reframes LUPI as a predictive problem in a shared latent space. Instead of enforcing direct cross-modal alignment, we train the RGB encoder with PEPR to predict event-based latent features, distilling robustness without sacrificing semantic richness. The resulting standalone RGB model consistently improves robustness to day-to-night and other domain shifts, outperforming alignment-based baselines across object detection and semantic segmentation.
Mitigating Negative Flips via Margin Preserving Training
Nov 15, 2025Minimizing inconsistencies across successive versions of an AI system is as crucial as reducing the overall error. In image classification, such inconsistencies manifest as negative flips, where an updated model misclassifies test samples that were previously classified correctly. This issue becomes increasingly pronounced as the number of training classes grows over time, since adding new categories reduces the margin of each class and may introduce conflicting patterns that undermine their learning process, thereby degrading performance on the original subset. To mitigate negative flips, we propose a novel approach that preserves the margins of the original model while learning an improved one. Our method encourages a larger relative margin between the previously learned and newly introduced classes by introducing an explicit margin-calibration term on the logits. However, overly constraining the logit margin for the new classes can significantly degrade their accuracy compared to a new independently trained model. To address this, we integrate a double-source focal distillation loss with the previous model and a new independently trained model, learning an appropriate decision margin from both old and new data, even under a logit margin calibration. Extensive experiments on image classification benchmarks demonstrate that our approach consistently reduces the negative flip rate with high overall accuracy.
FRED: The Florence RGB-Event Drone Dataset
Jun 05, 2025Small, fast, and lightweight drones present significant challenges for traditional RGB cameras due to their limitations in capturing fast-moving objects, especially under challenging lighting conditions. Event cameras offer an ideal solution, providing high temporal definition and dynamic range, yet existing benchmarks often lack fine temporal resolution or drone-specific motion patterns, hindering progress in these areas. This paper introduces the Florence RGB-Event Drone dataset (FRED), a novel multimodal dataset specifically designed for drone detection, tracking, and trajectory forecasting, combining RGB video and event streams. FRED features more than 7 hours of densely annotated drone trajectories, using 5 different drone models and including challenging scenarios such as rain and adverse lighting conditions. We provide detailed evaluation protocols and standard metrics for each task, facilitating reproducible benchmarking. The authors hope FRED will advance research in high-speed drone perception and multimodal spatiotemporal understanding.
ComiCap: A VLMs pipeline for dense captioning of Comic Panels
Sep 24, 2024The comic domain is rapidly advancing with the development of single- and multi-page analysis and synthesis models. Recent benchmarks and datasets have been introduced to support and assess models' capabilities in tasks such as detection (panels, characters, text), linking (character re-identification and speaker identification), and analysis of comic elements (e.g., dialog transcription). However, to provide a comprehensive understanding of the storyline, a model must not only extract elements but also understand their relationships and generate highly informative captions. In this work, we propose a pipeline that leverages Vision-Language Models (VLMs) to obtain dense, grounded captions. To construct our pipeline, we introduce an attribute-retaining metric that assesses whether all important attributes are identified in the caption. Additionally, we created a densely annotated test set to fairly evaluate open-source VLMs and select the best captioning model according to our metric. Our pipeline generates dense captions with bounding boxes that are quantitatively and qualitatively superior to those produced by specifically trained models, without requiring any additional training. Using this pipeline, we annotated over 2 million panels across 13,000 books, which will be available on the project page https://github.com/emanuelevivoli/ComiCap.
Backward-Compatible Aligned Representations via an Orthogonal Transformation Layer
Aug 16, 2024
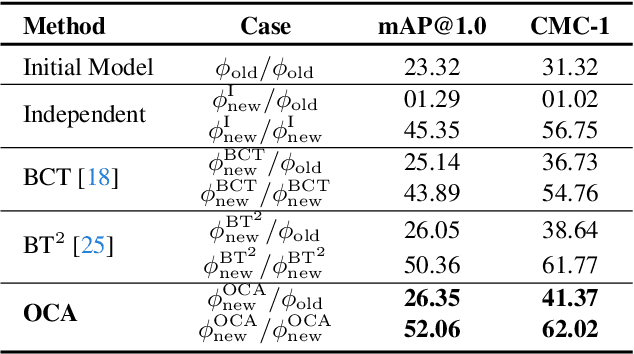

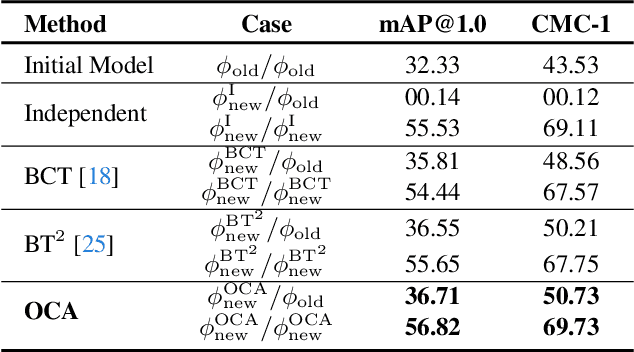
Visual retrieval systems face significant challenges when updating models with improved representations due to misalignment between the old and new representations. The costly and resource-intensive backfilling process involves recalculating feature vectors for images in the gallery set whenever a new model is introduced. To address this, prior research has explored backward-compatible training methods that enable direct comparisons between new and old representations without backfilling. Despite these advancements, achieving a balance between backward compatibility and the performance of independently trained models remains an open problem. In this paper, we address it by expanding the representation space with additional dimensions and learning an orthogonal transformation to achieve compatibility with old models and, at the same time, integrate new information. This transformation preserves the original feature space's geometry, ensuring that our model aligns with previous versions while also learning new data. Our Orthogonal Compatible Aligned (OCA) approach eliminates the need for re-indexing during model updates and ensures that features can be compared directly across different model updates without additional mapping functions. Experimental results on CIFAR-100 and ImageNet-1k demonstrate that our method not only maintains compatibility with previous models but also achieves state-of-the-art accuracy, outperforming several existing methods.
Comics Datasets Framework: Mix of Comics datasets for detection benchmarking
Jul 03, 2024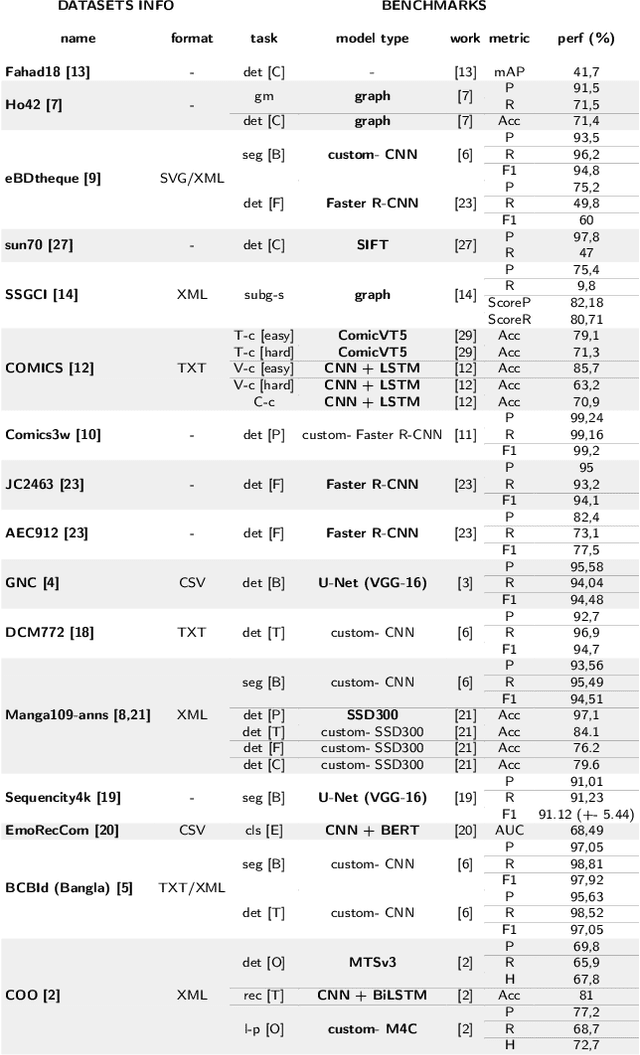
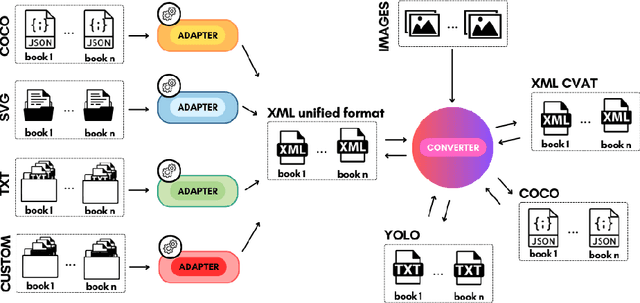
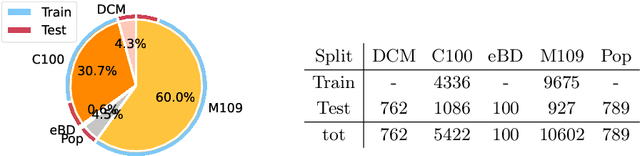
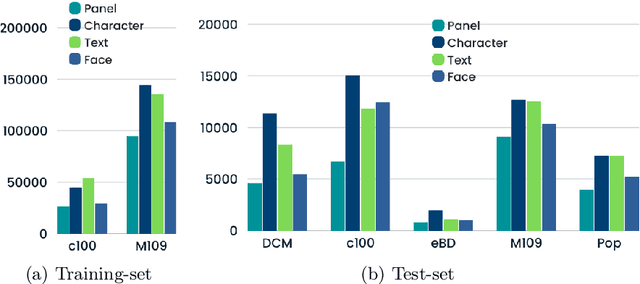
Comics, as a medium, uniquely combine text and images in styles often distinct from real-world visuals. For the past three decades, computational research on comics has evolved from basic object detection to more sophisticated tasks. However, the field faces persistent challenges such as small datasets, inconsistent annotations, inaccessible model weights, and results that cannot be directly compared due to varying train/test splits and metrics. To address these issues, we aim to standardize annotations across datasets, introduce a variety of comic styles into the datasets, and establish benchmark results with clear, replicable settings. Our proposed Comics Datasets Framework standardizes dataset annotations into a common format and addresses the overrepresentation of manga by introducing Comics100, a curated collection of 100 books from the Digital Comics Museum, annotated for detection in our uniform format. We have benchmarked a variety of detection architectures using the Comics Datasets Framework. All related code, model weights, and detailed evaluation processes are available at https://github.com/emanuelevivoli/cdf, ensuring transparency and facilitating replication. This initiative is a significant advancement towards improving object detection in comics, laying the groundwork for more complex computational tasks dependent on precise object recognition.
Stationary Representations: Optimally Approximating Compatibility and Implications for Improved Model Replacements
May 04, 2024



Learning compatible representations enables the interchangeable use of semantic features as models are updated over time. This is particularly relevant in search and retrieval systems where it is crucial to avoid reprocessing of the gallery images with the updated model. While recent research has shown promising empirical evidence, there is still a lack of comprehensive theoretical understanding about learning compatible representations. In this paper, we demonstrate that the stationary representations learned by the $d$-Simplex fixed classifier optimally approximate compatibility representation according to the two inequality constraints of its formal definition. This not only establishes a solid foundation for future works in this line of research but also presents implications that can be exploited in practical learning scenarios. An exemplary application is the now-standard practice of downloading and fine-tuning new pre-trained models. Specifically, we show the strengths and critical issues of stationary representations in the case in which a model undergoing sequential fine-tuning is asynchronously replaced by downloading a better-performing model pre-trained elsewhere. Such a representation enables seamless delivery of retrieval service (i.e., no reprocessing of gallery images) and offers improved performance without operational disruptions during model replacement. Code available at: https://github.com/miccunifi/iamcl2r.