 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComicsPAP: understanding comic strips by picking the correct panel
Mar 11, 2025Large multimodal models (LMMs) have made impressive strides in image captioning, VQA, and video comprehension, yet they still struggle with the intricate temporal and spatial cues found in comics. To address this gap, we introduce ComicsPAP, a large-scale benchmark designed for comic strip understanding. Comprising over 100k samples and organized into 5 subtasks under a Pick-a-Panel framework, ComicsPAP demands models to identify the missing panel in a sequence. Our evaluations, conducted under both multi-image and single-image protocols, reveal that current state-of-the-art LMMs perform near chance on these tasks, underscoring significant limitations in capturing sequential and contextual dependencies. To close the gap, we adapted LMMs for comic strip understanding, obtaining better results on ComicsPAP than 10x bigger models, demonstrating that ComicsPAP offers a robust resource to drive future research in multimodal comic comprehension.
HoloMine: A Synthetic Dataset for Buried Landmines Recognition using Microwave Holographic Imaging
Feb 28, 2025The detection and removal of landmines is a complex and risky task that requires advanced remote sensing techniques to reduce the risk for the professionals involved in this task. In this paper, we propose a novel synthetic dataset for buried landmine detection to provide researchers with a valuable resource to observe, measure, locate, and address issues in landmine detection. The dataset consists of 41,800 microwave holographic images (2D) and their holographic inverted scans (3D) of different types of buried objects, including landmines, clutter, and pottery objects, and is collected by means of a microwave holography sensor. We evaluate the performance of several state-of-the-art deep learning models trained on our synthetic dataset for various classification tasks. While the results do not yield yet high performances, showing the difficulty of the proposed task, we believe that our dataset has significant potential to drive progress in the field of landmine detection thanks to the accuracy and resolution obtainable using holographic radars. To the best of our knowledge, our dataset is the first of its kind and will help drive further research on computer vision methods to automatize mine detection, with the overall goal of reducing the risks and the costs of the demining process.
ComiCap: A VLMs pipeline for dense captioning of Comic Panels
Sep 24, 2024The comic domain is rapidly advancing with the development of single- and multi-page analysis and synthesis models. Recent benchmarks and datasets have been introduced to support and assess models' capabilities in tasks such as detection (panels, characters, text), linking (character re-identification and speaker identification), and analysis of comic elements (e.g., dialog transcription). However, to provide a comprehensive understanding of the storyline, a model must not only extract elements but also understand their relationships and generate highly informative captions. In this work, we propose a pipeline that leverages Vision-Language Models (VLMs) to obtain dense, grounded captions. To construct our pipeline, we introduce an attribute-retaining metric that assesses whether all important attributes are identified in the caption. Additionally, we created a densely annotated test set to fairly evaluate open-source VLMs and select the best captioning model according to our metric. Our pipeline generates dense captions with bounding boxes that are quantitatively and qualitatively superior to those produced by specifically trained models, without requiring any additional training. Using this pipeline, we annotated over 2 million panels across 13,000 books, which will be available on the project page https://github.com/emanuelevivoli/ComiCap.
One missing piece in Vision and Language: A Survey on Comics Understanding
Sep 14, 2024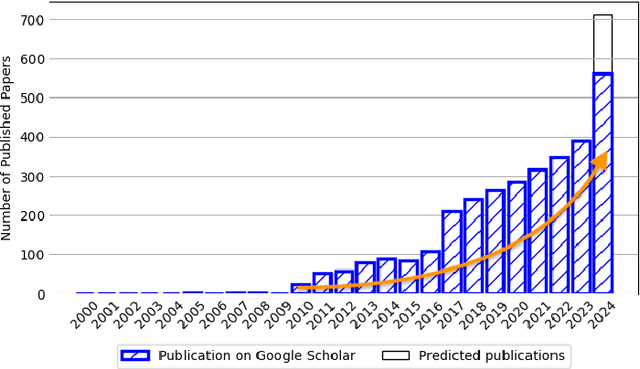
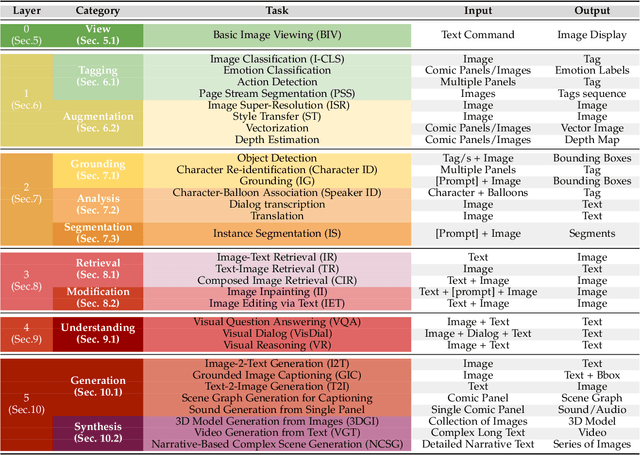
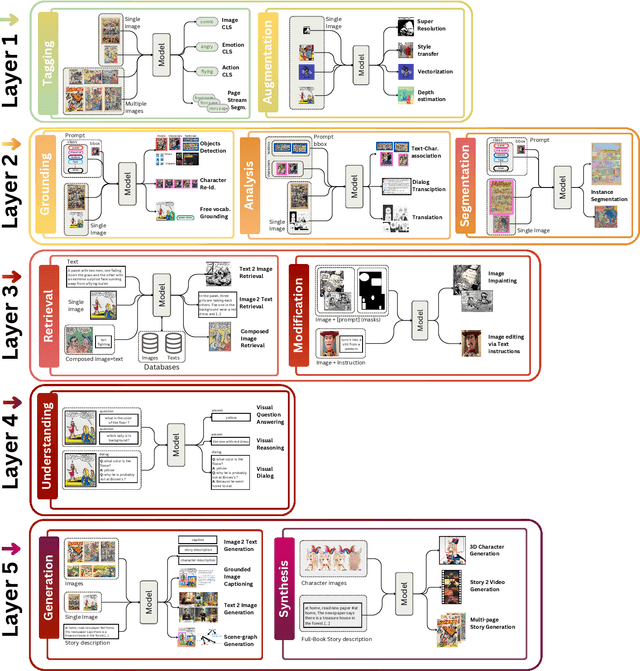
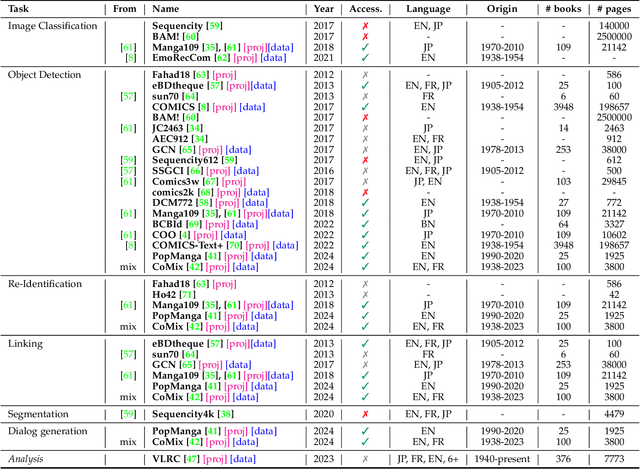
Vision-language models have recently evolved into versatile systems capable of high performance across a range of tasks, such as document understanding, visual question answering, and grounding, often in zero-shot settings. Comics Understanding, a complex and multifaceted field, stands to greatly benefit from these advances. Comics, as a medium, combine rich visual and textual narratives, challenging AI models with tasks that span image classification, object detection, instance segmentation, and deeper narrative comprehension through sequential panels. However, the unique structure of comics -- characterized by creative variations in style, reading order, and non-linear storytelling -- presents a set of challenges distinct from those in other visual-language domains. In this survey, we present a comprehensive review of Comics Understanding from both dataset and task perspectives. Our contributions are fivefold: (1) We analyze the structure of the comics medium, detailing its distinctive compositional elements; (2) We survey the widely used datasets and tasks in comics research, emphasizing their role in advancing the field; (3) We introduce the Layer of Comics Understanding (LoCU) framework, a novel taxonomy that redefines vision-language tasks within comics and lays the foundation for future work; (4) We provide a detailed review and categorization of existing methods following the LoCU framework; (5) Finally, we highlight current research challenges and propose directions for future exploration, particularly in the context of vision-language models applied to comics. This survey is the first to propose a task-oriented framework for comics intelligence and aims to guide future research by addressing critical gaps in data availability and task definition. A project associated with this survey is available at https://github.com/emanuelevivoli/awesome-comics-understanding.
Towards Generative Class Prompt Learning for Few-shot Visual Recognition
Sep 03, 2024



Although foundational vision-language models (VLMs) have proven to be very successful for various semantic discrimination tasks, they still struggle to perform faithfully for fine-grained categorization. Moreover, foundational models trained on one domain do not generalize well on a different domain without fine-tuning. We attribute these to the limitations of the VLM's semantic representations and attempt to improve their fine-grained visual awareness using generative modeling. Specifically, we propose two novel methods: Generative Class Prompt Learning (GCPL) and Contrastive Multi-class Prompt Learning (CoMPLe). Utilizing text-to-image diffusion models, GCPL significantly improves the visio-linguistic synergy in class embeddings by conditioning on few-shot exemplars with learnable class prompts. CoMPLe builds on this foundation by introducing a contrastive learning component that encourages inter-class separation during the generative optimization process. Our empirical results demonstrate that such a generative class prompt learning approach substantially outperform existing methods, offering a better alternative to few shot image recognition challenges. The source code will be made available at: https://github.com/soumitri2001/GCPL.
CoMix: A Comprehensive Benchmark for Multi-Task Comic Understanding
Jul 04, 2024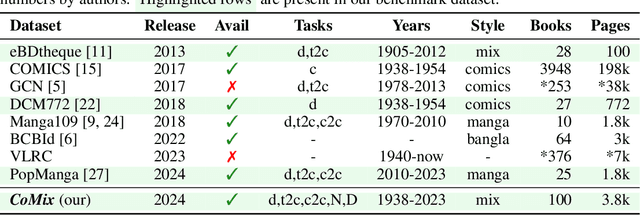



The comic domain is rapidly advancing with the development of single-page analysis and synthesis models. However, evaluation metrics and datasets lag behind, often limited to small-scale or single-style test sets. We introduce a novel benchmark, CoMix, designed to evaluate the multi-task capabilities of models in comic analysis. Unlike existing benchmarks that focus on isolated tasks such as object detection or text recognition, CoMix addresses a broader range of tasks including object detection, speaker identification, character re-identification, reading order, and multi-modal reasoning tasks like character naming and dialogue generation. Our benchmark comprises three existing datasets with expanded annotations to support multi-task evaluation. To mitigate the over-representation of manga-style data, we have incorporated a new dataset of carefully selected American comic-style books, thereby enriching the diversity of comic styles. CoMix is designed to assess pre-trained models in zero-shot and limited fine-tuning settings, probing their transfer capabilities across different comic styles and tasks. The validation split of the benchmark is publicly available for research purposes, and an evaluation server for the held-out test split is also provided. Comparative results between human performance and state-of-the-art models reveal a significant performance gap, highlighting substantial opportunities for advancements in comic understanding. The dataset, baseline models, and code are accessible at the repository link. This initiative sets a new standard for comprehensive comic analysis, providing the community with a common benchmark for evaluation on a large and varied set.
Comics Datasets Framework: Mix of Comics datasets for detection benchmarking
Jul 03, 2024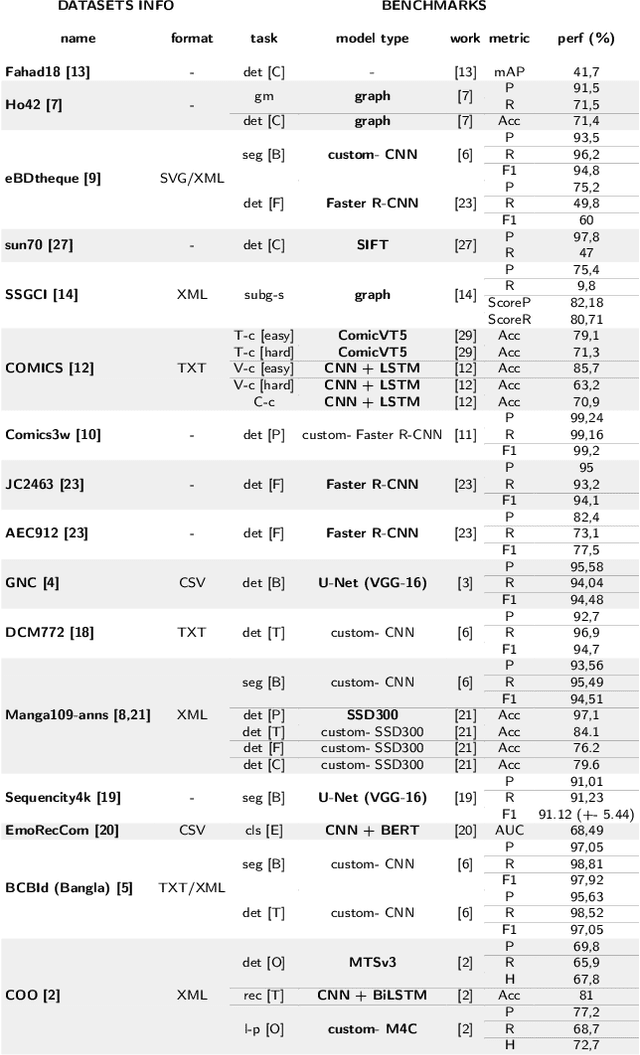
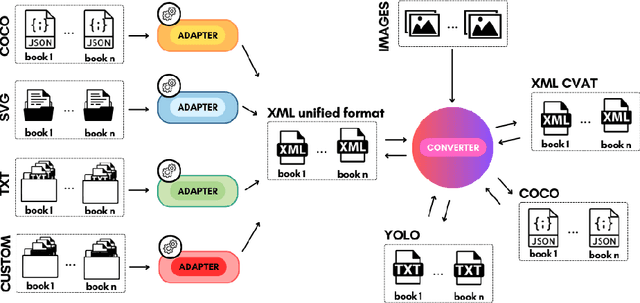
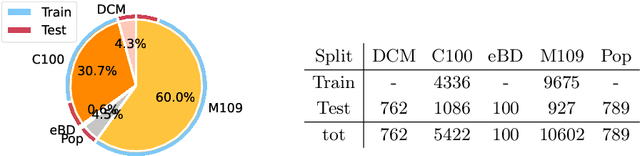
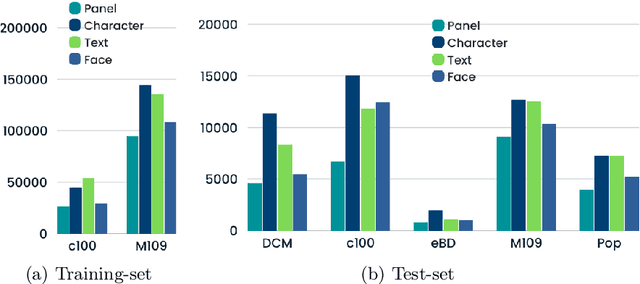
Comics, as a medium, uniquely combine text and images in styles often distinct from real-world visuals. For the past three decades, computational research on comics has evolved from basic object detection to more sophisticated tasks. However, the field faces persistent challenges such as small datasets, inconsistent annotations, inaccessible model weights, and results that cannot be directly compared due to varying train/test splits and metrics. To address these issues, we aim to standardize annotations across datasets, introduce a variety of comic styles into the datasets, and establish benchmark results with clear, replicable settings. Our proposed Comics Datasets Framework standardizes dataset annotations into a common format and addresses the overrepresentation of manga by introducing Comics100, a curated collection of 100 books from the Digital Comics Museum, annotated for detection in our uniform format. We have benchmarked a variety of detection architectures using the Comics Datasets Framework. All related code, model weights, and detailed evaluation processes are available at https://github.com/emanuelevivoli/cdf, ensuring transparency and facilitating replication. This initiative is a significant advancement towards improving object detection in comics, laying the groundwork for more complex computational tasks dependent on precise object recognition.
Multimodal Transformer for Comics Text-Cloze
Mar 06, 2024

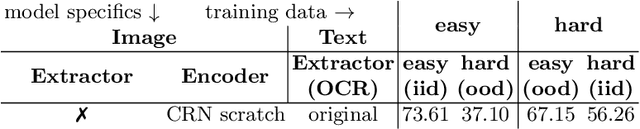
This work explores a closure task in comics, a medium where visual and textual elements are intricately intertwined. Specifically, Text-cloze refers to the task of selecting the correct text to use in a comic panel, given its neighboring panels. Traditional methods based on recurrent neural networks have struggled with this task due to limited OCR accuracy and inherent model limitations. We introduce a novel Multimodal Large Language Model (Multimodal-LLM) architecture, specifically designed for Text-cloze, achieving a 10% improvement over existing state-of-the-art models in both its easy and hard variants. Central to our approach is a Domain-Adapted ResNet-50 based visual encoder, fine-tuned to the comics domain in a self-supervised manner using SimCLR. This encoder delivers comparable results to more complex models with just one-fifth of the parameters. Additionally, we release new OCR annotations for this dataset, enhancing model input quality and resulting in another 1% improvement. Finally, we extend the task to a generative format, establishing new baselines and expanding the research possibilities in the field of comics analysis.
Error assessment of microwave holography inversion for shallow buried objects
Mar 27, 2023Holographic imaging is a technique that uses microwave energy to create a three-dimensional image of an object or scene. This technology has potential applications in land mine detection, as the long-wavelength microwave energy can penetrate the ground and create an image of hidden objects without the need for direct physical contact. However, the inversion algorithms commonly used to digitally reconstruct 3D images from holographic images, such as Convolution, Angular Spectrum, and Fresnel, are known to have limitations and can introduce errors in the reconstructed image. Despite these challenges, the use of holographic radar at around 2 GHz in combination with holographic imaging techniques for land mine detection allows to recover size and shape of buried objects. In this paper, we estimate the reconstruction error for the convolution algorithm based on hologram imaging simulation and assess these errors recommending an increase in the scanner area, considering the limitations that the system has and the expected error reduction.
CTE: A Dataset for Contextualized Table Extraction
Feb 13, 2023



Relevant information in documents is often summarized in tables, helping the reader to identify useful facts. Most benchmark datasets support either document layout analysis or table understanding, but lack in providing data to apply both tasks in a unified way. We define the task of Contextualized Table Extraction (CTE), which aims to extract and define the structure of tables considering the textual context of the document. The dataset comprises 75k fully annotated pages of scientific papers, including more than 35k tables. Data are gathered from PubMed Central, merging the information provided by annotations in the PubTables-1M and PubLayNet datasets. The dataset can support CTE and adds new classes to the original ones. The generated annotations can be used to develop end-to-end pipelines for various tasks, including document layout analysis, table detection, structure recognition, and functional analysis. We formally define CTE and evaluation metrics, showing which subtasks can be tackled, describing advantages, limitations, and future works of this collection of data. Annotations and code will be accessible a https://github.com/AILab-UniFI/cte-dataset.