 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComicsPAP: understanding comic strips by picking the correct panel
Mar 11, 2025Large multimodal models (LMMs) have made impressive strides in image captioning, VQA, and video comprehension, yet they still struggle with the intricate temporal and spatial cues found in comics. To address this gap, we introduce ComicsPAP, a large-scale benchmark designed for comic strip understanding. Comprising over 100k samples and organized into 5 subtasks under a Pick-a-Panel framework, ComicsPAP demands models to identify the missing panel in a sequence. Our evaluations, conducted under both multi-image and single-image protocols, reveal that current state-of-the-art LMMs perform near chance on these tasks, underscoring significant limitations in capturing sequential and contextual dependencies. To close the gap, we adapted LMMs for comic strip understanding, obtaining better results on ComicsPAP than 10x bigger models, demonstrating that ComicsPAP offers a robust resource to drive future research in multimodal comic comprehension.
Multimodal Transformer for Comics Text-Cloze
Mar 06, 2024

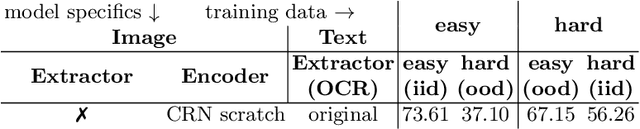
This work explores a closure task in comics, a medium where visual and textual elements are intricately intertwined. Specifically, Text-cloze refers to the task of selecting the correct text to use in a comic panel, given its neighboring panels. Traditional methods based on recurrent neural networks have struggled with this task due to limited OCR accuracy and inherent model limitations. We introduce a novel Multimodal Large Language Model (Multimodal-LLM) architecture, specifically designed for Text-cloze, achieving a 10% improvement over existing state-of-the-art models in both its easy and hard variants. Central to our approach is a Domain-Adapted ResNet-50 based visual encoder, fine-tuned to the comics domain in a self-supervised manner using SimCLR. This encoder delivers comparable results to more complex models with just one-fifth of the parameters. Additionally, we release new OCR annotations for this dataset, enhancing model input quality and resulting in another 1% improvement. Finally, we extend the task to a generative format, establishing new baselines and expanding the research possibilities in the field of comics analysis.