 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocVXQA: Context-Aware Visual Explanations for Document Question Answering
May 12, 2025We propose DocVXQA, a novel framework for visually self-explainable document question answering. The framework is designed not only to produce accurate answers to questions but also to learn visual heatmaps that highlight contextually critical regions, thereby offering interpretable justifications for the model's decisions. To integrate explanations into the learning process, we quantitatively formulate explainability principles as explicit learning objectives. Unlike conventional methods that emphasize only the regions pertinent to the answer, our framework delivers explanations that are \textit{contextually sufficient} while remaining \textit{representation-efficient}. This fosters user trust while achieving a balance between predictive performance and interpretability in DocVQA applications. Extensive experiments, including human evaluation, provide strong evidence supporting the effectiveness of our method. The code is available at https://github.com/dali92002/DocVXQA.
NeurIPS 2023 Competition: Privacy Preserving Federated Learning Document VQA
Nov 06, 2024



The Privacy Preserving Federated Learning Document VQA (PFL-DocVQA) competition challenged the community to develop provably private and communication-efficient solutions in a federated setting for a real-life use case: invoice processing. The competition introduced a dataset of real invoice documents, along with associated questions and answers requiring information extraction and reasoning over the document images. Thereby, it brings together researchers and expertise from the document analysis, privacy, and federated learning communities. Participants fine-tuned a pre-trained, state-of-the-art Document Visual Question Answering model provided by the organizers for this new domain, mimicking a typical federated invoice processing setup. The base model is a multi-modal generative language model, and sensitive information could be exposed through either the visual or textual input modality. Participants proposed elegant solutions to reduce communication costs while maintaining a minimum utility threshold in track 1 and to protect all information from each document provider using differential privacy in track 2. The competition served as a new testbed for developing and testing private federated learning methods, simultaneously raising awareness about privacy within the document image analysis and recognition community. Ultimately, the competition analysis provides best practices and recommendations for successfully running privacy-focused federated learning challenges in the future.
One missing piece in Vision and Language: A Survey on Comics Understanding
Sep 14, 2024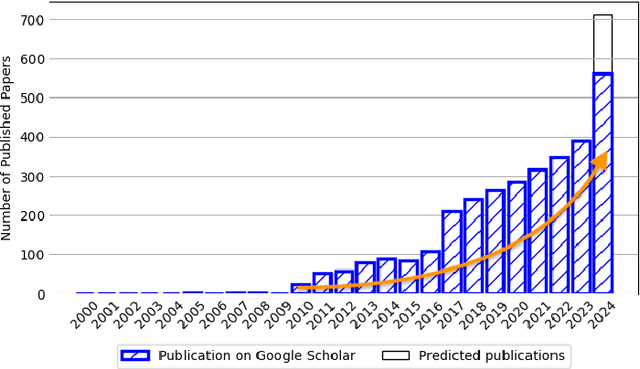
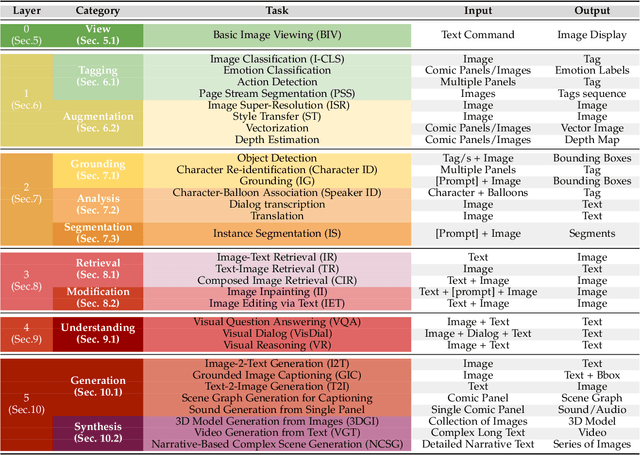
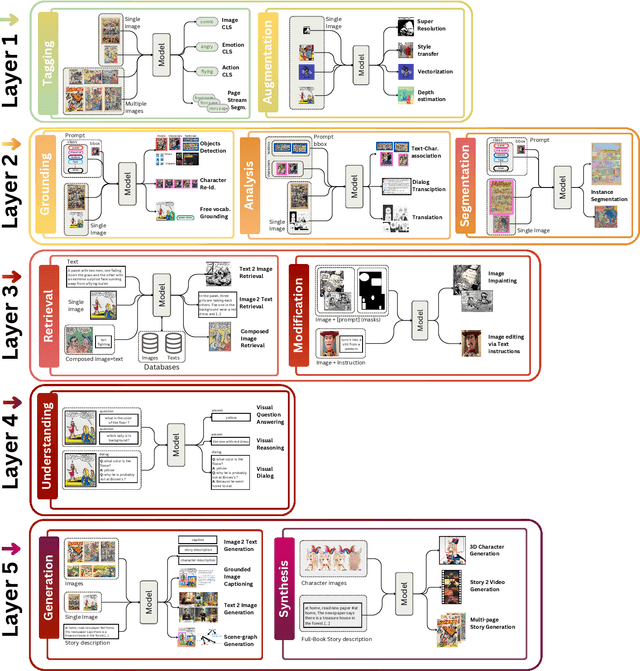
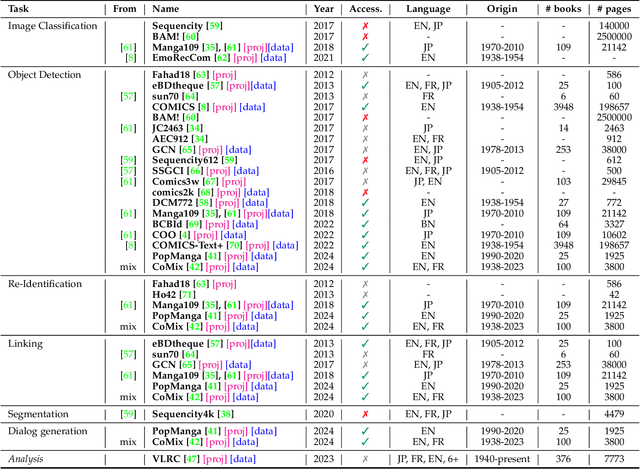
Vision-language models have recently evolved into versatile systems capable of high performance across a range of tasks, such as document understanding, visual question answering, and grounding, often in zero-shot settings. Comics Understanding, a complex and multifaceted field, stands to greatly benefit from these advances. Comics, as a medium, combine rich visual and textual narratives, challenging AI models with tasks that span image classification, object detection, instance segmentation, and deeper narrative comprehension through sequential panels. However, the unique structure of comics -- characterized by creative variations in style, reading order, and non-linear storytelling -- presents a set of challenges distinct from those in other visual-language domains. In this survey, we present a comprehensive review of Comics Understanding from both dataset and task perspectives. Our contributions are fivefold: (1) We analyze the structure of the comics medium, detailing its distinctive compositional elements; (2) We survey the widely used datasets and tasks in comics research, emphasizing their role in advancing the field; (3) We introduce the Layer of Comics Understanding (LoCU) framework, a novel taxonomy that redefines vision-language tasks within comics and lays the foundation for future work; (4) We provide a detailed review and categorization of existing methods following the LoCU framework; (5) Finally, we highlight current research challenges and propose directions for future exploration, particularly in the context of vision-language models applied to comics. This survey is the first to propose a task-oriented framework for comics intelligence and aims to guide future research by addressing critical gaps in data availability and task definition. A project associated with this survey is available at https://github.com/emanuelevivoli/awesome-comics-understanding.
GRIF-DM: Generation of Rich Impression Fonts using Diffusion Models
Aug 14, 2024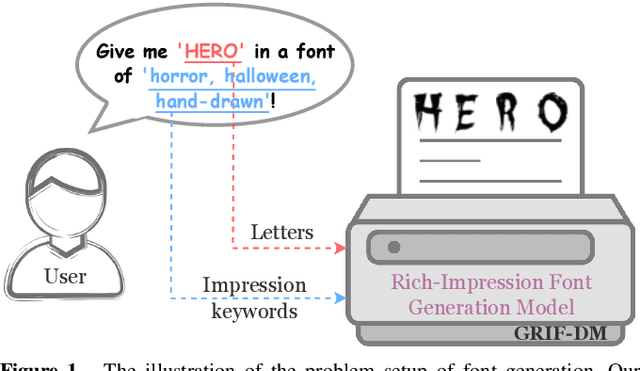
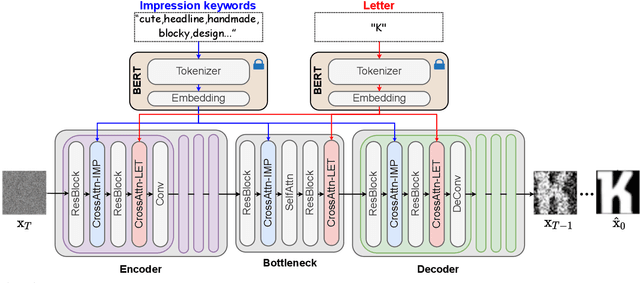


Fonts are integral to creative endeavors, design processes, and artistic productions. The appropriate selection of a font can significantly enhance artwork and endow advertisements with a higher level of expressivity. Despite the availability of numerous diverse font designs online, traditional retrieval-based methods for font selection are increasingly being supplanted by generation-based approaches. These newer methods offer enhanced flexibility, catering to specific user preferences and capturing unique stylistic impressions. However, current impression font techniques based on Generative Adversarial Networks (GANs) necessitate the utilization of multiple auxiliary losses to provide guidance during generation. Furthermore, these methods commonly employ weighted summation for the fusion of impression-related keywords. This leads to generic vectors with the addition of more impression keywords, ultimately lacking in detail generation capacity. In this paper, we introduce a diffusion-based method, termed \ourmethod, to generate fonts that vividly embody specific impressions, utilizing an input consisting of a single letter and a set of descriptive impression keywords. The core innovation of \ourmethod lies in the development of dual cross-attention modules, which process the characteristics of the letters and impression keywords independently but synergistically, ensuring effective integration of both types of information. Our experimental results, conducted on the MyFonts dataset, affirm that this method is capable of producing realistic, vibrant, and high-fidelity fonts that are closely aligned with user specifications. This confirms the potential of our approach to revolutionize font generation by accommodating a broad spectrum of user-driven design requirements. Our code is publicly available at \url{https://github.com/leitro/GRIF-DM}.
Machine Unlearning for Document Classification
Apr 29, 2024



Document understanding models have recently demonstrated remarkable performance by leveraging extensive collections of user documents. However, since documents often contain large amounts of personal data, their usage can pose a threat to user privacy and weaken the bonds of trust between humans and AI services. In response to these concerns, legislation advocating ``the right to be forgotten" has recently been proposed, allowing users to request the removal of private information from computer systems and neural network models. A novel approach, known as machine unlearning, has emerged to make AI models forget about a particular class of data. In our research, we explore machine unlearning for document classification problems, representing, to the best of our knowledge, the first investigation into this area. Specifically, we consider a realistic scenario where a remote server houses a well-trained model and possesses only a small portion of training data. This setup is designed for efficient forgetting manipulation. This work represents a pioneering step towards the development of machine unlearning methods aimed at addressing privacy concerns in document analysis applications. Our code is publicly available at \url{https://github.com/leitro/MachineUnlearning-DocClassification}.
Privacy-Aware Document Visual Question Answering
Dec 15, 2023

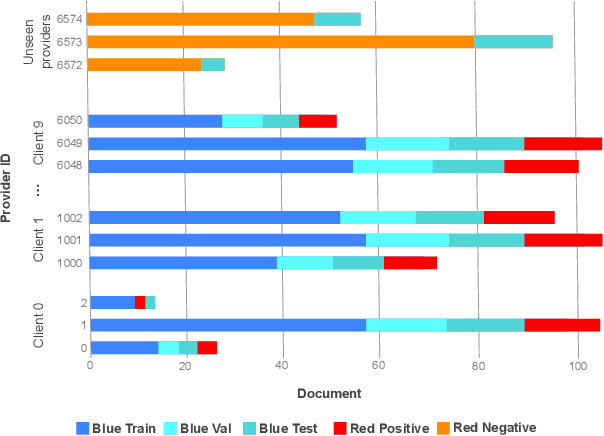

Document Visual Question Answering (DocVQA) is a fast growing branch of document understanding. Despite the fact that documents contain sensitive or copyrighted information, none of the current DocVQA methods offers strong privacy guarantees. In this work, we explore privacy in the domain of DocVQA for the first time. We highlight privacy issues in state of the art multi-modal LLM models used for DocVQA, and explore possible solutions. Specifically, we focus on the invoice processing use case as a realistic, widely used scenario for document understanding, and propose a large scale DocVQA dataset comprising invoice documents and associated questions and answers. We employ a federated learning scheme, that reflects the real-life distribution of documents in different businesses, and we explore the use case where the ID of the invoice issuer is the sensitive information to be protected. We demonstrate that non-private models tend to memorise, behaviour that can lead to exposing private information. We then evaluate baseline training schemes employing federated learning and differential privacy in this multi-modal scenario, where the sensitive information might be exposed through any of the two input modalities: vision (document image) or language (OCR tokens). Finally, we design an attack exploiting the memorisation effect of the model, and demonstrate its effectiveness in probing different DocVQA models.
CSSL-MHTR: Continual Self-Supervised Learning for Scalable Multi-script Handwritten Text Recognition
Mar 16, 2023Self-supervised learning has recently emerged as a strong alternative in document analysis. These approaches are now capable of learning high-quality image representations and overcoming the limitations of supervised methods, which require a large amount of labeled data. However, these methods are unable to capture new knowledge in an incremental fashion, where data is presented to the model sequentially, which is closer to the realistic scenario. In this paper, we explore the potential of continual self-supervised learning to alleviate the catastrophic forgetting problem in handwritten text recognition, as an example of sequence recognition. Our method consists in adding intermediate layers called adapters for each task, and efficiently distilling knowledge from the previous model while learning the current task. Our proposed framework is efficient in both computation and memory complexity. To demonstrate its effectiveness, we evaluate our method by transferring the learned model to diverse text recognition downstream tasks, including Latin and non-Latin scripts. As far as we know, this is the first application of continual self-supervised learning for handwritten text recognition. We attain state-of-the-art performance on English, Italian and Russian scripts, whilst adding only a few parameters per task. The code and trained models will be publicly available.
ST-KeyS: Self-Supervised Transformer for Keyword Spotting in Historical Handwritten Documents
Mar 06, 2023



Keyword spotting (KWS) in historical documents is an important tool for the initial exploration of digitized collections. Nowadays, the most efficient KWS methods are relying on machine learning techniques that require a large amount of annotated training data. However, in the case of historical manuscripts, there is a lack of annotated corpus for training. To handle the data scarcity issue, we investigate the merits of the self-supervised learning to extract useful representations of the input data without relying on human annotations and then using these representations in the downstream task. We propose ST-KeyS, a masked auto-encoder model based on vision transformers where the pretraining stage is based on the mask-and-predict paradigm, without the need of labeled data. In the fine-tuning stage, the pre-trained encoder is integrated into a siamese neural network model that is fine-tuned to improve feature embedding from the input images. We further improve the image representation using pyramidal histogram of characters (PHOC) embedding to create and exploit an intermediate representation of images based on text attributes. In an exhaustive experimental evaluation on three widely used benchmark datasets (Botany, Alvermann Konzilsprotokolle and George Washington), the proposed approach outperforms state-of-the-art methods trained on the same datasets.
A Few Shot Multi-Representation Approach for N-gram Spotting in Historical Manuscripts
Sep 21, 2022
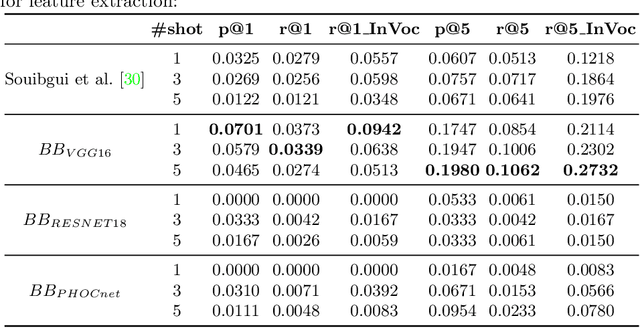

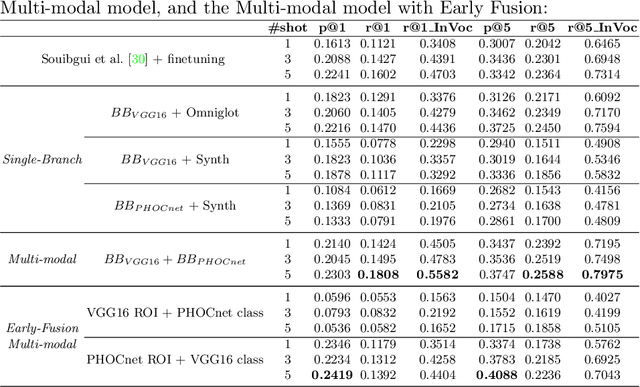
Despite recent advances in automatic text recognition, the performance remains moderate when it comes to historical manuscripts. This is mainly because of the scarcity of available labelled data to train the data-hungry Handwritten Text Recognition (HTR) models. The Keyword Spotting System (KWS) provides a valid alternative to HTR due to the reduction in error rate, but it is usually limited to a closed reference vocabulary. In this paper, we propose a few-shot learning paradigm for spotting sequences of a few characters (N-gram) that requires a small amount of labelled training data. We exhibit that recognition of important n-grams could reduce the system's dependency on vocabulary. In this case, an out-of-vocabulary (OOV) word in an input handwritten line image could be a sequence of n-grams that belong to the lexicon. An extensive experimental evaluation of our proposed multi-representation approach was carried out on a subset of Bentham's historical manuscript collections to obtain some really promising results in this direction.
Text-DIAE: Degradation Invariant Autoencoders for Text Recognition and Document Enhancement
Mar 16, 2022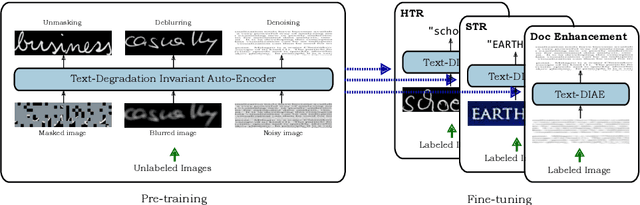
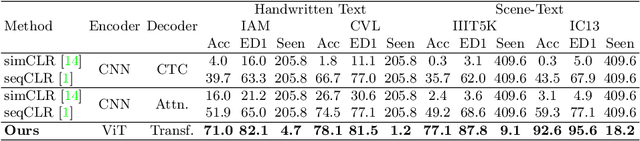
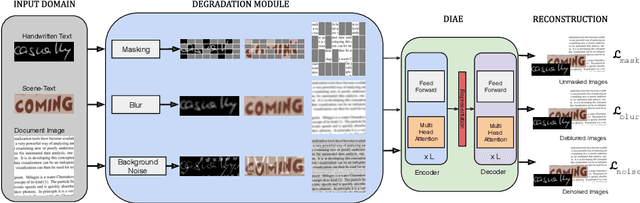
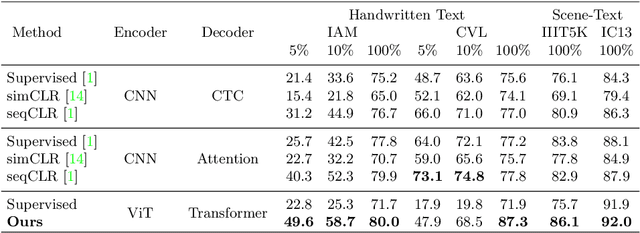
In this work, we propose Text-Degradation Invariant Auto Encoder (Text-DIAE) aimed to solve two tasks, text recognition (handwritten or scene-text) and document image enhancement. We define three pretext tasks as learning objectives to be optimized during pre-training without the usage of labelled data. Each of the pre-text objectives is specifically tailored for the final downstream tasks. We conduct several ablation experiments that show the importance of each degradation for a specific domain. Exhaustive experimentation shows that our method does not have limitations of previous state-of-the-art based on contrastive losses while at the same time requiring essentially fewer data samples to converge. Finally, we demonstrate that our method surpasses the state-of-the-art significantly in existing supervised and self-supervised settings in handwritten and scene text recognition and document image enhancement. Our code and trained models will be made publicly available at~\url{ http://Upon_Acceptance}.