 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeurIPS 2023 Competition: Privacy Preserving Federated Learning Document VQA
Nov 06, 2024



The Privacy Preserving Federated Learning Document VQA (PFL-DocVQA) competition challenged the community to develop provably private and communication-efficient solutions in a federated setting for a real-life use case: invoice processing. The competition introduced a dataset of real invoice documents, along with associated questions and answers requiring information extraction and reasoning over the document images. Thereby, it brings together researchers and expertise from the document analysis, privacy, and federated learning communities. Participants fine-tuned a pre-trained, state-of-the-art Document Visual Question Answering model provided by the organizers for this new domain, mimicking a typical federated invoice processing setup. The base model is a multi-modal generative language model, and sensitive information could be exposed through either the visual or textual input modality. Participants proposed elegant solutions to reduce communication costs while maintaining a minimum utility threshold in track 1 and to protect all information from each document provider using differential privacy in track 2. The competition served as a new testbed for developing and testing private federated learning methods, simultaneously raising awareness about privacy within the document image analysis and recognition community. Ultimately, the competition analysis provides best practices and recommendations for successfully running privacy-focused federated learning challenges in the future.
Multi-Page Document Visual Question Answering using Self-Attention Scoring Mechanism
Apr 29, 2024

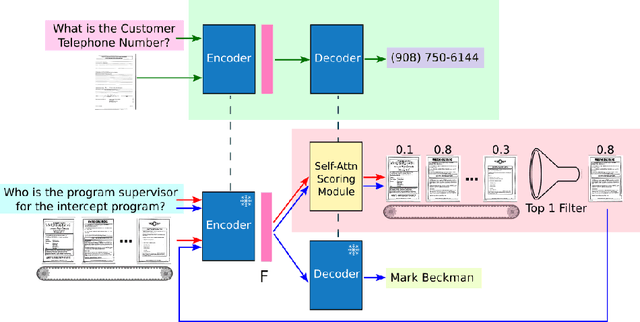
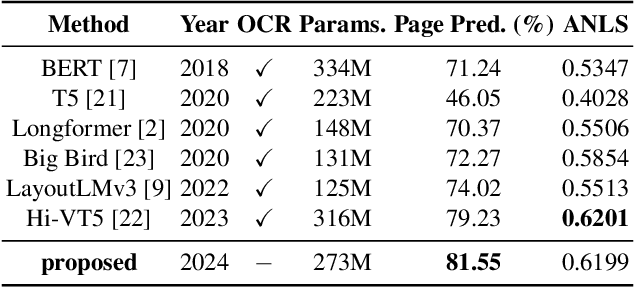
Documents are 2-dimensional carriers of written communication, and as such their interpretation requires a multi-modal approach where textual and visual information are efficiently combined. Document Visual Question Answering (Document VQA), due to this multi-modal nature, has garnered significant interest from both the document understanding and natural language processing communities. The state-of-the-art single-page Document VQA methods show impressive performance, yet in multi-page scenarios, these methods struggle. They have to concatenate all pages into one large page for processing, demanding substantial GPU resources, even for evaluation. In this work, we propose a novel method and efficient training strategy for multi-page Document VQA tasks. In particular, we employ a visual-only document representation, leveraging the encoder from a document understanding model, Pix2Struct. Our approach utilizes a self-attention scoring mechanism to generate relevance scores for each document page, enabling the retrieval of pertinent pages. This adaptation allows us to extend single-page Document VQA models to multi-page scenarios without constraints on the number of pages during evaluation, all with minimal demand for GPU resources. Our extensive experiments demonstrate not only achieving state-of-the-art performance without the need for Optical Character Recognition (OCR), but also sustained performance in scenarios extending to documents of nearly 800 pages compared to a maximum of 20 pages in the MP-DocVQA dataset. Our code is publicly available at \url{https://github.com/leitro/SelfAttnScoring-MPDocVQA}.
Privacy-Aware Document Visual Question Answering
Dec 15, 2023

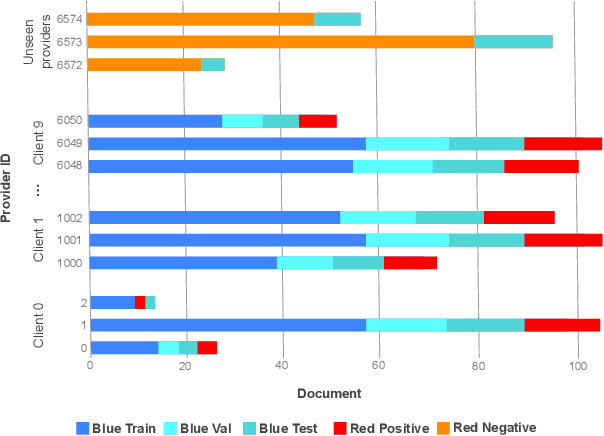

Document Visual Question Answering (DocVQA) is a fast growing branch of document understanding. Despite the fact that documents contain sensitive or copyrighted information, none of the current DocVQA methods offers strong privacy guarantees. In this work, we explore privacy in the domain of DocVQA for the first time. We highlight privacy issues in state of the art multi-modal LLM models used for DocVQA, and explore possible solutions. Specifically, we focus on the invoice processing use case as a realistic, widely used scenario for document understanding, and propose a large scale DocVQA dataset comprising invoice documents and associated questions and answers. We employ a federated learning scheme, that reflects the real-life distribution of documents in different businesses, and we explore the use case where the ID of the invoice issuer is the sensitive information to be protected. We demonstrate that non-private models tend to memorise, behaviour that can lead to exposing private information. We then evaluate baseline training schemes employing federated learning and differential privacy in this multi-modal scenario, where the sensitive information might be exposed through any of the two input modalities: vision (document image) or language (OCR tokens). Finally, we design an attack exploiting the memorisation effect of the model, and demonstrate its effectiveness in probing different DocVQA models.
Hierarchical multimodal transformers for Multi-Page DocVQA
Dec 07, 2022
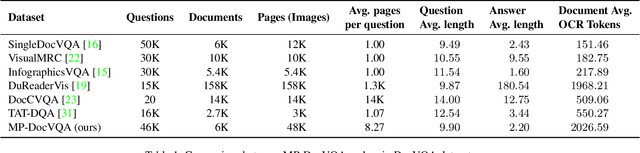

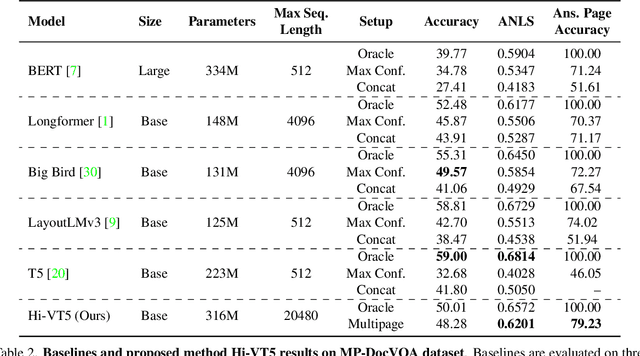
Document Visual Question Answering (DocVQA) refers to the task of answering questions from document images. Existing work on DocVQA only considers single-page documents. However, in real scenarios documents are mostly composed of multiple pages that should be processed altogether. In this work we extend DocVQA to the multi-page scenario. For that, we first create a new dataset, MP-DocVQA, where questions are posed over multi-page documents instead of single pages. Second, we propose a new hierarchical method, Hi-VT5, based on the T5 architecture, that overcomes the limitations of current methods to process long multi-page documents. The proposed method is based on a hierarchical transformer architecture where the encoder summarizes the most relevant information of every page and then, the decoder takes this summarized information to generate the final answer. Through extensive experimentation, we demonstrate that our method is able, in a single stage, to answer the questions and provide the page that contains the relevant information to find the answer, which can be used as a kind of explainability measure.
OCR-IDL: OCR Annotations for Industry Document Library Dataset
Feb 25, 2022

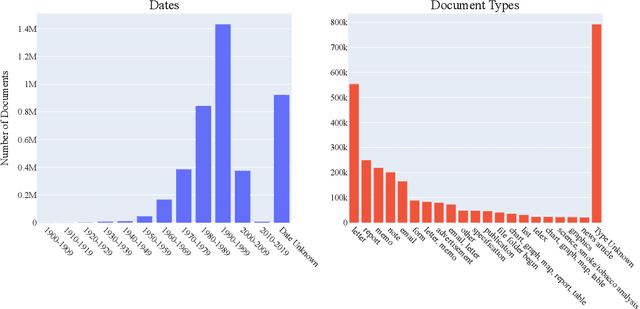
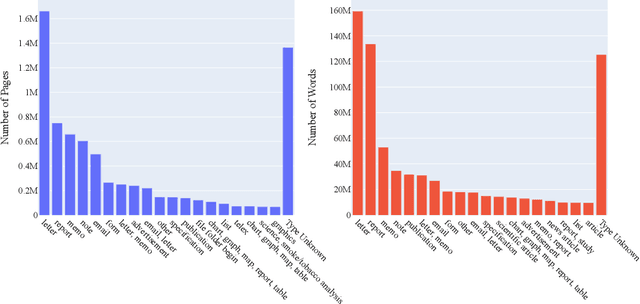
Pretraining has proven successful in Document Intelligence tasks where deluge of documents are used to pretrain the models only later to be finetuned on downstream tasks. One of the problems of the pretraining approaches is the inconsistent usage of pretraining data with different OCR engines leading to incomparable results between models. In other words, it is not obvious whether the performance gain is coming from diverse usage of amount of data and distinct OCR engines or from the proposed models. To remedy the problem, we make public the OCR annotations for IDL documents using commercial OCR engine given their superior performance over open source OCR models. The contributed dataset (OCR-IDL) has an estimated monetary value over 20K US$. It is our hope that OCR-IDL can be a starting point for future works on Document Intelligence. All of our data and its collection process with the annotations can be found in https://github.com/furkanbiten/idl_data.
ICDAR 2021 Competition on Document VisualQuestion Answering
Nov 10, 2021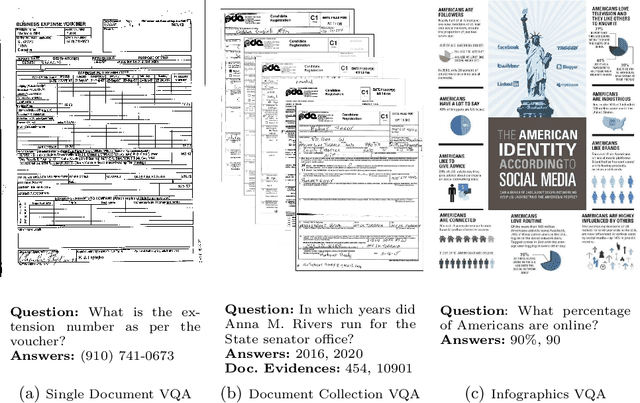
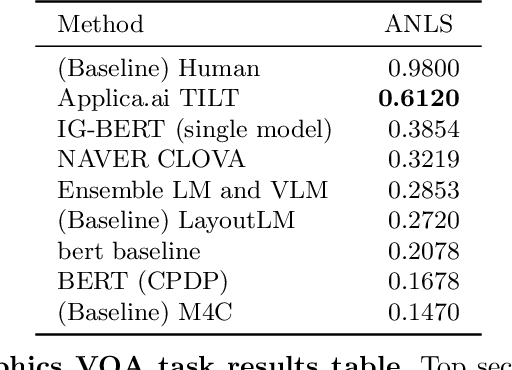
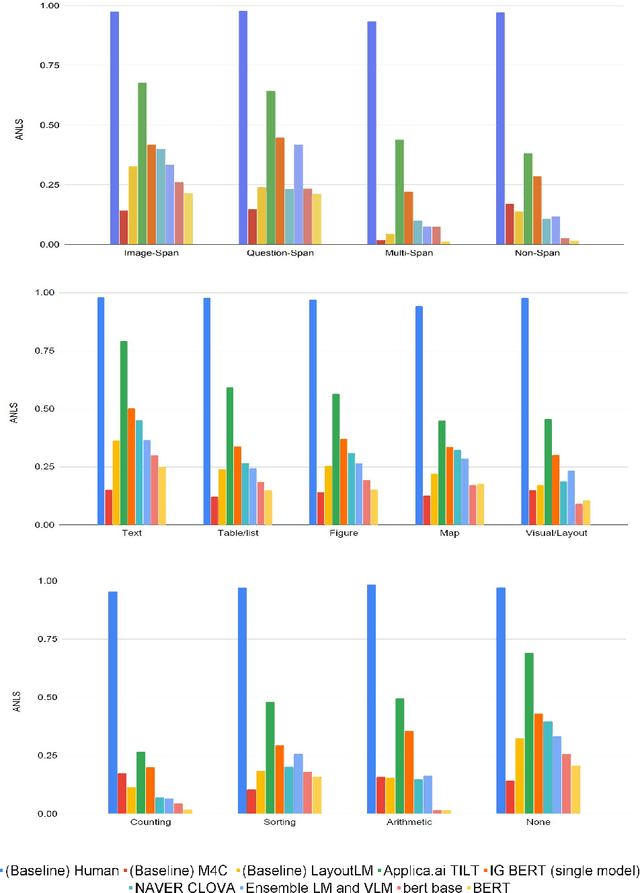
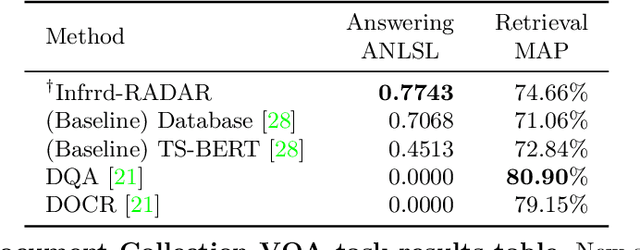
In this report we present results of the ICDAR 2021 edition of the Document Visual Question Challenges. This edition complements the previous tasks on Single Document VQA and Document Collection VQA with a newly introduced on Infographics VQA. Infographics VQA is based on a new dataset of more than 5,000 infographics images and 30,000 question-answer pairs. The winner methods have scored 0.6120 ANLS in Infographics VQA task, 0.7743 ANLSL in Document Collection VQA task and 0.8705 ANLS in Single Document VQA. We present a summary of the datasets used for each task, description of each of the submitted methods and the results and analysis of their performance. A summary of the progress made on Single Document VQA since the first edition of the DocVQA 2020 challenge is also presented.
Document Collection Visual Question Answering
Apr 27, 2021
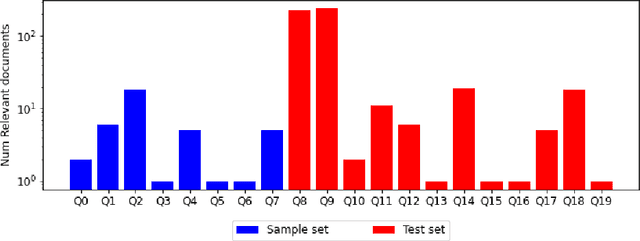


Current tasks and methods in Document Understanding aims to process documents as single elements. However, documents are usually organized in collections (historical records, purchase invoices), that provide context useful for their interpretation. To address this problem, we introduce Document Collection Visual Question Answering (DocCVQA) a new dataset and related task, where questions are posed over a whole collection of document images and the goal is not only to provide the answer to the given question, but also to retrieve the set of documents that contain the information needed to infer the answer. Along with the dataset we propose a new evaluation metric and baselines which provide further insights to the new dataset and task.
Multimodal grid features and cell pointers for Scene Text Visual Question Answering
Jun 25, 2020
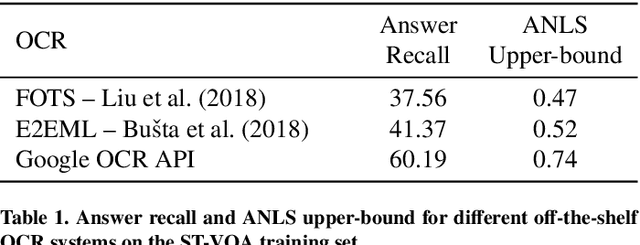
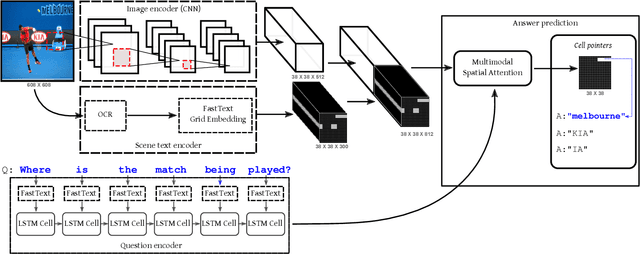
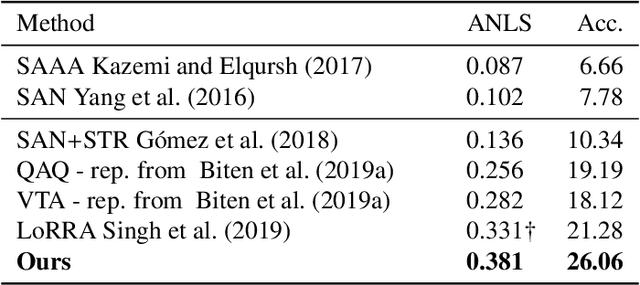
This paper presents a new model for the task of scene text visual question answering, in which questions about a given image can only be answered by reading and understanding scene text that is present in it. The proposed model is based on an attention mechanism that attends to multi-modal features conditioned to the question, allowing it to reason jointly about the textual and visual modalities in the scene. The output weights of this attention module over the grid of multi-modal spatial features are interpreted as the probability that a certain spatial location of the image contains the answer text the to the given question. Our experiments demonstrate competitive performance in two standard datasets. Furthermore, this paper provides a novel analysis of the ST-VQA dataset based on a human performance study.
ICDAR 2019 Competition on Scene Text Visual Question Answering
Jun 30, 2019
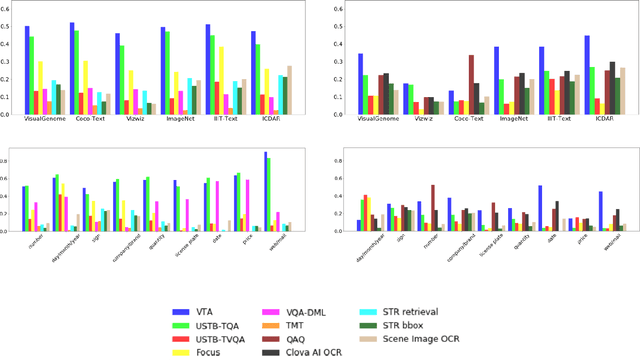
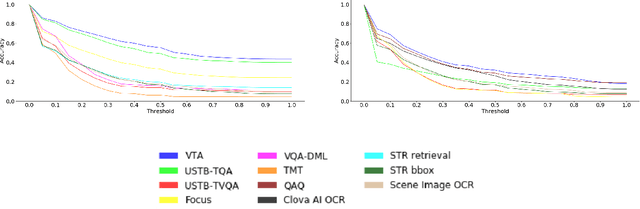
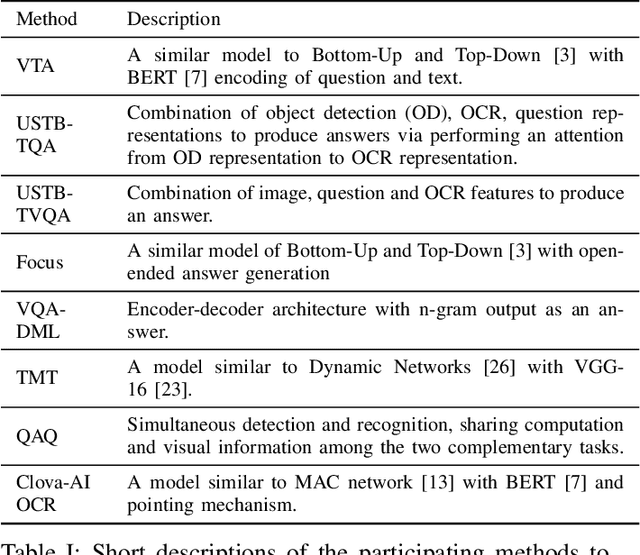
This paper presents final results of ICDAR 2019 Scene Text Visual Question Answering competition (ST-VQA). ST-VQA introduces an important aspect that is not addressed by any Visual Question Answering system up to date, namely the incorporation of scene text to answer questions asked about an image. The competition introduces a new dataset comprising 23,038 images annotated with 31,791 question/answer pairs where the answer is always grounded on text instances present in the image. The images are taken from 7 different public computer vision datasets, covering a wide range of scenarios. The competition was structured in three tasks of increasing difficulty, that require reading the text in a scene and understanding it in the context of the scene, to correctly answer a given question. A novel evaluation metric is presented, which elegantly assesses both key capabilities expected from an optimal model: text recognition and image understanding. A detailed analysis of results from different participants is showcased, which provides insight into the current capabilities of VQA systems that can read. We firmly believe the dataset proposed in this challenge will be an important milestone to consider towards a path of more robust and general models that can exploit scene text to achieve holistic image understanding.