 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron 3 Ultra: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Jun 12, 2026We introduce Nemotron 3 Ultra, a 550 billion total and 55 billion active parameter Mixture-of-Experts Hybrid Mamba-Attention language model. We pre-trained Nemotron 3 Ultra on 20 trillion text tokens, then extended the context length to 1M tokens, and post-trained using Supervised Fine Tuning (SFT), Reinforcement Learning (RL), and Multi-teacher On-Policy Distillation (MOPD). Nemotron 3 Ultra is our most capable model yet, employing multiple key technologies - LatentMoE, Multi Token Prediction (MTP), NVFP4 pre-training, multi-environment RLVR, MOPD, and reasoning budget control. Nemotron 3 Ultra achieves up to ~6x higher inference throughput as compared to state-of-the-art publicly available LLMs while attaining on-par accuracy. The state-of-the-art accuracy, high inference throughput, and 1M token context length make Nemotron 3 Ultra ideal for long-running autonomous agentic tasks. We open-source the base, post-trained, and quantized checkpoints, along with the training data and recipe on HuggingFace.
Nemotron 3 Nano Omni: Efficient and Open Multimodal Intelligence
Apr 27, 2026We introduce Nemotron 3 Nano Omni, the latest model in the Nemotron multimodal series and the first to natively support audio inputs alongside text, images, and video. Nemotron 3 Nano Omni delivers consistent accuracy improvements over its predecessor, Nemotron Nano V2 VL, across all modalities, enabled by advances in architecture, training data and recipes. In particular, Nemotron 3 delivers leading results in real-world document understanding, long audio-video comprehension, and agentic computer use. Built on the highly efficient Nemotron 3 Nano 30B-A3B backbone, Nemotron 3 Nano Omni further incorporates innovative multimodal token-reduction techniques to deliver substantially lower inference latency and higher throughput than other models of similar size. We are releasing model checkpoints in BF16, FP8, and FP4 formats, along with portions of the training data and codebase to facilitate further research and development.
Nemotron 3 Super: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Apr 14, 2026We describe the pre-training, post-training, and quantization of Nemotron 3 Super, a 120 billion (active 12 billion) parameter hybrid Mamba-Attention Mixture-of-Experts model. Nemotron 3 Super is the first model in the Nemotron 3 family to 1) be pre-trained in NVFP4, 2) leverage LatentMoE, a new Mixture-of-Experts architecture that optimizes for both accuracy per FLOP and accuracy per parameter, and 3) include MTP layers for inference acceleration through native speculative decoding. We pre-trained Nemotron 3 Super on 25 trillion tokens followed by post-training using supervised fine tuning (SFT) and reinforcement learning (RL). The final model supports up to 1M context length and achieves comparable accuracy on common benchmarks, while also achieving up to 2.2x and 7.5x higher inference throughput compared to GPT-OSS-120B and Qwen3.5-122B, respectively. Nemotron 3 Super datasets, along with the base, post-trained, and quantized checkpoints, are open-sourced on HuggingFace.
RI-Mamba: Rotation-Invariant Mamba for Robust Text-to-Shape Retrieval
Feb 12, 20263D assets have rapidly expanded in quantity and diversity due to the growing popularity of virtual reality and gaming. As a result, text-to-shape retrieval has become essential in facilitating intuitive search within large repositories. However, existing methods require canonical poses and support few object categories, limiting their real-world applicability where objects can belong to diverse classes and appear in random orientations. To address this challenge, we propose RI-Mamba, the first rotation-invariant state-space model for point clouds. RI-Mamba defines global and local reference frames to disentangle pose from geometry and uses Hilbert sorting to construct token sequences with meaningful geometric structure while maintaining rotation invariance. We further introduce a novel strategy to compute orientational embeddings and reintegrate them via feature-wise linear modulation, effectively recovering spatial context and enhancing model expressiveness. Our strategy is inherently compatible with state-space models and operates in linear time. To scale up retrieval, we adopt cross-modal contrastive learning with automated triplet generation, allowing training on diverse datasets without manual annotation. Extensive experiments demonstrate RI-Mamba's superior representational capacity and robustness, achieving state-of-the-art performance on the OmniObject3D benchmark across more than 200 object categories under arbitrary orientations. Our code will be made available at https://github.com/ndkhanh360/RI-Mamba.git.
Retrieving Objects from 3D Scenes with Box-Guided Open-Vocabulary Instance Segmentation
Dec 22, 2025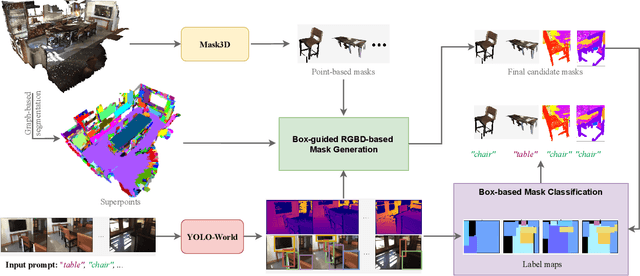



Locating and retrieving objects from scene-level point clouds is a challenging problem with broad applications in robotics and augmented reality. This task is commonly formulated as open-vocabulary 3D instance segmentation. Although recent methods demonstrate strong performance, they depend heavily on SAM and CLIP to generate and classify 3D instance masks from images accompanying the point cloud, leading to substantial computational overhead and slow processing that limit their deployment in real-world settings. Open-YOLO 3D alleviates this issue by using a real-time 2D detector to classify class-agnostic masks produced directly from the point cloud by a pretrained 3D segmenter, eliminating the need for SAM and CLIP and significantly reducing inference time. However, Open-YOLO 3D often fails to generalize to object categories that appear infrequently in the 3D training data. In this paper, we propose a method that generates 3D instance masks for novel objects from RGB images guided by a 2D open-vocabulary detector. Our approach inherits the 2D detector's ability to recognize novel objects while maintaining efficient classification, enabling fast and accurate retrieval of rare instances from open-ended text queries. Our code will be made available at https://github.com/ndkhanh360/BoxOVIS.
NVIDIA Nemotron Nano V2 VL
Nov 07, 2025We introduce Nemotron Nano V2 VL, the latest model of the Nemotron vision-language series designed for strong real-world document understanding, long video comprehension, and reasoning tasks. Nemotron Nano V2 VL delivers significant improvements over our previous model, Llama-3.1-Nemotron-Nano-VL-8B, across all vision and text domains through major enhancements in model architecture, datasets, and training recipes. Nemotron Nano V2 VL builds on Nemotron Nano V2, a hybrid Mamba-Transformer LLM, and innovative token reduction techniques to achieve higher inference throughput in long document and video scenarios. We are releasing model checkpoints in BF16, FP8, and FP4 formats and sharing large parts of our datasets, recipes and training code.
DocMIA: Document-Level Membership Inference Attacks against DocVQA Models
Feb 06, 2025



Document Visual Question Answering (DocVQA) has introduced a new paradigm for end-to-end document understanding, and quickly became one of the standard benchmarks for multimodal LLMs. Automating document processing workflows, driven by DocVQA models, presents significant potential for many business sectors. However, documents tend to contain highly sensitive information, raising concerns about privacy risks associated with training such DocVQA models. One significant privacy vulnerability, exploited by the membership inference attack, is the possibility for an adversary to determine if a particular record was part of the model's training data. In this paper, we introduce two novel membership inference attacks tailored specifically to DocVQA models. These attacks are designed for two different adversarial scenarios: a white-box setting, where the attacker has full access to the model architecture and parameters, and a black-box setting, where only the model's outputs are available. Notably, our attacks assume the adversary lacks access to auxiliary datasets, which is more realistic in practice but also more challenging. Our unsupervised methods outperform existing state-of-the-art membership inference attacks across a variety of DocVQA models and datasets, demonstrating their effectiveness and highlighting the privacy risks in this domain.
NeurIPS 2023 Competition: Privacy Preserving Federated Learning Document VQA
Nov 06, 2024



The Privacy Preserving Federated Learning Document VQA (PFL-DocVQA) competition challenged the community to develop provably private and communication-efficient solutions in a federated setting for a real-life use case: invoice processing. The competition introduced a dataset of real invoice documents, along with associated questions and answers requiring information extraction and reasoning over the document images. Thereby, it brings together researchers and expertise from the document analysis, privacy, and federated learning communities. Participants fine-tuned a pre-trained, state-of-the-art Document Visual Question Answering model provided by the organizers for this new domain, mimicking a typical federated invoice processing setup. The base model is a multi-modal generative language model, and sensitive information could be exposed through either the visual or textual input modality. Participants proposed elegant solutions to reduce communication costs while maintaining a minimum utility threshold in track 1 and to protect all information from each document provider using differential privacy in track 2. The competition served as a new testbed for developing and testing private federated learning methods, simultaneously raising awareness about privacy within the document image analysis and recognition community. Ultimately, the competition analysis provides best practices and recommendations for successfully running privacy-focused federated learning challenges in the future.
Improving Electrolyte Performance for Target Cathode Loading Using Interpretable Data-Driven Approach
Sep 03, 2024
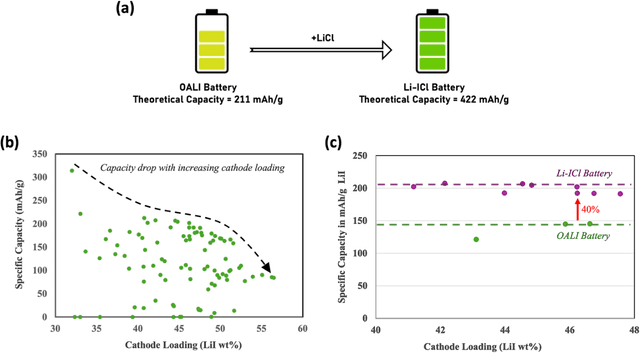
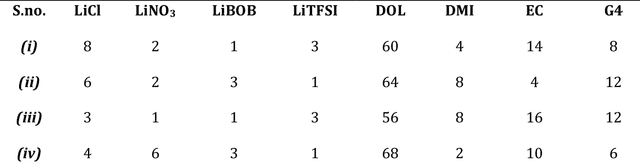

Higher loading of active electrode materials is desired in batteries, especially those based on conversion reactions, for enhanced energy density and cost efficiency. However, increasing active material loading in electrodes can cause significant performance depreciation due to internal resistance, shuttling, and parasitic side reactions, which can be alleviated to a certain extent by a compatible design of electrolytes. In this work, a data-driven approach is leveraged to find a high-performing electrolyte formulation for a novel interhalogen battery custom to the target cathode loading. An electrolyte design consisting of 4 solvents and 4 salts is experimentally devised for a novel interhalogen battery based on a multi-electron redox reaction. The experimental dataset with variable electrolyte compositions and active cathode loading, is used to train a graph-based deep learning model mapping changing variables in the battery's material design to its specific capacity. The trained model is used to further optimize the electrolyte formulation compositions for enhancing the battery capacity at a target cathode loading by a two-fold approach: large-scale screening and interpreting electrolyte design principles for different cathode loadings. The data-driven approach is demonstrated to bring about an additional 20% increment in the specific capacity of the battery over capacities obtained from the experimental optimization.
Active Sensing of Knee Osteoarthritis Progression with Reinforcement Learning
Aug 05, 2024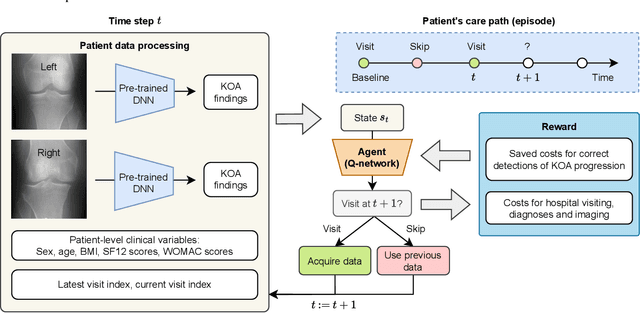
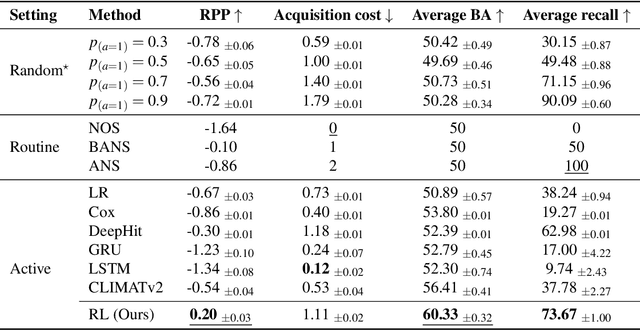
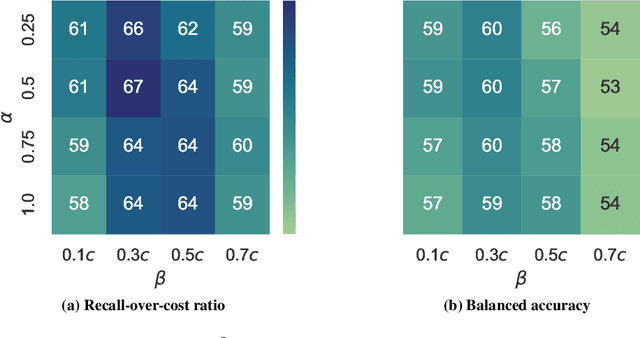
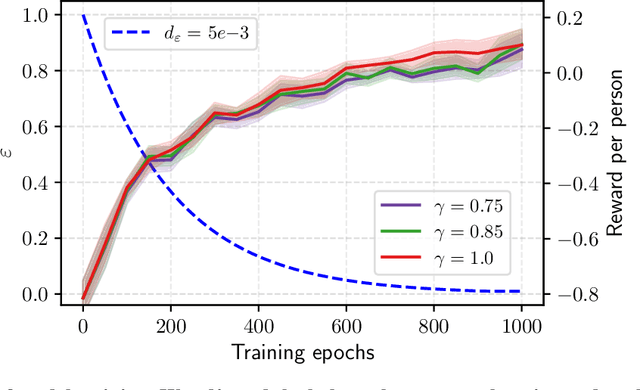
Osteoarthritis (OA) is the most common musculoskeletal disease, which has no cure. Knee OA (KOA) is one of the highest causes of disability worldwide, and it costs billions of United States dollars to the global community. Prediction of KOA progression has been of high interest to the community for years, as it can advance treatment development through more efficient clinical trials and improve patient outcomes through more efficient healthcare utilization. Existing approaches for predicting KOA, however, are predominantly static, i.e. consider data from a single time point to predict progression many years into the future, and knee level, i.e. consider progression in a single joint only. Due to these and related reasons, these methods fail to deliver the level of predictive performance, which is sufficient to result in cost savings and better patient outcomes. Collecting extensive data from all patients on a regular basis could address the issue, but it is limited by the high cost at a population level. In this work, we propose to go beyond static prediction models in OA, and bring a novel Active Sensing (AS) approach, designed to dynamically follow up patients with the objective of maximizing the number of informative data acquisitions, while minimizing their total cost over a period of time. Our approach is based on Reinforcement Learning (RL), and it leverages a novel reward function designed specifically for AS of disease progression in more than one part of a human body. Our method is end-to-end, relies on multi-modal Deep Learning, and requires no human input at inference time. Throughout an exhaustive experimental evaluation, we show that using RL can provide a higher monetary benefit when compared to state-of-the-art baselines.