 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLandmark-free Assessment of Lower-limb Alignment with Implicit Neural Shape Functions from Knee Radiographs
Jun 13, 2026Radiographic assessment of lower-limb alignment (LLA) is important for predicting joint health and surgical outcomes in total knee arthroplasty. Traditional measurement methods are manual and time-consuming, while recent machine learning approaches typically rely on locating a fixed set of anatomical landmarks. This dependence limits flexibility and may require re-annotation when clinical definitions change. To address this, we propose an automated workflow using Implicit Neural Shape Functions (INSF). Rather than relying on explicit landmark coordinates, we encode the anatomy into a compact latent space and regress clinical alignment measurements directly from these latent codes. This architecture allows for rapid extendability to new tasks without altering the backbone representation. We trained our method on an internal dataset of 566 knee radiographs, each annotated with the outline of the femur and tibia. We evaluated it on both an internal test dataset of 50 patients and a separate external set of 402 preoperative cases from the MRKR dataset. Manual clinical measurements are available for these data, and the MRKR measurements will be made publicly accessible. Performance was comparable to state-of-the-art landmark-based methods and manual agreement, while offering a flexible shape representation that can be extended to additional measurement tasks.
EchoPrune: Interpreting Redundancy as Temporal Echoes for Efficient VideoLLMs
May 11, 2026Long-form video understanding remains challenging for Video Large Language Models (VideoLLMs), as the dense frame sampling introduces massive visual tokens while sparse sampling risks missing critical temporal evidence and leading to LLM hallucination. Existing training-free token reduction methods either treat videos equally as static images or rely on segment-level merging heuristics, which weaken fine-grained spatiotemporal modeling and introduce additional overhead. In this paper, we propose EchoPrune, a lightweight and training-free token pruning method that improves temporal resolution under a fixed LLM-side visual token budget. Our core idea is to interpret redundant video tokens as temporal echoes: if a token is well reconstructed from the previous frame, it is merely a temporally redundant echo; otherwise, it may capture new events, motion, or query-relevant visual evidence. Based on this insight, EchoPrune scores visual tokens by (i) query-guided crossmodal relevance and (ii) temporal reconstruction error, measured by correspondence matching and echo matching across consecutive frames. The selected tokens preserve task-relevant cues and temporal novelty while suppressing predictable redundancy, allowing VideoLLMs to observe more frames without increasing the decoding budget. Extensive experiments on LLaVA-OV, Qwen2.5VL, and Qwen3VL across six video understanding benchmarks show that EchoPrune enables VideoLLMs to process up to 20x frames under the same token budget, yielding improved performance (+8.6%) and inference speedup (5.6x for prefilling) on Qwen2.5VL-7B.
MI-Pruner: Crossmodal Mutual Information-guided Token Pruner for Efficient MLLMs
Apr 03, 2026For multimodal large language models (MLLMs), visual information is relatively sparse compared with text. As a result, research on visual pruning emerges for efficient inference. Current approaches typically measure token importance based on the attention scores in the visual encoder or in the LLM decoder, then select visual tokens with high attention scores while pruning others. In this paper, we pursue a different and more surgical approach. Instead of relying on mechanism-specific signals, we directly compute Mutual Information (MI) between visual and textual features themselves, prior to their interaction. This allows us to explicitly measure crossmodal dependency at the feature levels. Our MI-Pruner is simple, efficient and non-intrusive, requiring no access to internal attention maps or architectural modifications. Experimental results demonstrate that our approach outperforms previous attention-based pruning methods with minimal latency.
LoG-VMamba: Local-Global Vision Mamba for Medical Image Segmentation
Aug 26, 2024



Mamba, a State Space Model (SSM), has recently shown competitive performance to Convolutional Neural Networks (CNNs) and Transformers in Natural Language Processing and general sequence modeling. Various attempts have been made to adapt Mamba to Computer Vision tasks, including medical image segmentation (MIS). Vision Mamba (VM)-based networks are particularly attractive due to their ability to achieve global receptive fields, similar to Vision Transformers, while also maintaining linear complexity in the number of tokens. However, the existing VM models still struggle to maintain both spatially local and global dependencies of tokens in high dimensional arrays due to their sequential nature. Employing multiple and/or complicated scanning strategies is computationally costly, which hinders applications of SSMs to high-dimensional 2D and 3D images that are common in MIS problems. In this work, we propose Local-Global Vision Mamba, LoG-VMamba, that explicitly enforces spatially adjacent tokens to remain nearby on the channel axis, and retains the global context in a compressed form. Our method allows the SSMs to access the local and global contexts even before reaching the last token while requiring only a simple scanning strategy. Our segmentation models are computationally efficient and substantially outperform both CNN and Transformers-based baselines on a diverse set of 2D and 3D MIS tasks. The implementation of LoG-VMamba is available at \url{https://github.com/Oulu-IMEDS/LoG-VMamba}.
Active Sensing of Knee Osteoarthritis Progression with Reinforcement Learning
Aug 05, 2024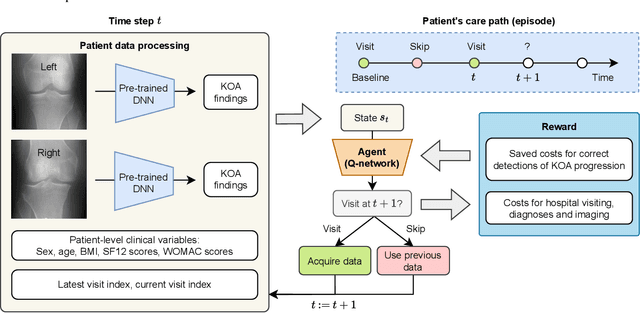
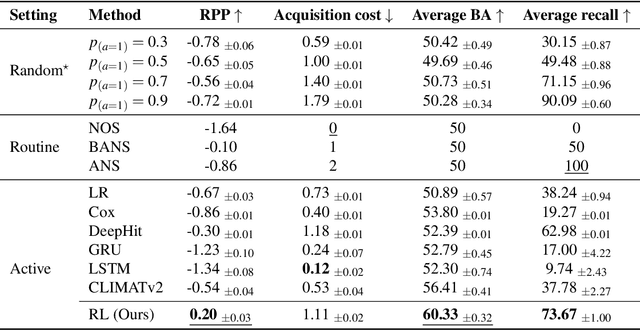
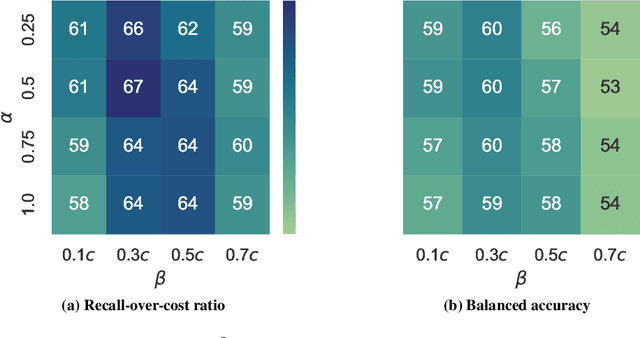
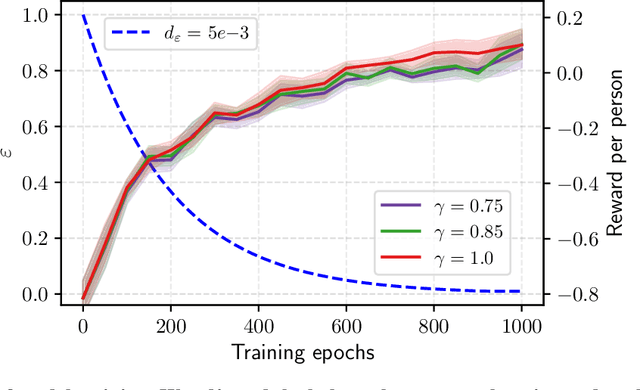
Osteoarthritis (OA) is the most common musculoskeletal disease, which has no cure. Knee OA (KOA) is one of the highest causes of disability worldwide, and it costs billions of United States dollars to the global community. Prediction of KOA progression has been of high interest to the community for years, as it can advance treatment development through more efficient clinical trials and improve patient outcomes through more efficient healthcare utilization. Existing approaches for predicting KOA, however, are predominantly static, i.e. consider data from a single time point to predict progression many years into the future, and knee level, i.e. consider progression in a single joint only. Due to these and related reasons, these methods fail to deliver the level of predictive performance, which is sufficient to result in cost savings and better patient outcomes. Collecting extensive data from all patients on a regular basis could address the issue, but it is limited by the high cost at a population level. In this work, we propose to go beyond static prediction models in OA, and bring a novel Active Sensing (AS) approach, designed to dynamically follow up patients with the objective of maximizing the number of informative data acquisitions, while minimizing their total cost over a period of time. Our approach is based on Reinforcement Learning (RL), and it leverages a novel reward function designed specifically for AS of disease progression in more than one part of a human body. Our method is end-to-end, relies on multi-modal Deep Learning, and requires no human input at inference time. Throughout an exhaustive experimental evaluation, we show that using RL can provide a higher monetary benefit when compared to state-of-the-art baselines.
SiNGR: Brain Tumor Segmentation via Signed Normalized Geodesic Transform Regression
May 27, 2024



One of the primary challenges in brain tumor segmentation arises from the uncertainty of voxels close to tumor boundaries. However, the conventional process of generating ground truth segmentation masks fails to treat such uncertainties properly. Those ``hard labels'' with 0s and 1s conceptually influenced the majority of prior studies on brain image segmentation. As a result, tumor segmentation is often solved through voxel classification. In this work, we instead view this problem as a voxel-level regression, where the ground truth represents a certainty mapping from any pixel based on the distance to tumor border. We propose a novel ground truth label transformation, which is based on a signed geodesic transform, to capture the uncertainty in brain tumors' vicinity, while maintaining a margin between positive and negative samples. We combine this idea with a Focal-like regression L1-loss that enables effective regression learning in high-dimensional output space by appropriately weighting voxels according to their difficulty. We thoroughly conduct an experimental evaluation to validate the components of our proposed method, compare it to a diverse array of state-of-the-art segmentation models, and show that it is architecture-agnostic. The code of our method is made publicly available (\url{https://github.com/Oulu-IMEDS/SiNGR/}).
Image-level Regression for Uncertainty-aware Retinal Image Segmentation
May 27, 2024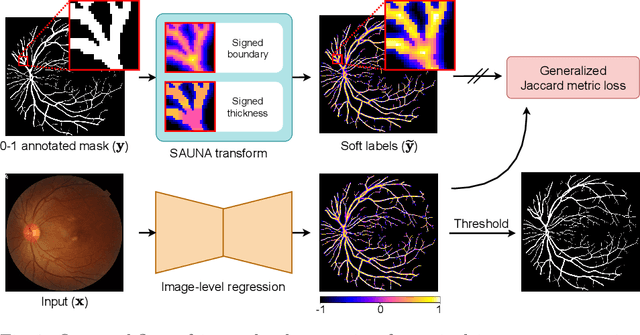
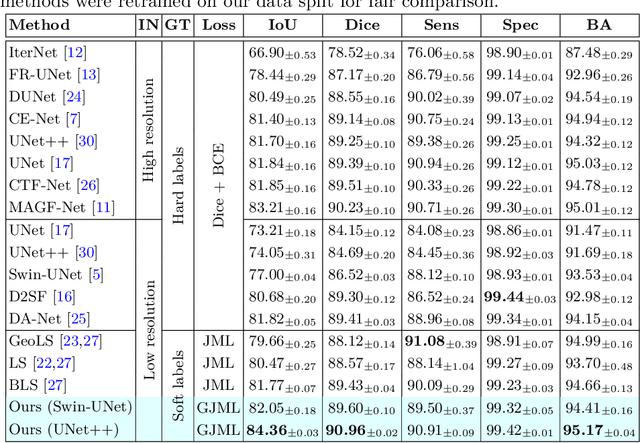
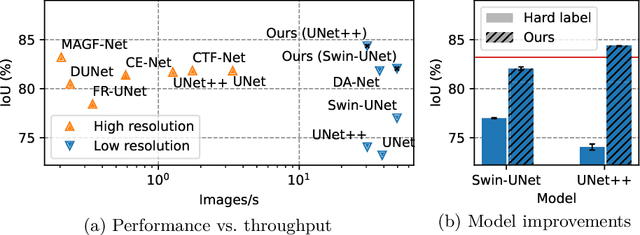
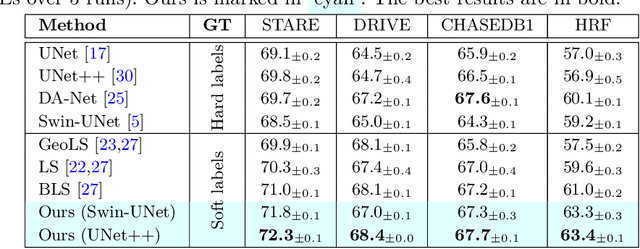
Accurate retinal vessel segmentation is a crucial step in the quantitative assessment of retinal vasculature, which is needed for the early detection of retinal diseases and other conditions. Numerous studies have been conducted to tackle the problem of segmenting vessels automatically using a pixel-wise classification approach. The common practice of creating ground truth labels is to categorize pixels as foreground and background. This approach is, however, biased, and it ignores the uncertainty of a human annotator when it comes to annotating e.g. thin vessels. In this work, we propose a simple and effective method that casts the retinal image segmentation task as an image-level regression. For this purpose, we first introduce a novel Segmentation Annotation Uncertainty-Aware (SAUNA) transform, which adds pixel uncertainty to the ground truth using the pixel's closeness to the annotation boundary and vessel thickness. To train our model with soft labels, we generalize the earlier proposed Jaccard metric loss to arbitrary hypercubes, which is a second contribution of this work. The proposed SAUNA transform and the new theoretical results allow us to directly train a standard U-Net-like architecture at the image level, outperforming all recently published methods. We conduct thorough experiments and compare our method to a diverse set of baselines across 5 retinal image datasets. Our implementation is available at \url{https://github.com/Oulu-IMEDS/SAUNA}.
Consistent and Asymptotically Unbiased Estimation of Proper Calibration Errors
Dec 14, 2023



Proper scoring rules evaluate the quality of probabilistic predictions, playing an essential role in the pursuit of accurate and well-calibrated models. Every proper score decomposes into two fundamental components -- proper calibration error and refinement -- utilizing a Bregman divergence. While uncertainty calibration has gained significant attention, current literature lacks a general estimator for these quantities with known statistical properties. To address this gap, we propose a method that allows consistent, and asymptotically unbiased estimation of all proper calibration errors and refinement terms. In particular, we introduce Kullback--Leibler calibration error, induced by the commonly used cross-entropy loss. As part of our results, we prove the relation between refinement and f-divergences, which implies information monotonicity in neural networks, regardless of which proper scoring rule is optimized. Our experiments validate empirically the claimed properties of the proposed estimator and suggest that the selection of a post-hoc calibration method should be determined by the particular calibration error of interest.
Beyond Classification: Definition and Density-based Estimation of Calibration in Object Detection
Dec 11, 2023



Despite their impressive predictive performance in various computer vision tasks, deep neural networks (DNNs) tend to make overly confident predictions, which hinders their widespread use in safety-critical applications. While there have been recent attempts to calibrate DNNs, most of these efforts have primarily been focused on classification tasks, thus neglecting DNN-based object detectors. Although several recent works addressed calibration for object detection and proposed differentiable penalties, none of them are consistent estimators of established concepts in calibration. In this work, we tackle the challenge of defining and estimating calibration error specifically for this task. In particular, we adapt the definition of classification calibration error to handle the nuances associated with object detection, and predictions in structured output spaces more generally. Furthermore, we propose a consistent and differentiable estimator of the detection calibration error, utilizing kernel density estimation. Our experiments demonstrate the effectiveness of our estimator against competing train-time and post-hoc calibration methods, while maintaining similar detection performance.
End-To-End Prediction of Knee Osteoarthritis Progression With Multi-Modal Transformers
Jul 03, 2023



Knee Osteoarthritis (KOA) is a highly prevalent chronic musculoskeletal condition with no currently available treatment. The manifestation of KOA is heterogeneous and prediction of its progression is challenging. Current literature suggests that the use of multi-modal data and advanced modeling methods, such as the ones based on Deep Learning, has promise in tackling this challenge. To date, however, the evidence on the efficacy of this approach is limited. In this study, we leveraged recent advances in Deep Learning and, using a Transformer approach, developed a unified framework for the multi-modal fusion of knee imaging data. Subsequently, we analyzed its performance across a range of scenarios by investigating multiple progression horizons -- from short-term to long-term. We report our findings using a large cohort (n=2421-3967) derived from the Osteoarthritis Initiative dataset. We show that structural knee MRI allows identifying radiographic KOA progressors on par with multi-modal fusion approaches, achieving an area under the ROC curve (ROC AUC) of 0.70-0.76 and Average Precision (AP) of 0.15-0.54 in 2-8 year horizons. Progression within 1 year was better predicted with a multi-modal method using X-ray, structural, and compositional MR images -- ROC AUC of 0.76(0.04), AP of 0.13(0.04) -- or via clinical data. Our follow-up analysis generally shows that prediction from the imaging data is more accurate for post-traumatic subjects, and we further investigate which subject subgroups may benefit the most. The present study provides novel insights into multi-modal imaging of KOA and brings a unified data-driven framework for studying its progression in an end-to-end manner, providing new tools for the design of more efficient clinical trials. The source code of our framework and the pre-trained models are made publicly available.