 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained Uncertainty Decomposition in Large Language Models: A Spectral Approach
Sep 26, 2025As Large Language Models (LLMs) are increasingly integrated in diverse applications, obtaining reliable measures of their predictive uncertainty has become critically important. A precise distinction between aleatoric uncertainty, arising from inherent ambiguities within input data, and epistemic uncertainty, originating exclusively from model limitations, is essential to effectively address each uncertainty source. In this paper, we introduce Spectral Uncertainty, a novel approach to quantifying and decomposing uncertainties in LLMs. Leveraging the Von Neumann entropy from quantum information theory, Spectral Uncertainty provides a rigorous theoretical foundation for separating total uncertainty into distinct aleatoric and epistemic components. Unlike existing baseline methods, our approach incorporates a fine-grained representation of semantic similarity, enabling nuanced differentiation among various semantic interpretations in model responses. Empirical evaluations demonstrate that Spectral Uncertainty outperforms state-of-the-art methods in estimating both aleatoric and total uncertainty across diverse models and benchmark datasets.
A Novel Framework for Uncertainty Quantification via Proper Scores for Classification and Beyond
Aug 25, 2025In this PhD thesis, we propose a novel framework for uncertainty quantification in machine learning, which is based on proper scores. Uncertainty quantification is an important cornerstone for trustworthy and reliable machine learning applications in practice. Usually, approaches to uncertainty quantification are problem-specific, and solutions and insights cannot be readily transferred from one task to another. Proper scores are loss functions minimized by predicting the target distribution. Due to their very general definition, proper scores apply to regression, classification, or even generative modeling tasks. We contribute several theoretical results, that connect epistemic uncertainty, aleatoric uncertainty, and model calibration with proper scores, resulting in a general and widely applicable framework. We achieve this by introducing a general bias-variance decomposition for strictly proper scores via functional Bregman divergences. Specifically, we use the kernel score, a kernel-based proper score, for evaluating sample-based generative models in various domains, like image, audio, and natural language generation. This includes a novel approach for uncertainty estimation of large language models, which outperforms state-of-the-art baselines. Further, we generalize the calibration-sharpness decomposition beyond classification, which motivates the definition of proper calibration errors. We then introduce a novel estimator for proper calibration errors in classification, and a novel risk-based approach to compare different estimators for squared calibration errors. Last, we offer a decomposition of the kernel spherical score, another kernel-based proper score, allowing a more fine-grained and interpretable evaluation of generative image models.
Revisiting Reweighted Risk for Calibration: AURC, Focal Loss, and Inverse Focal Loss
May 29, 2025Several variants of reweighted risk functionals, such as focal losss, inverse focal loss, and the Area Under the Risk-Coverage Curve (AURC), have been proposed in the literature and claims have been made in relation to their calibration properties. However, focal loss and inverse focal loss propose vastly different weighting schemes. In this paper, we revisit a broad class of weighted risk functions commonly used in deep learning and establish a principled connection between these reweighting schemes and calibration errors. We show that minimizing calibration error is closely linked to the selective classification paradigm and demonstrate that optimizing a regularized variant of the AURC naturally leads to improved calibration. This regularized AURC shares a similar reweighting strategy with inverse focal loss, lending support to the idea that focal loss is less principled when calibration is a desired outcome. Direct AURC optimization offers greater flexibility through the choice of confidence score functions (CSFs). To enable gradient-based optimization, we introduce a differentiable formulation of the regularized AURC using the SoftRank technique. Empirical evaluations demonstrate that our AURC-based loss achieves competitive class-wise calibration performance across a range of datasets and model architectures.
Beyond Segmentation: Confidence-Aware and Debiased Estimation of Ratio-based Biomarkers
May 26, 2025Ratio-based biomarkers -- such as the proportion of necrotic tissue within a tumor -- are widely used in clinical practice to support diagnosis, prognosis and treatment planning. These biomarkers are typically estimated from soft segmentation outputs by computing region-wise ratios. Despite the high-stakes nature of clinical decision making, existing methods provide only point estimates, offering no measure of uncertainty. In this work, we propose a unified \textit{confidence-aware} framework for estimating ratio-based biomarkers. We conduct a systematic analysis of error propagation in the segmentation-to-biomarker pipeline and identify model miscalibration as the dominant source of uncertainty. To mitigate this, we incorporate a lightweight, post-hoc calibration module that can be applied using internal hospital data without retraining. We leverage a tunable parameter $Q$ to control the confidence level of the derived bounds, allowing adaptation towards clinical practice. Extensive experiments show that our method produces statistically sound confidence intervals, with tunable confidence levels, enabling more trustworthy application of predictive biomarkers in clinical workflows.
Optimizing Estimators of Squared Calibration Errors in Classification
Oct 09, 2024In this work, we propose a mean-squared error-based risk that enables the comparison and optimization of estimators of squared calibration errors in practical settings. Improving the calibration of classifiers is crucial for enhancing the trustworthiness and interpretability of machine learning models, especially in sensitive decision-making scenarios. Although various calibration (error) estimators exist in the current literature, there is a lack of guidance on selecting the appropriate estimator and tuning its hyperparameters. By leveraging the bilinear structure of squared calibration errors, we reformulate calibration estimation as a regression problem with independent and identically distributed (i.i.d.) input pairs. This reformulation allows us to quantify the performance of different estimators even for the most challenging calibration criterion, known as canonical calibration. Our approach advocates for a training-validation-testing pipeline when estimating a calibration error on an evaluation dataset. We demonstrate the effectiveness of our pipeline by optimizing existing calibration estimators and comparing them with novel kernel ridge regression-based estimators on standard image classification tasks.
Disentangling Mean Embeddings for Better Diagnostics of Image Generators
Sep 02, 2024

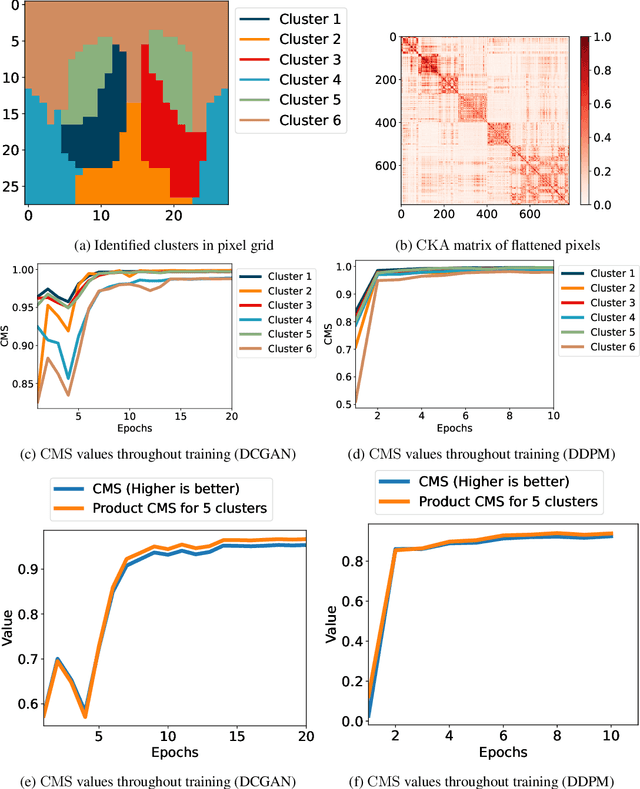

The evaluation of image generators remains a challenge due to the limitations of traditional metrics in providing nuanced insights into specific image regions. This is a critical problem as not all regions of an image may be learned with similar ease. In this work, we propose a novel approach to disentangle the cosine similarity of mean embeddings into the product of cosine similarities for individual pixel clusters via central kernel alignment. Consequently, we can quantify the contribution of the cluster-wise performance to the overall image generation performance. We demonstrate how this enhances the explainability and the likelihood of identifying pixel regions of model misbehavior across various real-world use cases.
Consistent and Asymptotically Unbiased Estimation of Proper Calibration Errors
Dec 14, 2023



Proper scoring rules evaluate the quality of probabilistic predictions, playing an essential role in the pursuit of accurate and well-calibrated models. Every proper score decomposes into two fundamental components -- proper calibration error and refinement -- utilizing a Bregman divergence. While uncertainty calibration has gained significant attention, current literature lacks a general estimator for these quantities with known statistical properties. To address this gap, we propose a method that allows consistent, and asymptotically unbiased estimation of all proper calibration errors and refinement terms. In particular, we introduce Kullback--Leibler calibration error, induced by the commonly used cross-entropy loss. As part of our results, we prove the relation between refinement and f-divergences, which implies information monotonicity in neural networks, regardless of which proper scoring rule is optimized. Our experiments validate empirically the claimed properties of the proposed estimator and suggest that the selection of a post-hoc calibration method should be determined by the particular calibration error of interest.
A Bias-Variance-Covariance Decomposition of Kernel Scores for Generative Models
Oct 09, 2023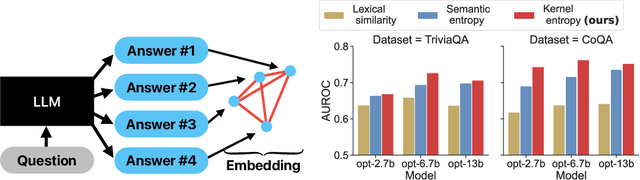



Generative models, like large language models, are becoming increasingly relevant in our daily lives, yet a theoretical framework to assess their generalization behavior and uncertainty does not exist. Particularly, the problem of uncertainty estimation is commonly solved in an ad-hoc manner and task dependent. For example, natural language approaches cannot be transferred to image generation. In this paper we introduce the first bias-variance-covariance decomposition for kernel scores and their associated entropy. We propose unbiased and consistent estimators for each quantity which only require generated samples but not the underlying model itself. As an application, we offer a generalization evaluation of diffusion models and discover how mode collapse of minority groups is a contrary phenomenon to overfitting. Further, we demonstrate that variance and predictive kernel entropy are viable measures of uncertainty for image, audio, and language generation. Specifically, our approach for uncertainty estimation is more predictive of performance on CoQA and TriviaQA question answering datasets than existing baselines and can also be applied to closed-source models.