 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Dimensional Analysis of Gradient Flow for Extensive-Width Quadratic Neural Networks
Jan 15, 2026We study the high-dimensional training dynamics of a shallow neural network with quadratic activation in a teacher-student setup. We focus on the extensive-width regime, where the teacher and student network widths scale proportionally with the input dimension, and the sample size grows quadratically. This scaling aims to describe overparameterized neural networks in which feature learning still plays a central role. In the high-dimensional limit, we derive a dynamical characterization of the gradient flow, in the spirit of dynamical mean-field theory (DMFT). Under l2-regularization, we analyze these equations at long times and characterize the performance and spectral properties of the resulting estimator. This result provides a quantitative understanding of the effect of overparameterization on learning and generalization, and reveals a double descent phenomenon in the presence of label noise, where generalization improves beyond interpolation. In the small regularization limit, we obtain an exact expression for the perfect recovery threshold as a function of the network widths, providing a precise characterization of how overparameterization influences recovery.
A Convex Loss Function for Set Prediction with Optimal Trade-offs Between Size and Conditional Coverage
Dec 22, 2025



We consider supervised learning problems in which set predictions provide explicit uncertainty estimates. Using Choquet integrals (a.k.a. Lov{á}sz extensions), we propose a convex loss function for nondecreasing subset-valued functions obtained as level sets of a real-valued function. This loss function allows optimal trade-offs between conditional probabilistic coverage and the ''size'' of the set, measured by a non-decreasing submodular function. We also propose several extensions that mimic loss functions and criteria for binary classification with asymmetric losses, and show how to naturally obtain sets with optimized conditional coverage. We derive efficient optimization algorithms, either based on stochastic gradient descent or reweighted least-squares formulations, and illustrate our findings with a series of experiments on synthetic datasets for classification and regression tasks, showing improvements over approaches that aim for marginal coverage.
Conditional Coverage Diagnostics for Conformal Prediction
Dec 12, 2025Evaluating conditional coverage remains one of the most persistent challenges in assessing the reliability of predictive systems. Although conformal methods can give guarantees on marginal coverage, no method can guarantee to produce sets with correct conditional coverage, leaving practitioners without a clear way to interpret local deviations. To overcome sample-inefficiency and overfitting issues of existing metrics, we cast conditional coverage estimation as a classification problem. Conditional coverage is violated if and only if any classifier can achieve lower risk than the target coverage. Through the choice of a (proper) loss function, the resulting risk difference gives a conservative estimate of natural miscoverage measures such as L1 and L2 distance, and can even separate the effects of over- and under-coverage, and non-constant target coverages. We call the resulting family of metrics excess risk of the target coverage (ERT). We show experimentally that the use of modern classifiers provides much higher statistical power than simple classifiers underlying established metrics like CovGap. Additionally, we use our metric to benchmark different conformal prediction methods. Finally, we release an open-source package for ERT as well as previous conditional coverage metrics. Together, these contributions provide a new lens for understanding, diagnosing, and improving the conditional reliability of predictive systems.
Structured Matrix Scaling for Multi-Class Calibration
Nov 05, 2025Post-hoc recalibration methods are widely used to ensure that classifiers provide faithful probability estimates. We argue that parametric recalibration functions based on logistic regression can be motivated from a simple theoretical setting for both binary and multiclass classification. This insight motivates the use of more expressive calibration methods beyond standard temperature scaling. For multi-class calibration however, a key challenge lies in the increasing number of parameters introduced by more complex models, often coupled with limited calibration data, which can lead to overfitting. Through extensive experiments, we demonstrate that the resulting bias-variance tradeoff can be effectively managed by structured regularization, robust preprocessing and efficient optimization. The resulting methods lead to substantial gains over existing logistic-based calibration techniques. We provide efficient and easy-to-use open-source implementations of our methods, making them an attractive alternative to common temperature, vector, and matrix scaling implementations.
Adaptive Coverage Policies in Conformal Prediction
Oct 05, 2025



Traditional conformal prediction methods construct prediction sets such that the true label falls within the set with a user-specified coverage level. However, poorly chosen coverage levels can result in uninformative predictions, either producing overly conservative sets when the coverage level is too high, or empty sets when it is too low. Moreover, the fixed coverage level cannot adapt to the specific characteristics of each individual example, limiting the flexibility and efficiency of these methods. In this work, we leverage recent advances in e-values and post-hoc conformal inference, which allow the use of data-dependent coverage levels while maintaining valid statistical guarantees. We propose to optimize an adaptive coverage policy by training a neural network using a leave-one-out procedure on the calibration set, allowing the coverage level and the resulting prediction set size to vary with the difficulty of each individual example. We support our approach with theoretical coverage guarantees and demonstrate its practical benefits through a series of experiments.
Multivariate Conformal Prediction via Conformalized Gaussian Scoring
Jul 28, 2025
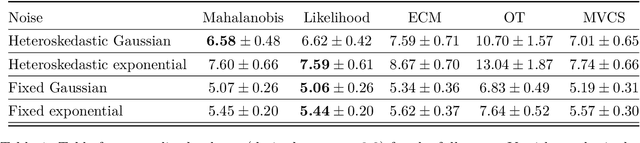


While achieving exact conditional coverage in conformal prediction is unattainable without making strong, untestable regularity assumptions, the promise of conformal prediction hinges on finding approximations to conditional guarantees that are realizable in practice. A promising direction for obtaining conditional dependence for conformal sets--in particular capturing heteroskedasticity--is through estimating the conditional density $\mathbb{P}_{Y|X}$ and conformalizing its level sets. Previous work in this vein has focused on nonconformity scores based on the empirical cumulative distribution function (CDF). Such scores are, however, computationally costly, typically requiring expensive sampling methods. To avoid the need for sampling, we observe that the CDF-based score reduces to a Mahalanobis distance in the case of Gaussian scores, yielding a closed-form expression that can be directly conformalized. Moreover, the use of a Gaussian-based score opens the door to a number of extensions of the basic conformal method; in particular, we show how to construct conformal sets with missing output values, refine conformal sets as partial information about $Y$ becomes available, and construct conformal sets on transformations of the output space. Finally, empirical results indicate that our approach produces conformal sets that more closely approximate conditional coverage in multivariate settings compared to alternative methods.
Scaling Laws for Gradient Descent and Sign Descent for Linear Bigram Models under Zipf's Law
May 25, 2025Recent works have highlighted optimization difficulties faced by gradient descent in training the first and last layers of transformer-based language models, which are overcome by optimizers such as Adam. These works suggest that the difficulty is linked to the heavy-tailed distribution of words in text data, where the frequency of the $k$th most frequent word $\pi_k$ is proportional to $1/k$, following Zipf's law. To better understand the impact of the data distribution on training performance, we study a linear bigram model for next-token prediction when the tokens follow a power law $\pi_k \propto 1/k^\alpha$ parameterized by the exponent $\alpha > 0$. We derive optimization scaling laws for deterministic gradient descent and sign descent as a proxy for Adam as a function of the exponent $\alpha$. Existing theoretical investigations in scaling laws assume that the eigenvalues of the data decay as a power law with exponent $\alpha > 1$. This assumption effectively makes the problem ``finite dimensional'' as most of the loss comes from a few of the largest eigencomponents. In comparison, we show that the problem is more difficult when the data have heavier tails. The case $\alpha = 1$ as found in text data is ``worst-case'' for gradient descent, in that the number of iterations required to reach a small relative error scales almost linearly with dimension. While the performance of sign descent also depends on the dimension, for Zipf-distributed data the number of iterations scales only with the square-root of the dimension, leading to a large improvement for large vocabularies.
Backward Conformal Prediction
May 19, 2025



We introduce $\textit{Backward Conformal Prediction}$, a method that guarantees conformal coverage while providing flexible control over the size of prediction sets. Unlike standard conformal prediction, which fixes the coverage level and allows the conformal set size to vary, our approach defines a rule that constrains how prediction set sizes behave based on the observed data, and adapts the coverage level accordingly. Our method builds on two key foundations: (i) recent results by Gauthier et al. [2025] on post-hoc validity using e-values, which ensure marginal coverage of the form $\mathbb{P}(Y_{\rm test} \in \hat C_n^{\tilde{\alpha}}(X_{\rm test})) \ge 1 - \mathbb{E}[\tilde{\alpha}]$ up to a first-order Taylor approximation for any data-dependent miscoverage $\tilde{\alpha}$, and (ii) a novel leave-one-out estimator $\hat{\alpha}^{\rm LOO}$ of the marginal miscoverage $\mathbb{E}[\tilde{\alpha}]$ based on the calibration set, ensuring that the theoretical guarantees remain computable in practice. This approach is particularly useful in applications where large prediction sets are impractical such as medical diagnosis. We provide theoretical results and empirical evidence supporting the validity of our method, demonstrating that it maintains computable coverage guarantees while ensuring interpretable, well-controlled prediction set sizes.
StablePCA: Learning Shared Representations across Multiple Sources via Minimax Optimization
May 02, 2025When synthesizing multisource high-dimensional data, a key objective is to extract low-dimensional feature representations that effectively approximate the original features across different sources. Such general feature extraction facilitates the discovery of transferable knowledge, mitigates systematic biases such as batch effects, and promotes fairness. In this paper, we propose Stable Principal Component Analysis (StablePCA), a novel method for group distributionally robust learning of latent representations from high-dimensional multi-source data. A primary challenge in generalizing PCA to the multi-source regime lies in the nonconvexity of the fixed rank constraint, rendering the minimax optimization nonconvex. To address this challenge, we employ the Fantope relaxation, reformulating the problem as a convex minimax optimization, with the objective defined as the maximum loss across sources. To solve the relaxed formulation, we devise an optimistic-gradient Mirror Prox algorithm with explicit closed-form updates. Theoretically, we establish the global convergence of the Mirror Prox algorithm, with the convergence rate provided from the optimization perspective. Furthermore, we offer practical criteria to assess how closely the solution approximates the original nonconvex formulation. Through extensive numerical experiments, we demonstrate StablePCA's high accuracy and efficiency in extracting robust low-dimensional representations across various finite-sample scenarios.
Minimum Volume Conformal Sets for Multivariate Regression
Mar 24, 2025Conformal prediction provides a principled framework for constructing predictive sets with finite-sample validity. While much of the focus has been on univariate response variables, existing multivariate methods either impose rigid geometric assumptions or rely on flexible but computationally expensive approaches that do not explicitly optimize prediction set volume. We propose an optimization-driven framework based on a novel loss function that directly learns minimum-volume covering sets while ensuring valid coverage. This formulation naturally induces a new nonconformity score for conformal prediction, which adapts to the residual distribution and covariates. Our approach optimizes over prediction sets defined by arbitrary norm balls, including single and multi-norm formulations. Additionally, by jointly optimizing both the predictive model and predictive uncertainty, we obtain prediction sets that are tight, informative, and computationally efficient, as demonstrated in our experiments on real-world datasets.