 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Bridges between Regression, Clustering, and Classification
Feb 05, 2025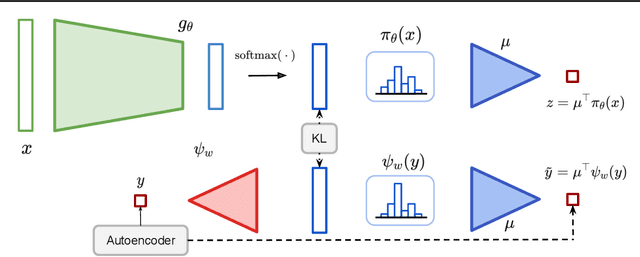
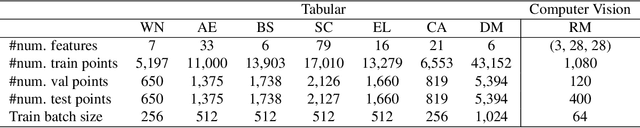
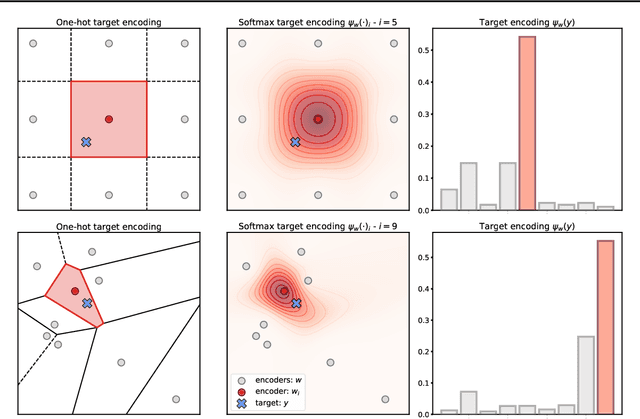
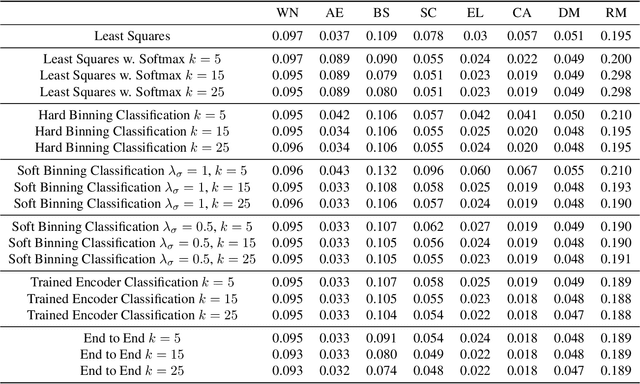
Regression, the task of predicting a continuous scalar target y based on some features x is one of the most fundamental tasks in machine learning and statistics. It has been observed and theoretically analyzed that the classical approach, meansquared error minimization, can lead to suboptimal results when training neural networks. In this work, we propose a new method to improve the training of these models on regression tasks, with continuous scalar targets. Our method is based on casting this task in a different fashion, using a target encoder, and a prediction decoder, inspired by approaches in classification and clustering. We showcase the performance of our method on a wide range of real-world datasets.
The N-Grammys: Accelerating Autoregressive Inference with Learning-Free Batched Speculation
Nov 06, 2024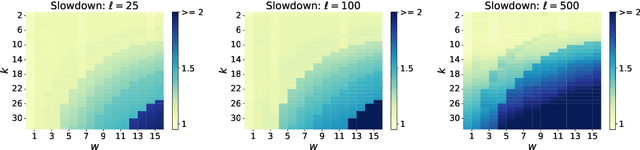
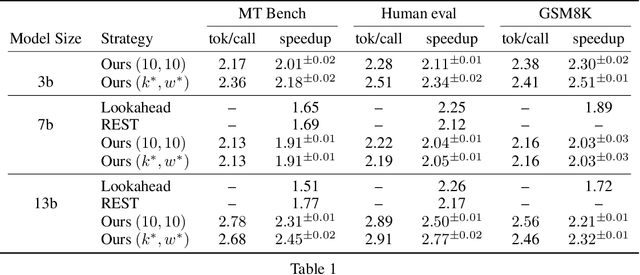
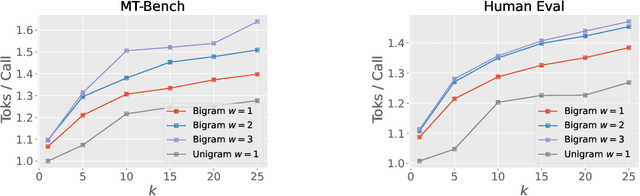
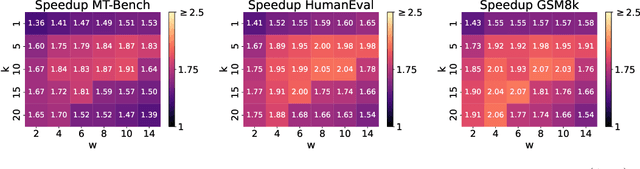
Speculative decoding aims to speed up autoregressive generation of a language model by verifying in parallel the tokens generated by a smaller draft model.In this work, we explore the effectiveness of learning-free, negligible-cost draft strategies, namely $N$-grams obtained from the model weights and the context. While the predicted next token of the base model is rarely the top prediction of these simple strategies, we observe that it is often within their top-$k$ predictions for small $k$. Based on this, we show that combinations of simple strategies can achieve significant inference speedups over different tasks. The overall performance is comparable to more complex methods, yet does not require expensive preprocessing or modification of the base model, and allows for seamless `plug-and-play' integration into pipelines.
Pixtral 12B
Oct 09, 2024



We introduce Pixtral-12B, a 12--billion-parameter multimodal language model. Pixtral-12B is trained to understand both natural images and documents, achieving leading performance on various multimodal benchmarks, surpassing a number of larger models. Unlike many open-source models, Pixtral is also a cutting-edge text model for its size, and does not compromise on natural language performance to excel in multimodal tasks. Pixtral uses a new vision encoder trained from scratch, which allows it to ingest images at their natural resolution and aspect ratio. This gives users flexibility on the number of tokens used to process an image. Pixtral is also able to process any number of images in its long context window of 128K tokens. Pixtral 12B substanially outperforms other open models of similar sizes (Llama-3.2 11B \& Qwen-2-VL 7B). It also outperforms much larger open models like Llama-3.2 90B while being 7x smaller. We further contribute an open-source benchmark, MM-MT-Bench, for evaluating vision-language models in practical scenarios, and provide detailed analysis and code for standardized evaluation protocols for multimodal LLMs. Pixtral-12B is released under Apache 2.0 license.
Differentiable Clustering with Perturbed Spanning Forests
May 25, 2023We introduce a differentiable clustering method based on minimum-weight spanning forests, a variant of spanning trees with several connected components. Our method relies on stochastic perturbations of solutions of linear programs, for smoothing and efficient gradient computations. This allows us to include clustering in end-to-end trainable pipelines. We show that our method performs well even in difficult settings, such as datasets with high noise and challenging geometries. We also formulate an ad hoc loss to efficiently learn from partial clustering data using this operation. We demonstrate its performance on several real world datasets for supervised and semi-supervised tasks.
Regression as Classification: Influence of Task Formulation on Neural Network Features
Nov 10, 2022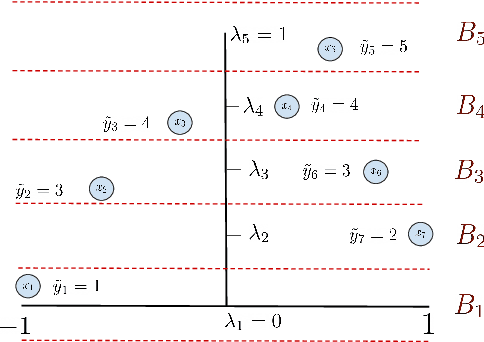
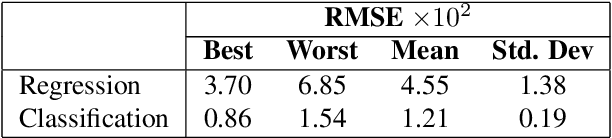
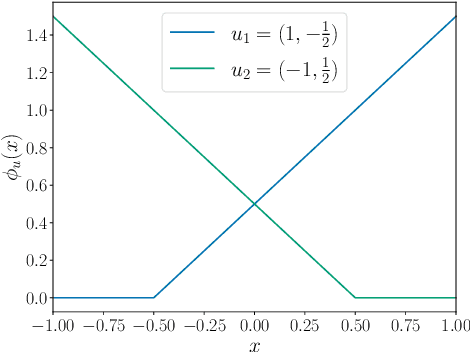
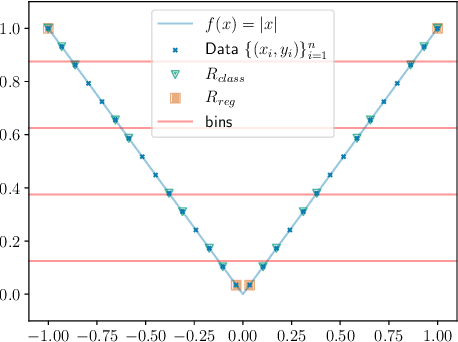
Neural networks can be trained to solve regression problems by using gradient-based methods to minimize the square loss. However, practitioners often prefer to reformulate regression as a classification problem, observing that training on the cross entropy loss results in better performance. By focusing on two-layer ReLU networks, which can be fully characterized by measures over their feature space, we explore how the implicit bias induced by gradient-based optimization could partly explain the above phenomenon. We provide theoretical evidence that the regression formulation yields a measure whose support can differ greatly from that for classification, in the case of one-dimensional data. Our proposed optimal supports correspond directly to the features learned by the input layer of the network. The different nature of these supports sheds light on possible optimization difficulties the square loss could encounter during training, and we present empirical results illustrating this phenomenon.
Bayesian Optimization for Parameter Tuning of the XOR Neural Network
Nov 14, 2017

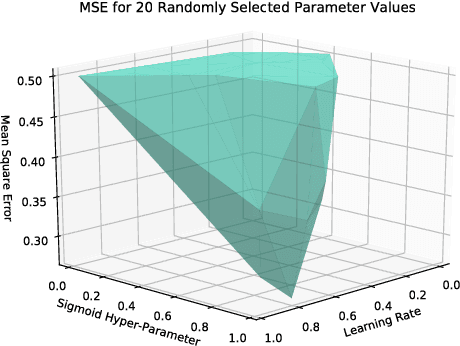

When applying Machine Learning techniques to problems, one must select model parameters to ensure that the system converges but also does not become stuck at the objective function's local minimum. Tuning these parameters becomes a non-trivial task for large models and it is not always apparent if the user has found the optimal parameters. We aim to automate the process of tuning a Neural Network, (where only a limited number of parameter search attempts are available) by implementing Bayesian Optimization. In particular, by assigning Gaussian Process Priors to the parameter space, we utilize Bayesian Optimization to tune an Artificial Neural Network used to learn the XOR function, with the result of achieving higher prediction accuracy.