 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegression as Classification: Influence of Task Formulation on Neural Network Features
Nov 10, 2022
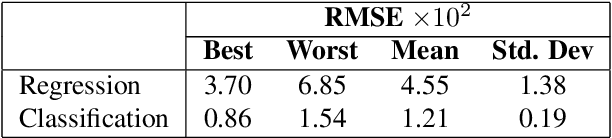
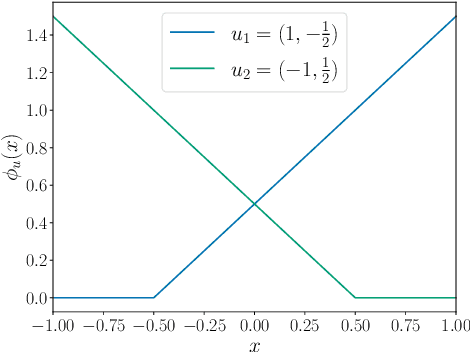
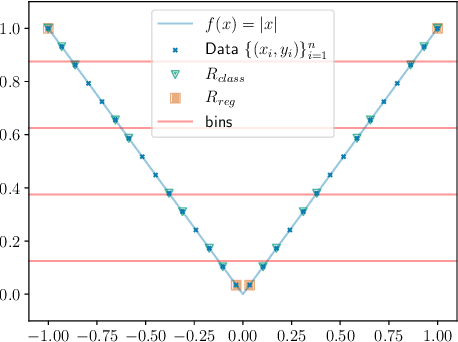
Neural networks can be trained to solve regression problems by using gradient-based methods to minimize the square loss. However, practitioners often prefer to reformulate regression as a classification problem, observing that training on the cross entropy loss results in better performance. By focusing on two-layer ReLU networks, which can be fully characterized by measures over their feature space, we explore how the implicit bias induced by gradient-based optimization could partly explain the above phenomenon. We provide theoretical evidence that the regression formulation yields a measure whose support can differ greatly from that for classification, in the case of one-dimensional data. Our proposed optimal supports correspond directly to the features learned by the input layer of the network. The different nature of these supports sheds light on possible optimization difficulties the square loss could encounter during training, and we present empirical results illustrating this phenomenon.
Scaling ResNets in the Large-depth Regime
Jun 14, 2022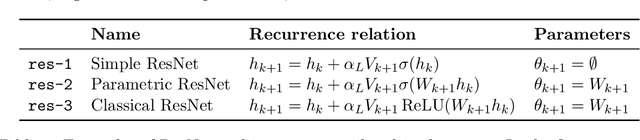
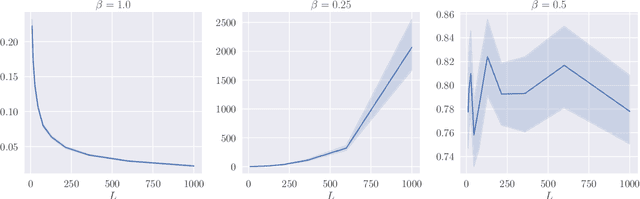
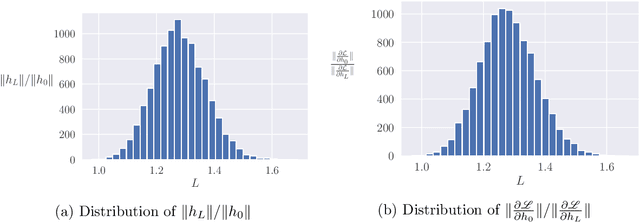
Deep ResNets are recognized for achieving state-of-the-art results in complex machine learning tasks. However, the remarkable performance of these architectures relies on a training procedure that needs to be carefully crafted to avoid vanishing or exploding gradients, particularly as the depth $L$ increases. No consensus has been reached on how to mitigate this issue, although a widely discussed strategy consists in scaling the output of each layer by a factor $\alpha_L$. We show in a probabilistic setting that with standard i.i.d. initializations, the only non-trivial dynamics is for $\alpha_L = 1/\sqrt{L}$ (other choices lead either to explosion or to identity mapping). This scaling factor corresponds in the continuous-time limit to a neural stochastic differential equation, contrarily to a widespread interpretation that deep ResNets are discretizations of neural ordinary differential equations. By contrast, in the latter regime, stability is obtained with specific correlated initializations and $\alpha_L = 1/L$. Our analysis suggests a strong interplay between scaling and regularity of the weights as a function of the layer index. Finally, in a series of experiments, we exhibit a continuous range of regimes driven by these two parameters, which jointly impact performance before and after training.
Framing RNN as a kernel method: A neural ODE approach
Jun 02, 2021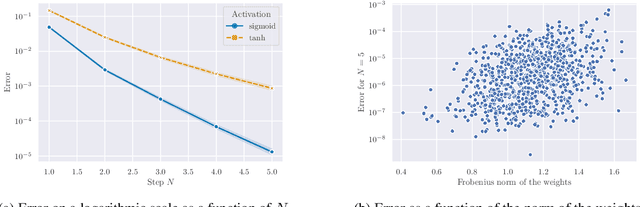
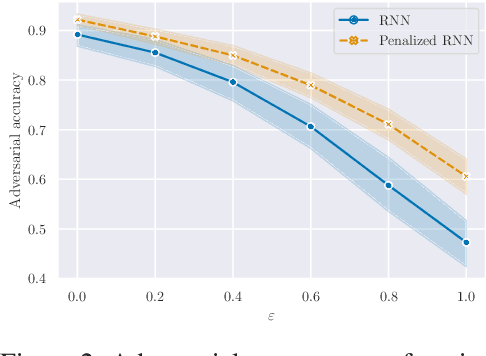
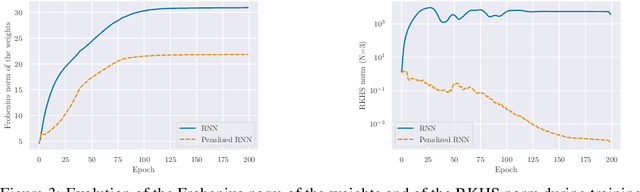
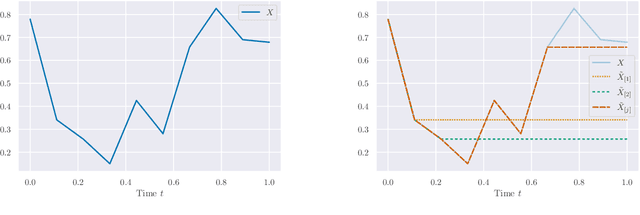
Building on the interpretation of a recurrent neural network (RNN) as a continuous-time neural differential equation, we show, under appropriate conditions, that the solution of a RNN can be viewed as a linear function of a specific feature set of the input sequence, known as the signature. This connection allows us to frame a RNN as a kernel method in a suitable reproducing kernel Hilbert space. As a consequence, we obtain theoretical guarantees on generalization and stability for a large class of recurrent networks. Our results are illustrated on simulated datasets.
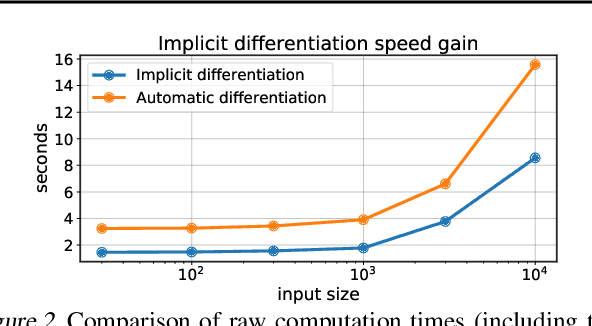
Efficient and Modular Implicit Differentiation
May 31, 2021

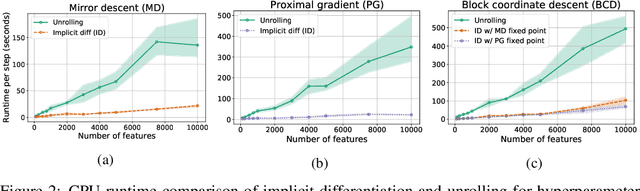

Automatic differentiation (autodiff) has revolutionized machine learning. It allows expressing complex computations by composing elementary ones in creative ways and removes the burden of computing their derivatives by hand. More recently, differentiation of optimization problem solutions has attracted widespread attention with applications such as optimization as a layer, and in bi-level problems such as hyper-parameter optimization and meta-learning. However, the formulas for these derivatives often involve case-by-case tedious mathematical derivations. In this paper, we propose a unified, efficient and modular approach for implicit differentiation of optimization problems. In our approach, the user defines (in Python in the case of our implementation) a function $F$ capturing the optimality conditions of the problem to be differentiated. Once this is done, we leverage autodiff of $F$ and implicit differentiation to automatically differentiate the optimization problem. Our approach thus combines the benefits of implicit differentiation and autodiff. It is efficient as it can be added on top of any state-of-the-art solver and modular as the optimality condition specification is decoupled from the implicit differentiation mechanism. We show that seemingly simple principles allow to recover many recently proposed implicit differentiation methods and create new ones easily. We demonstrate the ease of formulating and solving bi-level optimization problems using our framework. We also showcase an application to the sensitivity analysis of molecular dynamics.
Differentiable Divergences Between Time Series
Oct 16, 2020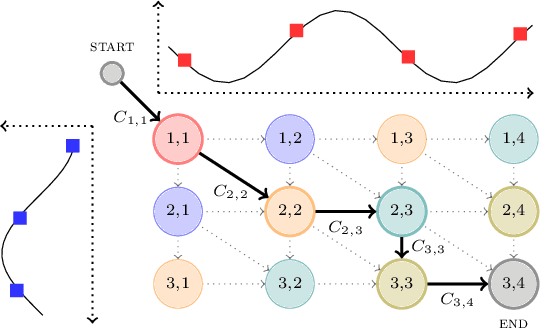

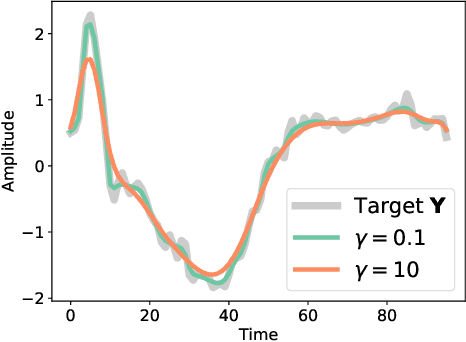
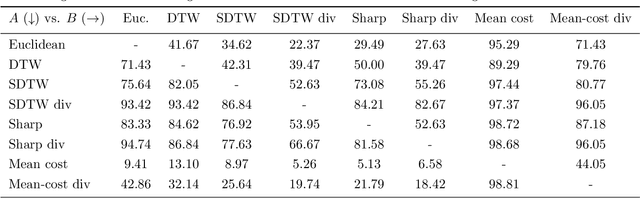
Computing the discrepancy between time series of variable sizes is notoriously challenging. While dynamic time warping (DTW) is popularly used for this purpose, it is not differentiable everywhere and is known to lead to bad local optima when used as a "loss". Soft-DTW addresses these issues, but it is not a positive definite divergence: due to the bias introduced by entropic regularization, it can be negative and it is not minimized when the time series are equal. We propose in this paper a new divergence, dubbed soft-DTW divergence, which aims to correct these issues. We study its properties; in particular, under conditions on the ground cost, we show that it is non-negative and minimized when the time series are equal. We also propose a new "sharp" variant by further removing entropic bias. We showcase our divergences on time series averaging and demonstrate significant accuracy improvements compared to both DTW and soft-DTW on 84 time series classification datasets.
On Mixup Regularization
Jun 10, 2020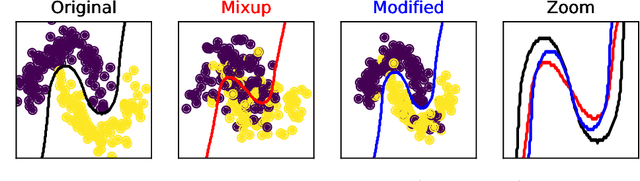

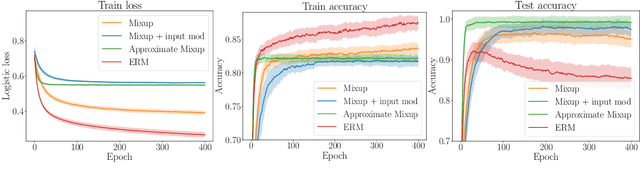
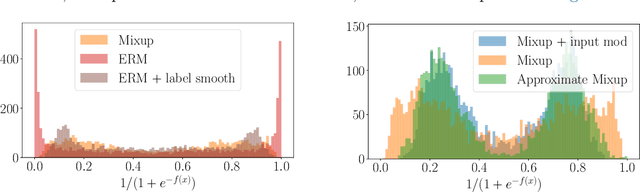
Mixup is a data augmentation technique that creates new examples as convex combinations of training points and labels. This simple technique has empirically shown to improve the accuracy of many state-of-the-art models in different settings and applications, but the reasons behind this empirical success remain poorly understood. In this paper we take a substantial step in explaining the theoretical foundations of Mixup, by clarifying its regularization effects. We show that Mixup can be interpreted as standard empirical risk minimization estimator subject to a combination of data transformation and random perturbation of the transformed data. We further show that these transformations and perturbations induce multiple known regularization schemes, including label smoothing and reduction of the Lipschitz constant of the estimator, and that these schemes interact synergistically with each other, resulting in a self calibrated and effective regularization effect that prevents overfitting and overconfident predictions. We illustrate our theoretical analysis by experiments that empirically support our conclusions.
Noisy Adaptive Group Testing using Bayesian Sequential Experimental Design
May 15, 2020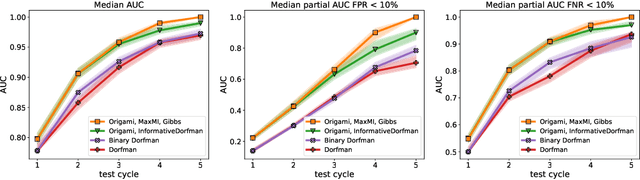

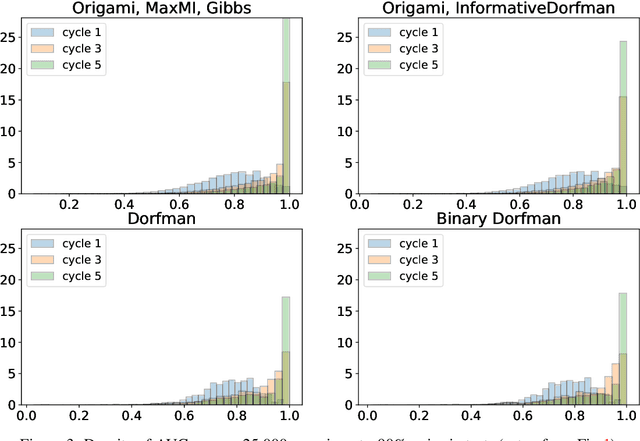

When test resources are scarce and infection prevalence is low, testing groups of individuals can be more efficient than testing individuals. This can be done by pooling individual samples (in groups, and only test those groups for the presence of a pathogen. The rationale is that if prevalence is low, many of these groups will ideally test negative, clearing all all individuals from such groups, whereas individuals appearing in (ideally few) positive groups will require further screening. Forming those groups in order to minimize testing costs while maintaining good detection is the goal of group testing algorithms. We propose a new framework to form such groups that takes into account various constraints of the testing environment, and which can easily incorporate individualized infection priors. Our solution solves a Bayesian sequential experimental design problem: Given previous group test results, we sample the posterior distribution of infection status vectors using sequential Monte Carlo samplers; these samples are then fed to an optimizer, which seeks to form groups that maximize an information gain if those future tests were to be known. To output marginal probabilities of infection, we use loopy belief propagation as a decoder. We show a significant empirical improvement over individualized tests in simulations: our G-MIMAX test procedure has an average specificity/sensitivity that significantly exceeds that of other baselines, including individual tests, as long as the disease prevalence $\leq 5\%$.
MissDeepCausal: Causal Inference from Incomplete Data Using Deep Latent Variable Models
Feb 25, 2020
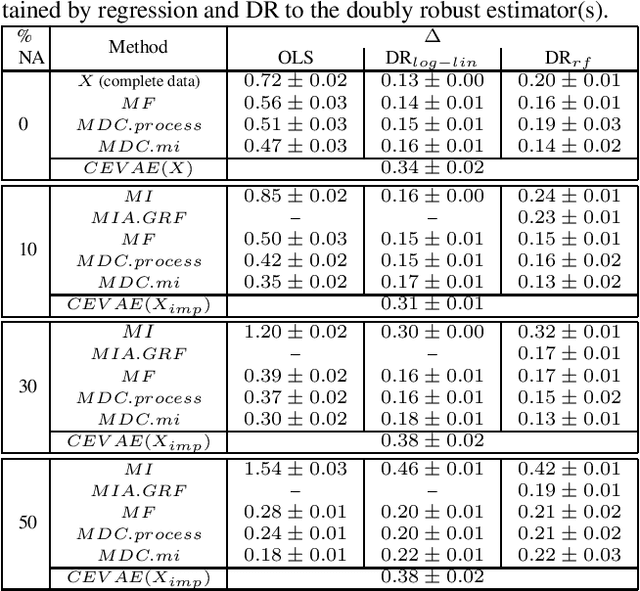
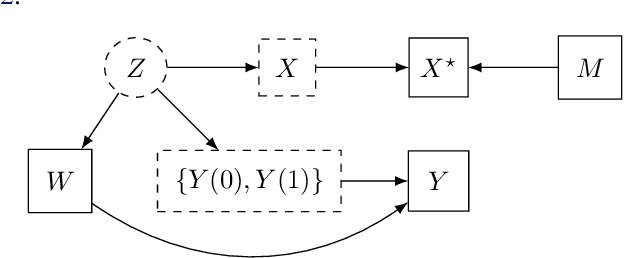
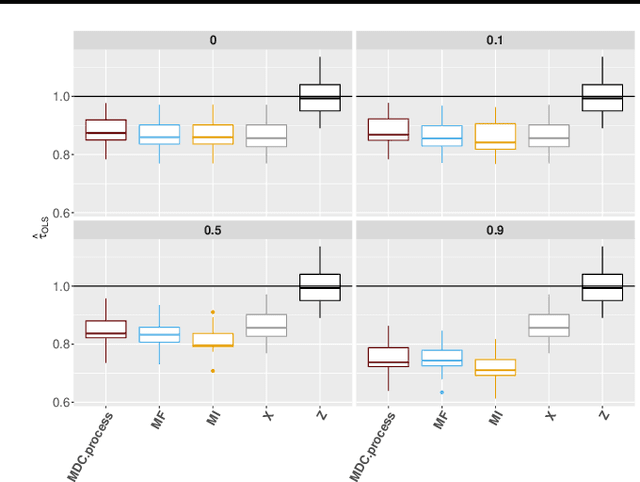
Inferring causal effects of a treatment, intervention or policy from observational data is central to many applications. However, state-of-the-art methods for causal inference seldom consider the possibility that covariates have missing values, which is ubiquitous in many real-world analyses. Missing data greatly complicate causal inference procedures as they require an adapted unconfoundedness hypothesis which can be difficult to justify in practice. We circumvent this issue by considering latent confounders whose distribution is learned through variational autoencoders adapted to missing values. They can be used either as a pre-processing step prior to causal inference but we also suggest to embed them in a multiple imputation strategy to take into account the variability due to missing values. Numerical experiments demonstrate the effectiveness of the proposed methodology especially for non-linear models compared to competitors.
Learning with Differentiable Perturbed Optimizers
Feb 20, 2020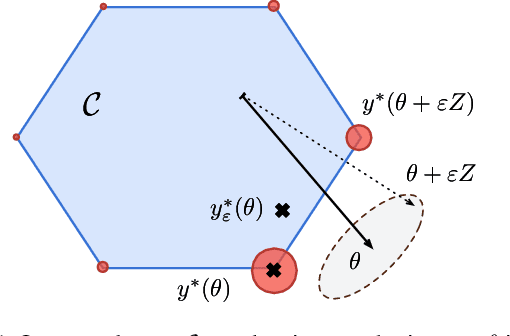
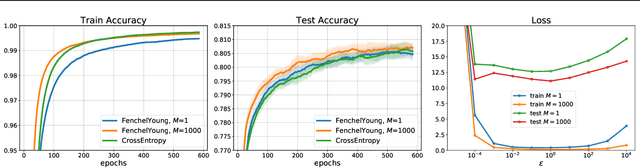

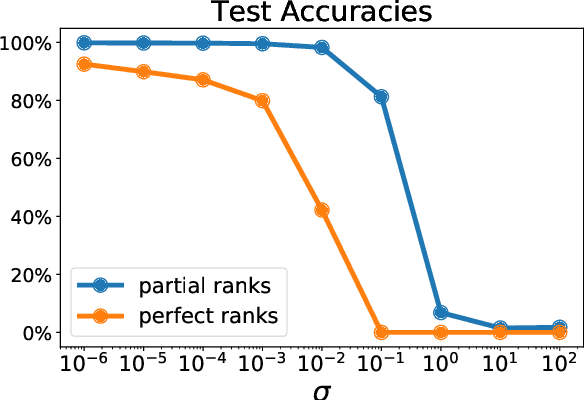
Machine learning pipelines often rely on optimization procedures to make discrete decisions (e.g. sorting, picking closest neighbors, finding shortest paths or optimal matchings). Although these discrete decisions are easily computed in a forward manner, they cannot be used to modify model parameters using first-order optimization techniques because they break the back-propagation of computational graphs. In order to expand the scope of learning problems that can be solved in an end-to-end fashion, we propose a systematic method to transform a block that outputs an optimal discrete decision into a differentiable operation. Our approach relies on stochastic perturbations of these parameters, and can be used readily within existing solvers without the need for ad hoc regularization or smoothing. These perturbed optimizers yield solutions that are differentiable and never locally constant. The amount of smoothness can be tuned via the chosen noise amplitude, whose impact we analyze. The derivatives of these perturbed solvers can be evaluated efficiently. We also show how this framework can be connected to a family of losses developed in structured prediction, and describe how these can be used in unsupervised and supervised learning, with theoretical guarantees. We demonstrate the performance of our approach on several machine learning tasks in experiments on synthetic and real data.
Supervised Quantile Normalization for Low-rank Matrix Approximation
Feb 08, 2020

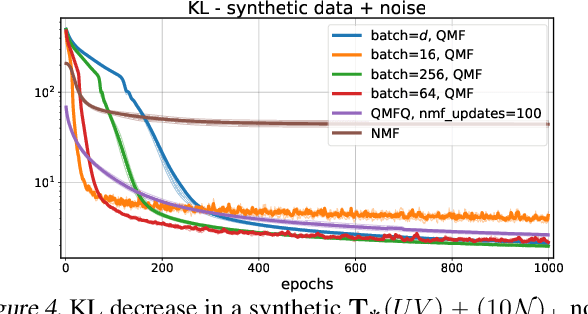
Low rank matrix factorization is a fundamental building block in machine learning, used for instance to summarize gene expression profile data or word-document counts. To be robust to outliers and differences in scale across features, a matrix factorization step is usually preceded by ad-hoc feature normalization steps, such as \texttt{tf-idf} scaling or data whitening. We propose in this work to learn these normalization operators jointly with the factorization itself. More precisely, given a $d\times n$ matrix $X$ of $d$ features measured on $n$ individuals, we propose to learn the parameters of quantile normalization operators that can operate row-wise on the values of $X$ and/or of its factorization $UV$ to improve the quality of the low-rank representation of $X$ itself. This optimization is facilitated by the introduction of a differentiable quantile normalization operator built using optimal transport, providing new results on top of existing work by Cuturi et al. (2019). We demonstrate the applicability of these techniques on synthetic and genomics datasets.