 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynaMiCS: Fine-tuning LLMs with Performance Constraints using Dynamic Mixtures
May 11, 2026Multi-domain fine-tuning of large language models requires improving performance on target domains while preserving performance on constrained domains, such as general knowledge, instruction following, or safety evaluations. Existing data mixing strategies rely on fixed heuristics or adaptive rules that cannot explicitly enforce preservation of such capabilities. We propose DynaMiCS, a dynamic mixture optimizer that casts multi-domain fine-tuning as a constrained optimization problem. At each update, DynaMiCS performs short domain-specific probing runs to estimate a slope matrix of local cross-domain effects, capturing how training on each fine-tuning dataset affects each evaluation domain. These estimates are then used to compute mixture weights through optimization over the probability simplex, with the objective of improving target-domain performance while keeping constrained-domain losses below reference levels. Across multi-domain fine-tuning scenarios with varying numbers of target and constrained domains, DynaMiCS achieves stronger target-domain improvements and higher constraint satisfaction than fixed-mixture baselines, at lower computational cost and without reference models, per-example scoring, or manually tuned mixture weights.
Locking Pretrained Weights via Deep Low-Rank Residual Distillation
May 11, 2026The quality of open-weight language models has dramatically improved in recent years. Sharing weights greatly facilitates model adoption by enabling their use across diverse hardware and software platforms. They also allow for more open research and testing, to the extent that users can use them as checkpoints, fine-tune them according to their needs, and potentially redistribute them. In some cases, however, concerns on modifying these weights towards unauthorized uses may outweigh the pros of giving users such a freedom. Defending against such adaptation is non-trivial: since an adaptive attacker can observe all weights and architectures by definition, they can reverse simple structural defenses, and use optimization to defeat the simplest locking mechanisms. In this work, we exploit the inference-training asymmetry of automatic differentiation as a novel defense axis. We propose DLR-Lock, a method where the purveyor of the model purposely replaces each pretrained MLP in their model with a deep low-rank residual network (DLR-Net) of comparable parameter count, forcing activation memory that grows linearly with depth during backpropagation. DLR-Nets are efficiently trained via module-wise distillation. We show that, beyond this memory overhead, DLR-Lock results in architectural mismatches that complicate the optimization landscape of standard fine-tuning, and a backward pass that incurs disproportionately more overhead than the forward pass. Our defense succeeds in withstanding adaptive attackers with full knowledge of the defense strategy while preserving the original model's capabilities. Experiments on LLM validate these claims.
Nectar: Neural Estimation of Cached-Token Attention via Regression
May 10, 2026Evaluating softmax attention over a fixed long context requires reading every cached key-value pair for each new query token. For a given context (a book, a manual, a legal corpus) the attention output is a deterministic function of the query. We propose Nectar, which fits a compact neural network to this function for queries drawn from a task-relevant distribution. Nectar fits two networks per layer and KV-head: a target network that predicts the attention output and a score network that predicts the log-normalizer. The pair plugs into the standard masked self-attention at inference time, replacing the $O(n)$ attention over the cache with a forward pass whose cost does not depend on $n$. Each module carries on the order of $|θ|$ parameters per layer and KV-head, typically much smaller than the $2nd$ KV-cache footprint at the same granularity. We report experiments on models from 1.7B to 8B parameters across five long-context datasets. The approximation error tracks the next-token accuracy gap to full attention, and allocating capacity non-uniformly across layers reduces that gap in our ablation. Beyond this analysis of metrics, we check that the text generations (following a question prompt) of a model equipped with a Nectar module match in semantic content those obtained by giving the same model access to the full cache.
Amortizing Maximum Inner Product Search with Learned Support Functions
Mar 09, 2026Maximum inner product search (MIPS) is a crucial subroutine in machine learning, requiring the identification of key vectors that align best with a given query. We propose amortized MIPS: a learning-based approach that trains neural networks to directly predict MIPS solutions, amortizing the computational cost of matching queries (drawn from a fixed distribution) to a fixed set of keys. Our key insight is that the MIPS value function, the maximal inner product between a query and keys, is also known as the support function of the set of keys. Support functions are convex, 1-homogeneous and their gradient w.r.t. the query is exactly the optimal key in the database. We approximate the support function using two complementary approaches: (1) we train an input-convex neural network (SupportNet) to model the support function directly; the optimal key can be recovered via (autodiff) gradient computation, and (2) we regress directly the optimal key from the query using a vector valued network (KeyNet), bypassing gradient computation entirely at inference time. To learn a SupportNet, we combine score regression with gradient matching losses, and propose homogenization wrappers that enforce the positive 1-homogeneity of a neural network, theoretically linking function values to gradients. To train a KeyNet, we introduce a score consistency loss derived from the Euler theorem for homogeneous functions. Our experiments show that learned SupportNet or KeyNet achieve high match rates and open up new directions to compress databases with a specific query distribution in mind.
The Coupling Within: Flow Matching via Distilled Normalizing Flows
Mar 09, 2026Flow models have rapidly become the go-to method for training and deploying large-scale generators, owing their success to inference-time flexibility via adjustable integration steps. A crucial ingredient in flow training is the choice of coupling measure for sampling noise/data pairs that define the flow matching (FM) regression loss. While FM training defaults usually to independent coupling, recent works show that adaptive couplings informed by noise/data distributions (e.g., via optimal transport, OT) improve both model training and inference. We radicalize this insight by shifting the paradigm: rather than computing adaptive couplings directly, we use distilled couplings from a different, pretrained model capable of placing noise and data spaces in bijection -- a property intrinsic to normalizing flows (NF) through their maximum likelihood and invertibility requirements. Leveraging recent advances in NF image generation via auto-regressive (AR) blocks, we propose Normalized Flow Matching (NFM), a new method that distills the quasi-deterministic coupling of pretrained NF models to train student flow models. These students achieve the best of both worlds: significantly outperforming flow models trained with independent or even OT couplings, while also improving on the teacher AR-NF model.
The Design Space of Tri-Modal Masked Diffusion Models
Feb 25, 2026Discrete diffusion models have emerged as strong alternatives to autoregressive language models, with recent work initializing and fine-tuning a base unimodal model for bimodal generation. Diverging from previous approaches, we introduce the first tri-modal masked diffusion model pretrained from scratch on text, image-text, and audio-text data. We systematically analyze multimodal scaling laws, modality mixing ratios, noise schedules, and batch-size effects, and we provide optimized inference sampling defaults. Our batch-size analysis yields a novel stochastic differential equation (SDE)-based reparameterization that eliminates the need for tuning the optimal batch size as reported in recent work. This reparameterization decouples the physical batch size, often chosen based on compute constraints (GPU saturation, FLOP efficiency, wall-clock time), from the logical batch size, chosen to balance gradient variance during stochastic optimization. Finally, we pretrain a preliminary 3B-parameter tri-modal model on 6.4T tokens, demonstrating the capabilities of a unified design and achieving strong results in text generation, text-to-image tasks, and text-to-speech tasks. Our work represents the largest-scale systematic open study of multimodal discrete diffusion models conducted to date, providing insights into scaling behaviors across multiple modalities.
LaCy: What Small Language Models Can and Should Learn is Not Just a Question of Loss
Feb 13, 2026Language models have consistently grown to compress more world knowledge into their parameters, but the knowledge that can be pretrained into them is upper-bounded by their parameter size. Especially the capacity of Small Language Models (SLMs) is limited, leading to factually incorrect generations. This problem is often mitigated by giving the SLM access to an outside source: the ability to query a larger model, documents, or a database. Under this setting, we study the fundamental question of \emph{which tokens an SLM can and should learn} during pretraining, versus \emph{which ones it should delegate} via a \texttt{<CALL>} token. We find that this is not simply a question of loss: although the loss is predictive of whether a predicted token mismatches the ground-truth, some tokens are \emph{acceptable} in that they are truthful alternative continuations of a pretraining document, and should not trigger a \texttt{<CALL>} even if their loss is high. We find that a spaCy grammar parser can help augment the loss signal to decide which tokens the SLM should learn to delegate to prevent factual errors and which are safe to learn and predict even under high losses. We propose LaCy, a novel pretraining method based on this token selection philosophy. Our experiments demonstrate that LaCy models successfully learn which tokens to predict and where to delegate for help. This results in higher FactScores when generating in a cascade with a bigger model and outperforms Rho or LLM-judge trained SLMs, while being simpler and cheaper.
Completed Hyperparameter Transfer across Modules, Width, Depth, Batch and Duration
Dec 26, 2025Hyperparameter tuning can dramatically impact training stability and final performance of large-scale models. Recent works on neural network parameterisations, such as $μ$P, have enabled transfer of optimal global hyperparameters across model sizes. These works propose an empirical practice of search for optimal global base hyperparameters at a small model size, and transfer to a large size. We extend these works in two key ways. To handle scaling along most important scaling axes, we propose the Complete$^{(d)}$ Parameterisation that unifies scaling in width and depth -- using an adaptation of CompleteP -- as well as in batch-size and training duration. Secondly, with our parameterisation, we investigate per-module hyperparameter optimisation and transfer. We characterise the empirical challenges of navigating the high-dimensional hyperparameter landscape, and propose practical guidelines for tackling this optimisation problem. We demonstrate that, with the right parameterisation, hyperparameter transfer holds even in the per-module hyperparameter regime. Our study covers an extensive range of optimisation hyperparameters of modern models: learning rates, AdamW parameters, weight decay, initialisation scales, and residual block multipliers. Our experiments demonstrate significant training speed improvements in Large Language Models with the transferred per-module hyperparameters.
Learning Unmasking Policies for Diffusion Language Models
Dec 12, 2025Diffusion (Large) Language Models (dLLMs) now match the downstream performance of their autoregressive counterparts on many tasks, while holding the promise of being more efficient during inference. One particularly successful variant is masked discrete diffusion, in which a buffer filled with special mask tokens is progressively replaced with tokens sampled from the model's vocabulary. Efficiency can be gained by unmasking several tokens in parallel, but doing too many at once risks degrading the generation quality. Thus, one critical design aspect of dLLMs is the sampling procedure that selects, at each step of the diffusion process, which tokens to replace. Indeed, recent work has found that heuristic strategies such as confidence thresholding lead to both higher quality and token throughput compared to random unmasking. However, such heuristics have downsides: they require manual tuning, and we observe that their performance degrades with larger buffer sizes. In this work, we instead propose to train sampling procedures using reinforcement learning. Specifically, we formalize masked diffusion sampling as a Markov decision process in which the dLLM serves as the environment, and propose a lightweight policy architecture based on a single-layer transformer that maps dLLM token confidences to unmasking decisions. Our experiments show that these trained policies match the performance of state-of-the-art heuristics when combined with semi-autoregressive generation, while outperforming them in the full diffusion setting. We also examine the transferability of these policies, finding that they can generalize to new underlying dLLMs and longer sequence lengths. However, we also observe that their performance degrades when applied to out-of-domain data, and that fine-grained tuning of the accuracy-efficiency trade-off can be challenging with our approach.
The Data-Quality Illusion: Rethinking Classifier-Based Quality Filtering for LLM Pretraining
Oct 02, 2025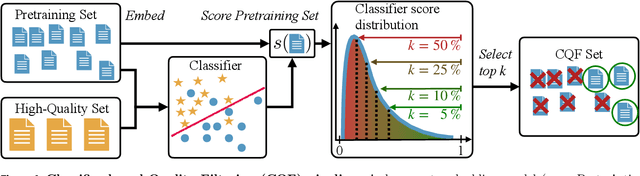
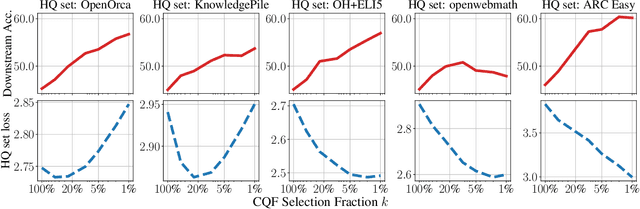
Large-scale models are pretrained on massive web-crawled datasets containing documents of mixed quality, making data filtering essential. A popular method is Classifier-based Quality Filtering (CQF), which trains a binary classifier to distinguish between pretraining data and a small, high-quality set. It assigns each pretraining document a quality score defined as the classifier's score and retains only the top-scoring ones. We provide an in-depth analysis of CQF. We show that while CQF improves downstream task performance, it does not necessarily enhance language modeling on the high-quality dataset. We explain this paradox by the fact that CQF implicitly filters the high-quality dataset as well. We further compare the behavior of models trained with CQF to those trained on synthetic data of increasing quality, obtained via random token permutations, and find starkly different trends. Our results challenge the view that CQF captures a meaningful notion of data quality.