 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Modeling of Photoplethysmography for Non-invasive Monitoring of Cardiovascular Parameters
Nov 18, 2025Continuous cardiovascular monitoring can play a key role in precision health. However, some fundamental cardiac biomarkers of interest, including stroke volume and cardiac output, require invasive measurements, e.g., arterial pressure waveforms (APW). As a non-invasive alternative, photoplethysmography (PPG) measurements are routinely collected in hospital settings. Unfortunately, the prediction of key cardiac biomarkers from PPG instead of APW remains an open challenge, further complicated by the scarcity of annotated PPG measurements. As a solution, we propose a hybrid approach that uses hemodynamic simulations and unlabeled clinical data to estimate cardiovascular biomarkers directly from PPG signals. Our hybrid model combines a conditional variational autoencoder trained on paired PPG-APW data with a conditional density estimator of cardiac biomarkers trained on labeled simulated APW segments. As a key result, our experiments demonstrate that the proposed approach can detect fluctuations of cardiac output and stroke volume and outperform a supervised baseline in monitoring temporal changes in these biomarkers.
Inferring Optical Tissue Properties from Photoplethysmography using Hybrid Amortized Inference
Oct 02, 2025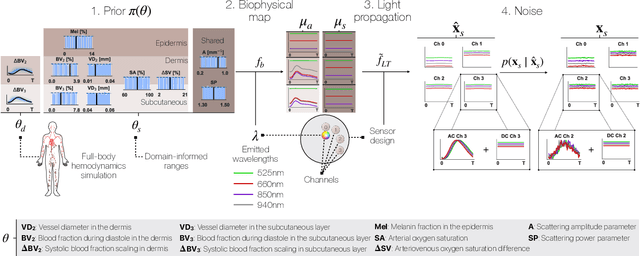
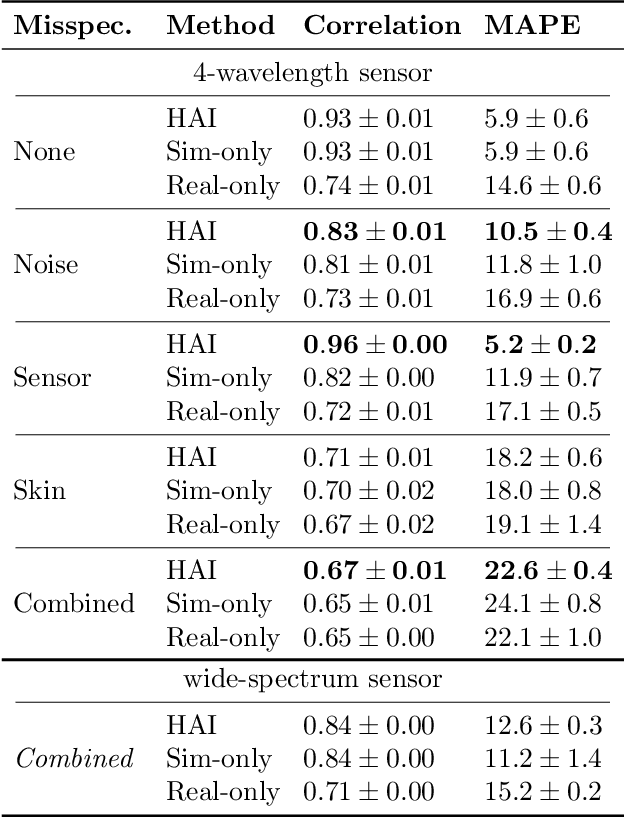
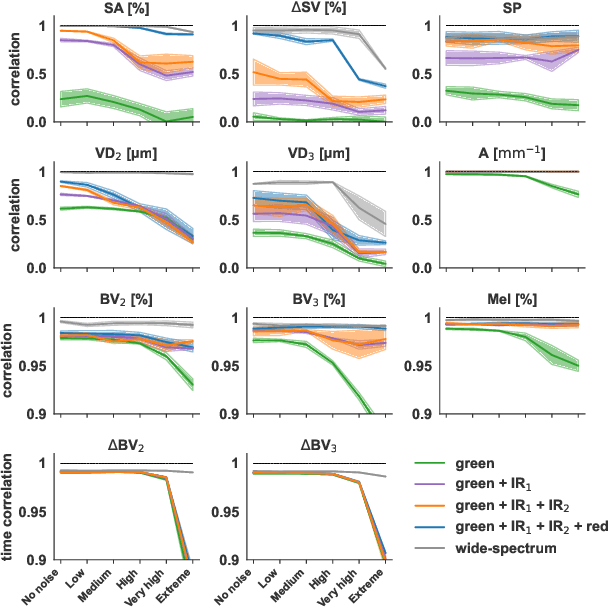

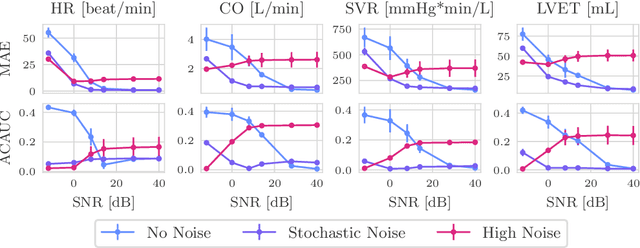
Smart wearables enable continuous tracking of established biomarkers such as heart rate, heart rate variability, and blood oxygen saturation via photoplethysmography (PPG). Beyond these metrics, PPG waveforms contain richer physiological information, as recent deep learning (DL) studies demonstrate. However, DL models often rely on features with unclear physiological meaning, creating a tension between predictive power, clinical interpretability, and sensor design. We address this gap by introducing PPGen, a biophysical model that relates PPG signals to interpretable physiological and optical parameters. Building on PPGen, we propose hybrid amortized inference (HAI), enabling fast, robust, and scalable estimation of relevant physiological parameters from PPG signals while correcting for model misspecification. In extensive in-silico experiments, we show that HAI can accurately infer physiological parameters under diverse noise and sensor conditions. Our results illustrate a path toward PPG models that retain the fidelity needed for DL-based features while supporting clinical interpretation and informed hardware design.
Leveraging Cardiovascular Simulations for In-Vivo Prediction of Cardiac Biomarkers
Dec 23, 2024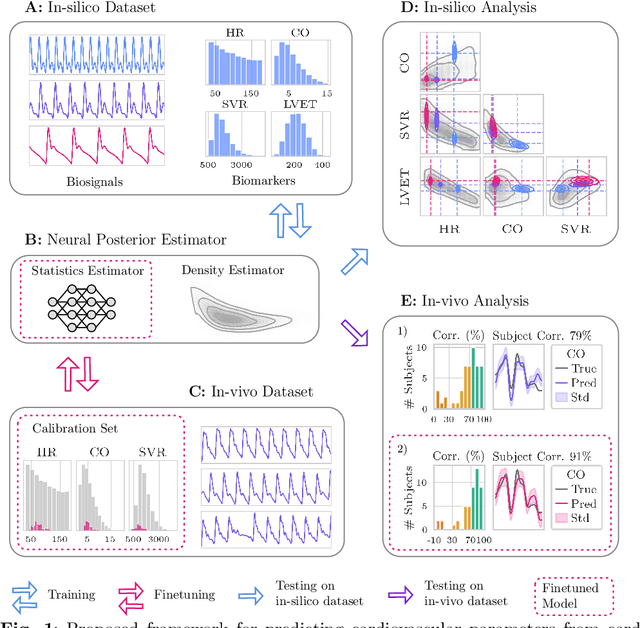
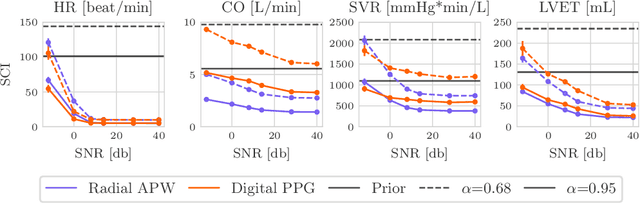
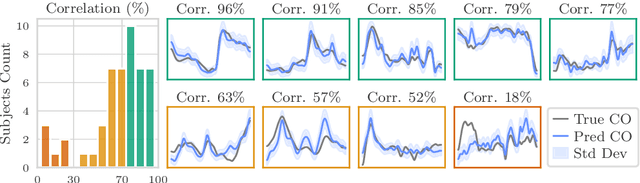
Whole-body hemodynamics simulators, which model blood flow and pressure waveforms as functions of physiological parameters, are now essential tools for studying cardiovascular systems. However, solving the corresponding inverse problem of mapping observations (e.g., arterial pressure waveforms at specific locations in the arterial network) back to plausible physiological parameters remains challenging. Leveraging recent advances in simulation-based inference, we cast this problem as statistical inference by training an amortized neural posterior estimator on a newly built large dataset of cardiac simulations that we publicly release. To better align simulated data with real-world measurements, we incorporate stochastic elements modeling exogenous effects. The proposed framework can further integrate in-vivo data sources to refine its predictive capabilities on real-world data. In silico, we demonstrate that the proposed framework enables finely quantifying uncertainty associated with individual measurements, allowing trustworthy prediction of four biomarkers of clinical interest--namely Heart Rate, Cardiac Output, Systemic Vascular Resistance, and Left Ventricular Ejection Time--from arterial pressure waveforms and photoplethysmograms. Furthermore, we validate the framework in vivo, where our method accurately captures temporal trends in CO and SVR monitoring on the VitalDB dataset. Finally, the predictive error made by the model monotonically increases with the predicted uncertainty, thereby directly supporting the automatic rejection of unusable measurements.
Addressing Misspecification in Simulation-based Inference through Data-driven Calibration
May 14, 2024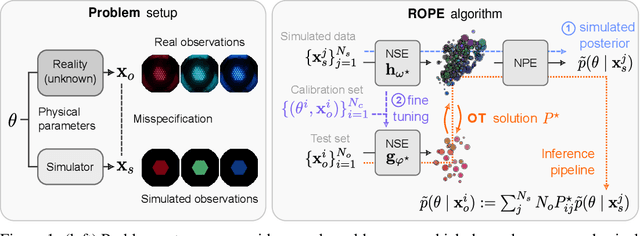
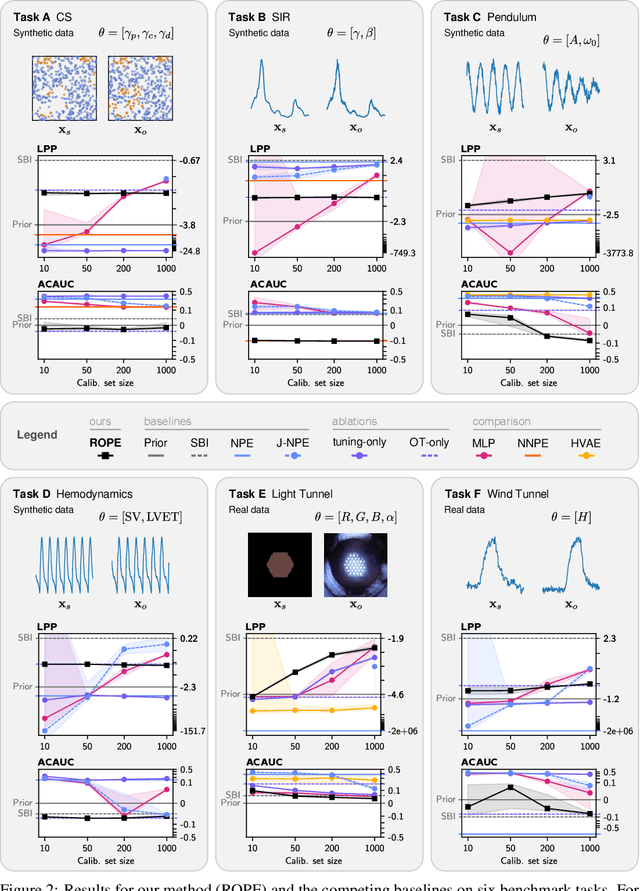
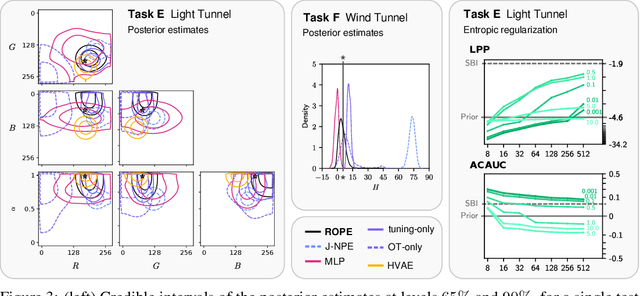
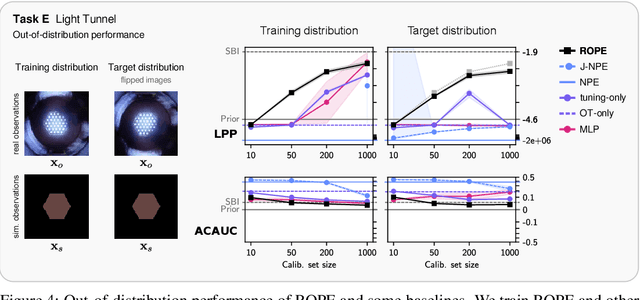
Driven by steady progress in generative modeling, simulation-based inference (SBI) has enabled inference over stochastic simulators. However, recent work has demonstrated that model misspecification can harm SBI's reliability. This work introduces robust posterior estimation (ROPE), a framework that overcomes model misspecification with a small real-world calibration set of ground truth parameter measurements. We formalize the misspecification gap as the solution of an optimal transport problem between learned representations of real-world and simulated observations. Assuming the prior distribution over the parameters of interest is known and well-specified, our method offers a controllable balance between calibrated uncertainty and informative inference under all possible misspecifications of the simulator. Our empirical results on four synthetic tasks and two real-world problems demonstrate that ROPE outperforms baselines and consistently returns informative and calibrated credible intervals.
Simulation-based Inference for Cardiovascular Models
Jul 29, 2023



Over the past decades, hemodynamics simulators have steadily evolved and have become tools of choice for studying cardiovascular systems in-silico. While such tools are routinely used to simulate whole-body hemodynamics from physiological parameters, solving the corresponding inverse problem of mapping waveforms back to plausible physiological parameters remains both promising and challenging. Motivated by advances in simulation-based inference (SBI), we cast this inverse problem as statistical inference. In contrast to alternative approaches, SBI provides \textit{posterior distributions} for the parameters of interest, providing a \textit{multi-dimensional} representation of uncertainty for \textit{individual} measurements. We showcase this ability by performing an in-silico uncertainty analysis of five biomarkers of clinical interest comparing several measurement modalities. Beyond the corroboration of known facts, such as the feasibility of estimating heart rate, our study highlights the potential of estimating new biomarkers from standard-of-care measurements. SBI reveals practically relevant findings that cannot be captured by standard sensitivity analyses, such as the existence of sub-populations for which parameter estimation exhibits distinct uncertainty regimes. Finally, we study the gap between in-vivo and in-silico with the MIMIC-III waveform database and critically discuss how cardiovascular simulations can inform real-world data analysis.
Robust Hybrid Learning With Expert Augmentation
Feb 09, 2022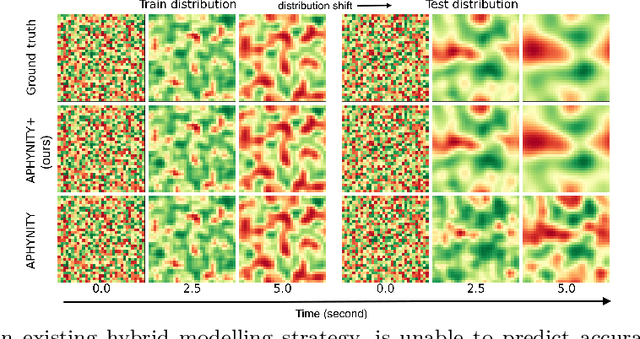
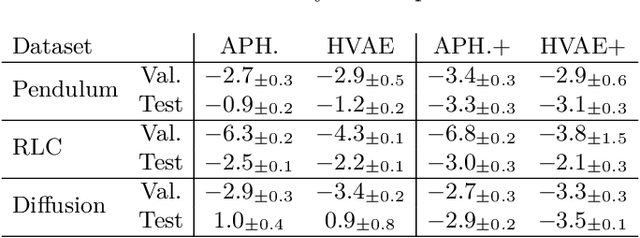
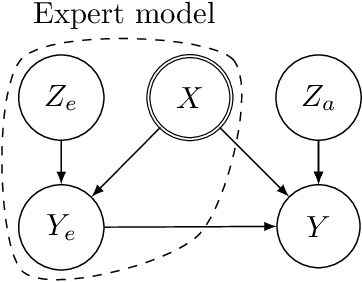
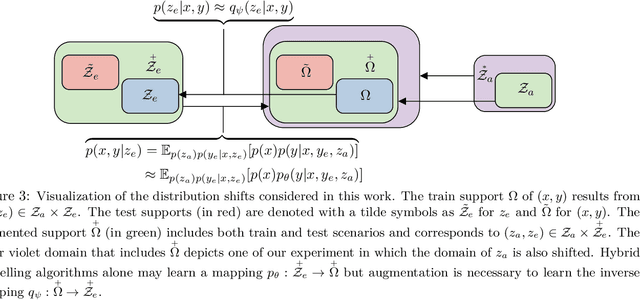
Hybrid modelling reduces the misspecification of expert models by combining them with machine learning (ML) components learned from data. Like for many ML algorithms, hybrid model performance guarantees are limited to the training distribution. Leveraging the insight that the expert model is usually valid even outside the training domain, we overcome this limitation by introducing a hybrid data augmentation strategy termed \textit{expert augmentation}. Based on a probabilistic formalization of hybrid modelling, we show why expert augmentation improves generalization. Finally, we validate the practical benefits of augmented hybrid models on a set of controlled experiments, modelling dynamical systems described by ordinary and partial differential equations.
Generalization of the Change of Variables Formula with Applications to Residual Flows
Jul 09, 2021

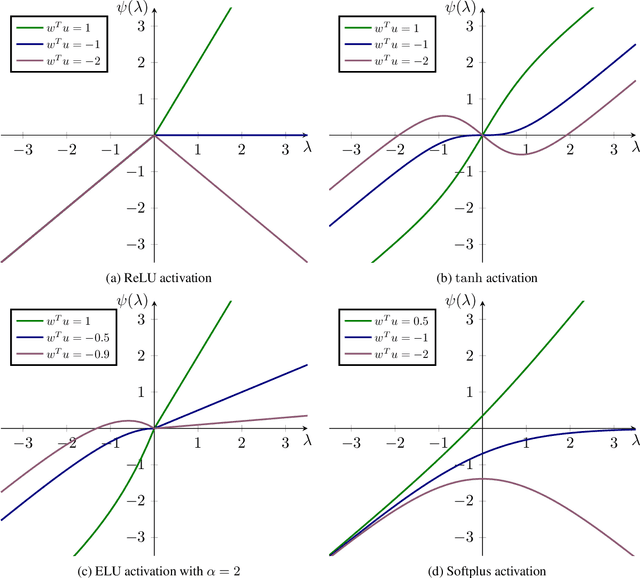
Normalizing flows leverage the Change of Variables Formula (CVF) to define flexible density models. Yet, the requirement of smooth transformations (diffeomorphisms) in the CVF poses a significant challenge in the construction of these models. To enlarge the design space of flows, we introduce $\mathcal{L}$-diffeomorphisms as generalized transformations which may violate these requirements on zero Lebesgue-measure sets. This relaxation allows e.g. the use of non-smooth activation functions such as ReLU. Finally, we apply the obtained results to planar, radial, and contractive residual flows.
Understanding and mitigating exploding inverses in invertible neural networks
Jun 16, 2020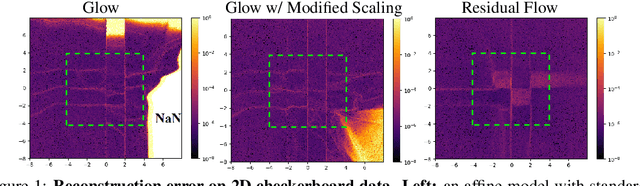
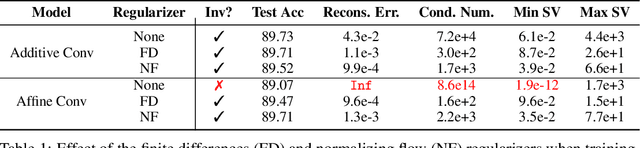

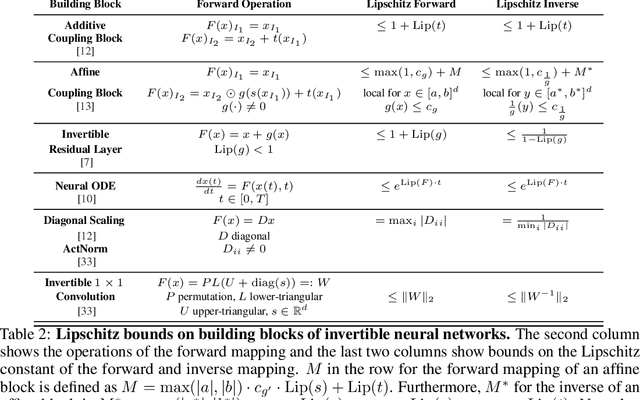
Invertible neural networks (INNs) have been used to design generative models, implement memory-saving gradient computation, and solve inverse problems. In this work, we show that commonly-used INN architectures suffer from exploding inverses and are thus prone to becoming numerically non-invertible. Across a wide range of INN use-cases, we reveal failures including the non-applicability of the change-of-variables formula on in- and out-of-distribution (OOD) data, incorrect gradients for memory-saving backprop, and the inability to sample from normalizing flow models. We further derive bi-Lipschitz properties of atomic building blocks of common architectures. These insights into the stability of INNs then provide ways forward to remedy these failures. For tasks where local invertibility is sufficient, like memory-saving backprop, we propose a flexible and efficient regularizer. For problems where global invertibility is necessary, such as applying normalizing flows on OOD data, we show the importance of designing stable INN building blocks.
Fundamental Tradeoffs between Invariance and Sensitivity to Adversarial Perturbations
Feb 11, 2020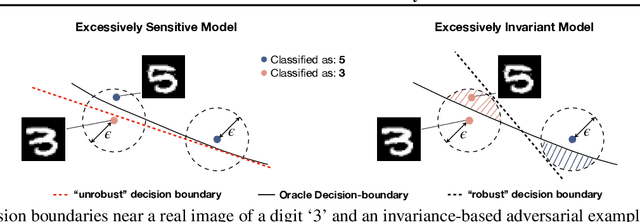

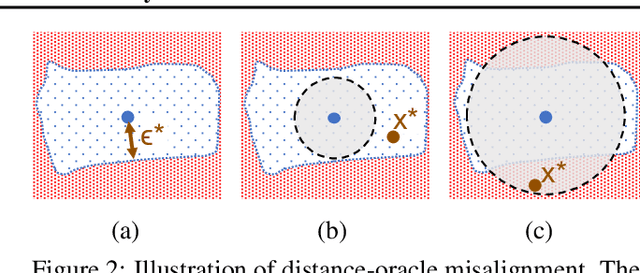
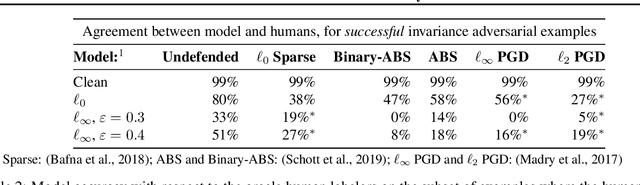
Adversarial examples are malicious inputs crafted to induce misclassification. Commonly studied sensitivity-based adversarial examples introduce semantically-small changes to an input that result in a different model prediction. This paper studies a complementary failure mode, invariance-based adversarial examples, that introduce minimal semantic changes that modify an input's true label yet preserve the model's prediction. We demonstrate fundamental tradeoffs between these two types of adversarial examples. We show that defenses against sensitivity-based attacks actively harm a model's accuracy on invariance-based attacks, and that new approaches are needed to resist both attack types. In particular, we break state-of-the-art adversarially-trained and certifiably-robust models by generating small perturbations that the models are (provably) robust to, yet that change an input's class according to human labelers. Finally, we formally show that the existence of excessively invariant classifiers arises from the presence of overly-robust predictive features in standard datasets.
Deep Relevance Regularization: Interpretable and Robust Tumor Typing of Imaging Mass Spectrometry Data
Dec 10, 2019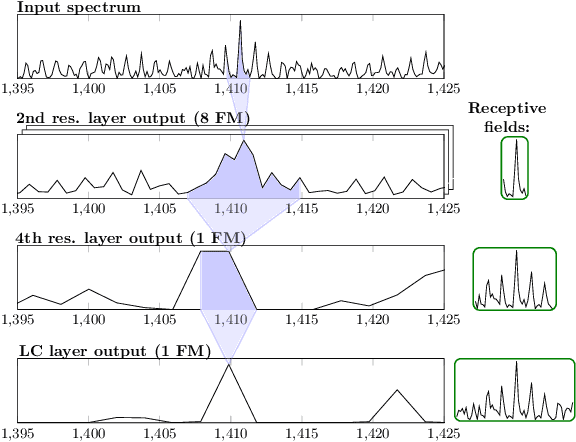

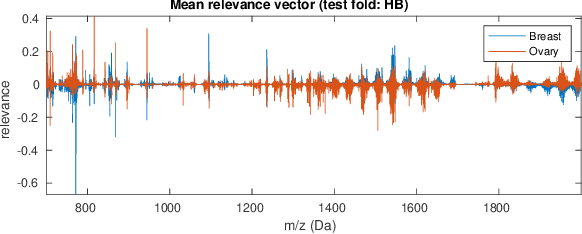
Neural networks have recently been established as a viable classification method for imaging mass spectrometry data for tumor typing. For multi-laboratory scenarios however, certain confounding factors may strongly impede their performance. In this work, we introduce Deep Relevance Regularization, a method of restricting what the neural network can focus on during classification, in order to improve the classification performance. We demonstrate how Deep Relevance Regularization robustifies neural networks against confounding factors on a challenging inter-lab dataset consisting of breast and ovarian carcinoma. We further show that this makes the relevance map -- a way of visualizing the discriminative parts of the mass spectrum -- sparser, thereby making the classifier easier to interpret