 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGauss-Newton Unlearning for the LLM Era
Feb 11, 2026Standard large language model training can create models that produce outputs their trainer deems unacceptable in deployment. The probability of these outputs can be reduced using methods such as LLM unlearning. However, unlearning a set of data (called the forget set) can degrade model performance on other distributions where the trainer wants to retain the model's behavior. To improve this trade-off, we demonstrate that using the forget set to compute only a few uphill Gauss-Newton steps provides a conceptually simple, state-of-the-art unlearning approach for LLMs. While Gauss-Newton steps adapt Newton's method to non-linear models, it is non-trivial to efficiently and accurately compute such steps for LLMs. Hence, our approach crucially relies on parametric Hessian approximations such as Kronecker-Factored Approximate Curvature (K-FAC). We call this combined approach K-FADE (K-FAC for Distribution Erasure). Our evaluation on the WMDP and ToFU benchmarks demonstrates that K-FADE suppresses outputs from the forget set and approximates, in output space, the results of retraining without the forget set. Critically, our method does this while altering the outputs on the retain set less than previous methods. This is because K-FADE transforms a constraint on the model's outputs across the entire retain set into a constraint on the model's weights, allowing the algorithm to minimally change the model's behavior on the retain set at each step. Moreover, the unlearning updates computed by K-FADE can be reapplied later if the model undergoes further training, allowing unlearning to be cheaply maintained.
CaMeLs Can Use Computers Too: System-level Security for Computer Use Agents
Jan 14, 2026AI agents are vulnerable to prompt injection attacks, where malicious content hijacks agent behavior to steal credentials or cause financial loss. The only known robust defense is architectural isolation that strictly separates trusted task planning from untrusted environment observations. However, applying this design to Computer Use Agents (CUAs) -- systems that automate tasks by viewing screens and executing actions -- presents a fundamental challenge: current agents require continuous observation of UI state to determine each action, conflicting with the isolation required for security. We resolve this tension by demonstrating that UI workflows, while dynamic, are structurally predictable. We introduce Single-Shot Planning for CUAs, where a trusted planner generates a complete execution graph with conditional branches before any observation of potentially malicious content, providing provable control flow integrity guarantees against arbitrary instruction injections. Although this architectural isolation successfully prevents instruction injections, we show that additional measures are needed to prevent Branch Steering attacks, which manipulate UI elements to trigger unintended valid paths within the plan. We evaluate our design on OSWorld, and retain up to 57% of the performance of frontier models while improving performance for smaller open-source models by up to 19%, demonstrating that rigorous security and utility can coexist in CUAs.
Beyond Laplace and Gaussian: Exploring the Generalized Gaussian Mechanism for Private Machine Learning
Jun 14, 2025Differential privacy (DP) is obtained by randomizing a data analysis algorithm, which necessarily introduces a tradeoff between its utility and privacy. Many DP mechanisms are built upon one of two underlying tools: Laplace and Gaussian additive noise mechanisms. We expand the search space of algorithms by investigating the Generalized Gaussian mechanism, which samples the additive noise term $x$ with probability proportional to $e^{-\frac{| x |}{\sigma}^{\beta} }$ for some $\beta \geq 1$. The Laplace and Gaussian mechanisms are special cases of GG for $\beta=1$ and $\beta=2$, respectively. In this work, we prove that all members of the GG family satisfy differential privacy, and provide an extension of an existing numerical accountant (the PRV accountant) for these mechanisms. We show that privacy accounting for the GG Mechanism and its variants is dimension independent, which substantially improves computational costs of privacy accounting. We apply the GG mechanism to two canonical tools for private machine learning, PATE and DP-SGD; we show empirically that $\beta$ has a weak relationship with test-accuracy, and that generally $\beta=2$ (Gaussian) is nearly optimal. This provides justification for the widespread adoption of the Gaussian mechanism in DP learning, and can be interpreted as a negative result, that optimizing over $\beta$ does not lead to meaningful improvements in performance.
Confidential Guardian: Cryptographically Prohibiting the Abuse of Model Abstention
May 29, 2025



Cautious predictions -- where a machine learning model abstains when uncertain -- are crucial for limiting harmful errors in safety-critical applications. In this work, we identify a novel threat: a dishonest institution can exploit these mechanisms to discriminate or unjustly deny services under the guise of uncertainty. We demonstrate the practicality of this threat by introducing an uncertainty-inducing attack called Mirage, which deliberately reduces confidence in targeted input regions, thereby covertly disadvantaging specific individuals. At the same time, Mirage maintains high predictive performance across all data points. To counter this threat, we propose Confidential Guardian, a framework that analyzes calibration metrics on a reference dataset to detect artificially suppressed confidence. Additionally, it employs zero-knowledge proofs of verified inference to ensure that reported confidence scores genuinely originate from the deployed model. This prevents the provider from fabricating arbitrary model confidence values while protecting the model's proprietary details. Our results confirm that Confidential Guardian effectively prevents the misuse of cautious predictions, providing verifiable assurances that abstention reflects genuine model uncertainty rather than malicious intent.
Private Rate-Constrained Optimization with Applications to Fair Learning
May 28, 2025



Many problems in trustworthy ML can be formulated as minimization of the model error under constraints on the prediction rates of the model for suitably-chosen marginals, including most group fairness constraints (demographic parity, equality of odds, etc.). In this work, we study such constrained minimization problems under differential privacy (DP). Standard DP optimization techniques like DP-SGD rely on the loss function's decomposability into per-sample contributions. However, rate constraints introduce inter-sample dependencies, violating the decomposability requirement. To address this, we develop RaCO-DP, a DP variant of the Stochastic Gradient Descent-Ascent (SGDA) algorithm which solves the Lagrangian formulation of rate constraint problems. We demonstrate that the additional privacy cost of incorporating these constraints reduces to privately estimating a histogram over the mini-batch at each optimization step. We prove the convergence of our algorithm through a novel analysis of SGDA that leverages the linear structure of the dual parameter. Finally, empirical results on learning under group fairness constraints demonstrate that our method Pareto-dominates existing private learning approaches in fairness-utility trade-offs.
Suitability Filter: A Statistical Framework for Classifier Evaluation in Real-World Deployment Settings
May 28, 2025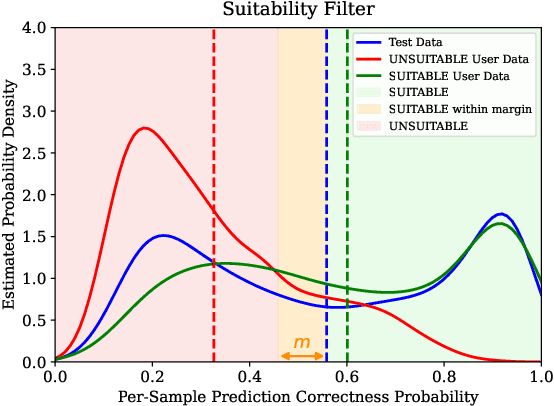
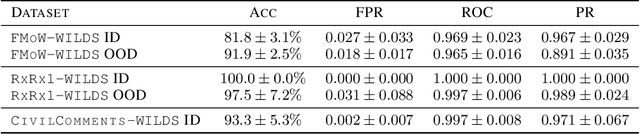
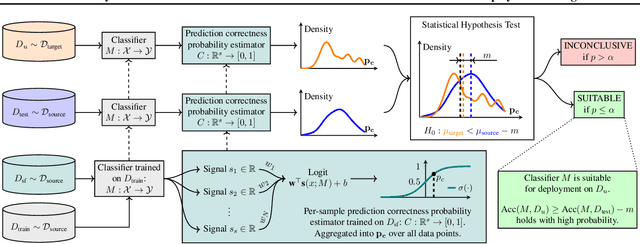
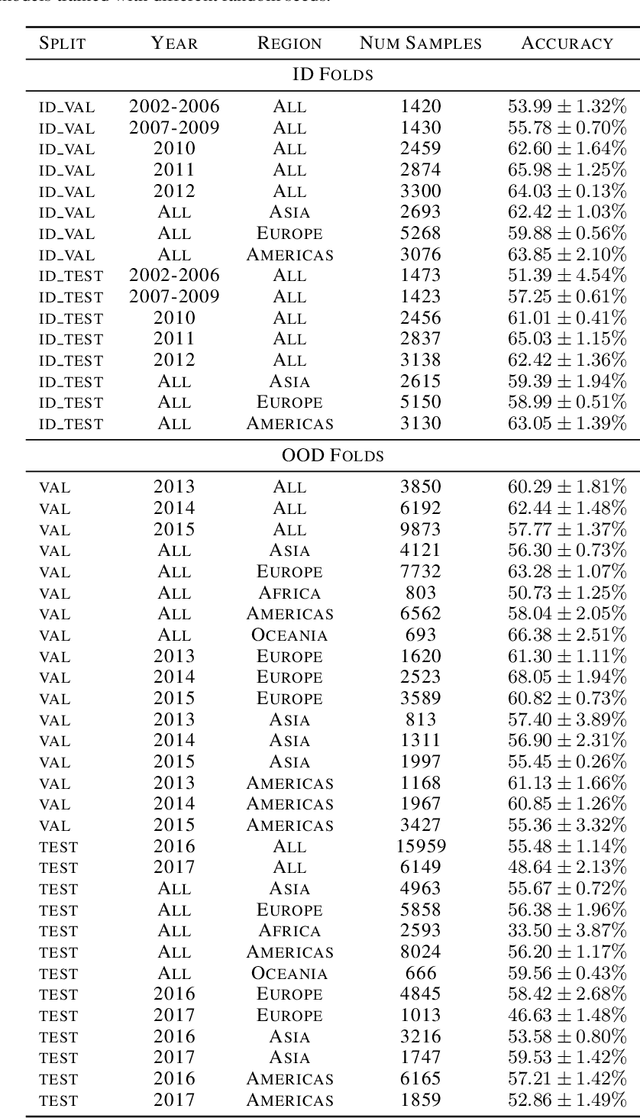
Deploying machine learning models in safety-critical domains poses a key challenge: ensuring reliable model performance on downstream user data without access to ground truth labels for direct validation. We propose the suitability filter, a novel framework designed to detect performance deterioration by utilizing suitability signals -- model output features that are sensitive to covariate shifts and indicative of potential prediction errors. The suitability filter evaluates whether classifier accuracy on unlabeled user data shows significant degradation compared to the accuracy measured on the labeled test dataset. Specifically, it ensures that this degradation does not exceed a pre-specified margin, which represents the maximum acceptable drop in accuracy. To achieve reliable performance evaluation, we aggregate suitability signals for both test and user data and compare these empirical distributions using statistical hypothesis testing, thus providing insights into decision uncertainty. Our modular method adapts to various models and domains. Empirical evaluations across different classification tasks demonstrate that the suitability filter reliably detects performance deviations due to covariate shift. This enables proactive mitigation of potential failures in high-stakes applications.
Leveraging Per-Instance Privacy for Machine Unlearning
May 24, 2025We present a principled, per-instance approach to quantifying the difficulty of unlearning via fine-tuning. We begin by sharpening an analysis of noisy gradient descent for unlearning (Chien et al., 2024), obtaining a better utility-unlearning tradeoff by replacing worst-case privacy loss bounds with per-instance privacy losses (Thudi et al., 2024), each of which bounds the (Renyi) divergence to retraining without an individual data point. To demonstrate the practical applicability of our theory, we present empirical results showing that our theoretical predictions are born out both for Stochastic Gradient Langevin Dynamics (SGLD) as well as for standard fine-tuning without explicit noise. We further demonstrate that per-instance privacy losses correlate well with several existing data difficulty metrics, while also identifying harder groups of data points, and introduce novel evaluation methods based on loss barriers. All together, our findings provide a foundation for more efficient and adaptive unlearning strategies tailored to the unique properties of individual data points.
Pr$εε$mpt: Sanitizing Sensitive Prompts for LLMs
Apr 07, 2025The rise of large language models (LLMs) has introduced new privacy challenges, particularly during inference where sensitive information in prompts may be exposed to proprietary LLM APIs. In this paper, we address the problem of formally protecting the sensitive information contained in a prompt while maintaining response quality. To this end, first, we introduce a cryptographically inspired notion of a prompt sanitizer which transforms an input prompt to protect its sensitive tokens. Second, we propose Pr$\epsilon\epsilon$mpt, a novel system that implements a prompt sanitizer. Pr$\epsilon\epsilon$mpt categorizes sensitive tokens into two types: (1) those where the LLM's response depends solely on the format (such as SSNs, credit card numbers), for which we use format-preserving encryption (FPE); and (2) those where the response depends on specific values, (such as age, salary) for which we apply metric differential privacy (mDP). Our evaluation demonstrates that Pr$\epsilon\epsilon$mpt is a practical method to achieve meaningful privacy guarantees, while maintaining high utility compared to unsanitized prompts, and outperforming prior methods
Backdoor Detection through Replicated Execution of Outsourced Training
Mar 31, 2025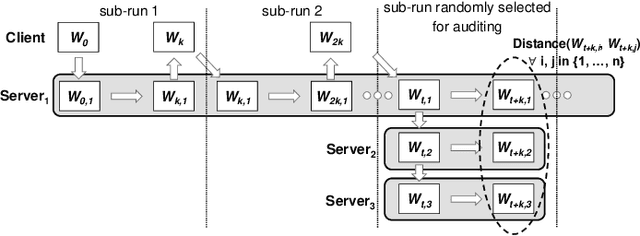
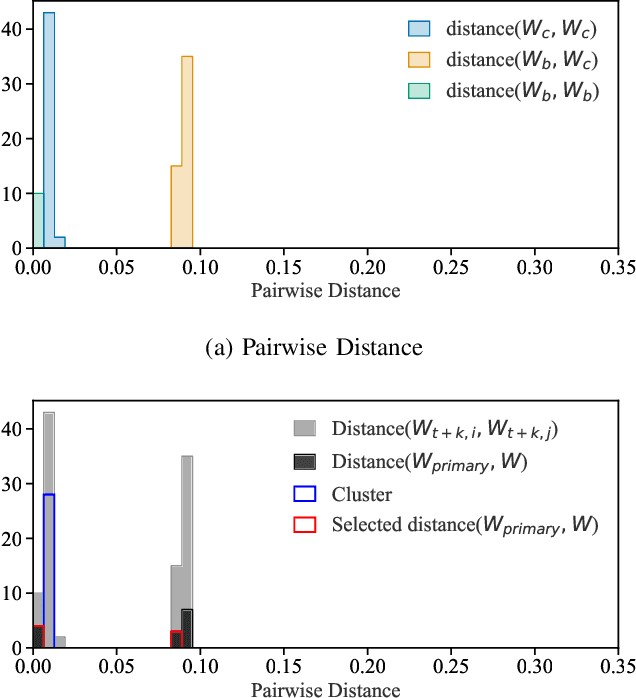
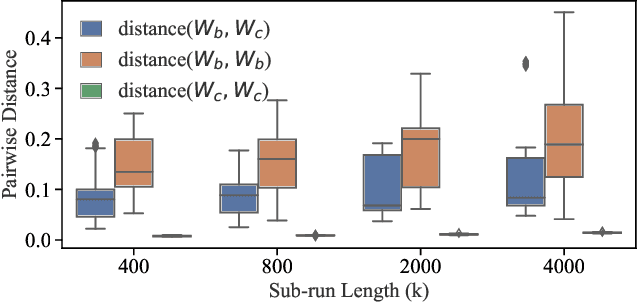
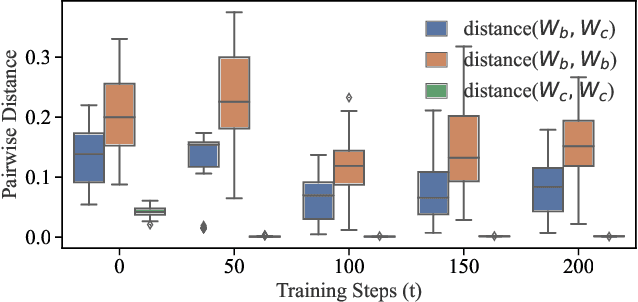
It is common practice to outsource the training of machine learning models to cloud providers. Clients who do so gain from the cloud's economies of scale, but implicitly assume trust: the server should not deviate from the client's training procedure. A malicious server may, for instance, seek to insert backdoors in the model. Detecting a backdoored model without prior knowledge of both the backdoor attack and its accompanying trigger remains a challenging problem. In this paper, we show that a client with access to multiple cloud providers can replicate a subset of training steps across multiple servers to detect deviation from the training procedure in a similar manner to differential testing. Assuming some cloud-provided servers are benign, we identify malicious servers by the substantial difference between model updates required for backdooring and those resulting from clean training. Perhaps the strongest advantage of our approach is its suitability to clients that have limited-to-no local compute capability to perform training; we leverage the existence of multiple cloud providers to identify malicious updates without expensive human labeling or heavy computation. We demonstrate the capabilities of our approach on an outsourced supervised learning task where $50\%$ of the cloud providers insert their own backdoor; our approach is able to correctly identify $99.6\%$ of them. In essence, our approach is successful because it replaces the signature-based paradigm taken by existing approaches with an anomaly-based detection paradigm. Furthermore, our approach is robust to several attacks from adaptive adversaries utilizing knowledge of our detection scheme.
Machine Unlearning Doesn't Do What You Think: Lessons for Generative AI Policy, Research, and Practice
Dec 09, 2024



We articulate fundamental mismatches between technical methods for machine unlearning in Generative AI, and documented aspirations for broader impact that these methods could have for law and policy. These aspirations are both numerous and varied, motivated by issues that pertain to privacy, copyright, safety, and more. For example, unlearning is often invoked as a solution for removing the effects of targeted information from a generative-AI model's parameters, e.g., a particular individual's personal data or in-copyright expression of Spiderman that was included in the model's training data. Unlearning is also proposed as a way to prevent a model from generating targeted types of information in its outputs, e.g., generations that closely resemble a particular individual's data or reflect the concept of "Spiderman." Both of these goals--the targeted removal of information from a model and the targeted suppression of information from a model's outputs--present various technical and substantive challenges. We provide a framework for thinking rigorously about these challenges, which enables us to be clear about why unlearning is not a general-purpose solution for circumscribing generative-AI model behavior in service of broader positive impact. We aim for conceptual clarity and to encourage more thoughtful communication among machine learning (ML), law, and policy experts who seek to develop and apply technical methods for compliance with policy objectives.