 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLumberjack: Better Differentially Private Random Forests through Heavy Hitter Detection in Trees
May 21, 2026Random forests are widely used in fields involving sensitive tabular data, but existing approaches to enforcing differential privacy (DP) typically degrade performance to the point of impracticality. In this paper, we introduce Lumberjack, a differentially private random forest algorithm that achieves substantially higher utility by constructing large random decision trees and then applying aggressive, privacy-preserving pruning to retain only sufficiently populated nodes. A key component of our approach is a novel $(\varepsilon,δ)$-DP heavy hitter detection algorithm for hierarchical data, whose error is $O_{\varepsilon,δ}(\sqrt{\log h})$ for trees of height $h$ and may be of independent interest. This favorable scaling enables the use of significantly deeper trees than in prior work, leading to improved expressiveness under privacy constraints. Our empirical evaluation on benchmark datasets shows that Lumberjack consistently outperforms prior DP random forest methods, establishing a new state of the art. In particular, our approach yields substantial improvements in the privacy-utility trade-off for practical privacy budgets. Our findings suggest that carefully designed DP random forests can close much of the utility gap, highlighting a promising and underexplored direction for future research.
Membership Inference Attacks from Causal Principles
Feb 02, 2026Membership Inference Attacks (MIAs) are widely used to quantify training data memorization and assess privacy risks. Standard evaluation requires repeated retraining, which is computationally costly for large models. One-run methods (single training with randomized data inclusion) and zero-run methods (post hoc evaluation) are often used instead, though their statistical validity remains unclear. To address this gap, we frame MIA evaluation as a causal inference problem, defining memorization as the causal effect of including a data point in the training set. This novel formulation reveals and formalizes key sources of bias in existing protocols: one-run methods suffer from interference between jointly included points, while zero-run evaluations popular for LLMs are confounded by non-random membership assignment. We derive causal analogues of standard MIA metrics and propose practical estimators for multi-run, one-run, and zero-run regimes with non-asymptotic consistency guarantees. Experiments on real-world data show that our approach enables reliable memorization measurement even when retraining is impractical and under distribution shift, providing a principled foundation for privacy evaluation in modern AI systems.
Private Rate-Constrained Optimization with Applications to Fair Learning
May 28, 2025



Many problems in trustworthy ML can be formulated as minimization of the model error under constraints on the prediction rates of the model for suitably-chosen marginals, including most group fairness constraints (demographic parity, equality of odds, etc.). In this work, we study such constrained minimization problems under differential privacy (DP). Standard DP optimization techniques like DP-SGD rely on the loss function's decomposability into per-sample contributions. However, rate constraints introduce inter-sample dependencies, violating the decomposability requirement. To address this, we develop RaCO-DP, a DP variant of the Stochastic Gradient Descent-Ascent (SGDA) algorithm which solves the Lagrangian formulation of rate constraint problems. We demonstrate that the additional privacy cost of incorporating these constraints reduces to privately estimating a histogram over the mini-batch at each optimization step. We prove the convergence of our algorithm through a novel analysis of SGDA that leverages the linear structure of the dual parameter. Finally, empirical results on learning under group fairness constraints demonstrate that our method Pareto-dominates existing private learning approaches in fairness-utility trade-offs.
Tighter Privacy Auditing of DP-SGD in the Hidden State Threat Model
May 23, 2024



Machine learning models can be trained with formal privacy guarantees via differentially private optimizers such as DP-SGD. In this work, we study such privacy guarantees when the adversary only accesses the final model, i.e., intermediate model updates are not released. In the existing literature, this hidden state threat model exhibits a significant gap between the lower bound provided by empirical privacy auditing and the theoretical upper bound provided by privacy accounting. To challenge this gap, we propose to audit this threat model with adversaries that craft a gradient sequence to maximize the privacy loss of the final model without accessing intermediate models. We demonstrate experimentally how this approach consistently outperforms prior attempts at auditing the hidden state model. When the crafted gradient is inserted at every optimization step, our results imply that releasing only the final model does not amplify privacy, providing a novel negative result. On the other hand, when the crafted gradient is not inserted at every step, we show strong evidence that a privacy amplification phenomenon emerges in the general non-convex setting (albeit weaker than in convex regimes), suggesting that existing privacy upper bounds can be improved.
Syft 0.5: A Platform for Universally Deployable Structured Transparency
Apr 27, 2021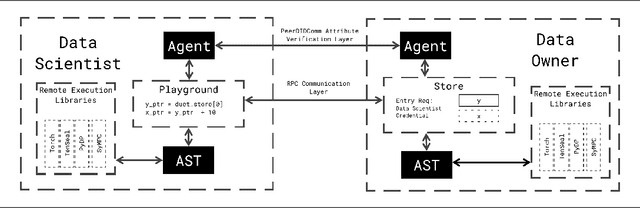
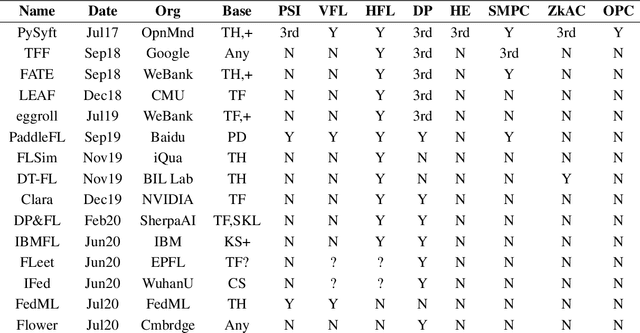
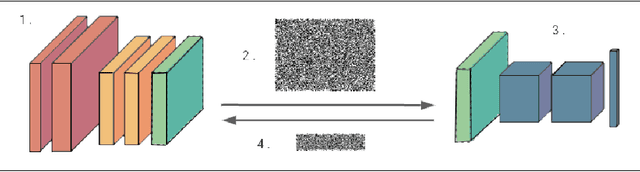
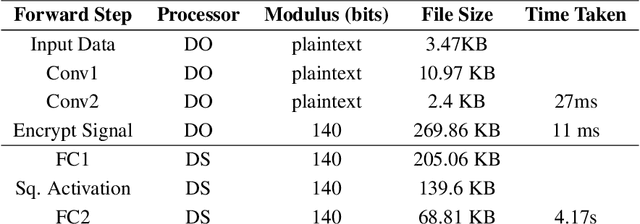
We present Syft 0.5, a general-purpose framework that combines a core group of privacy-enhancing technologies that facilitate a universal set of structured transparency systems. This framework is demonstrated through the design and implementation of a novel privacy-preserving inference information flow where we pass homomorphically encrypted activation signals through a split neural network for inference. We show that splitting the model further up the computation chain significantly reduces the computation time of inference and the payload size of activation signals at the cost of model secrecy. We evaluate our proposed flow with respect to its provision of the core structural transparency principles.
PyVertical: A Vertical Federated Learning Framework for Multi-headed SplitNN
Apr 14, 2021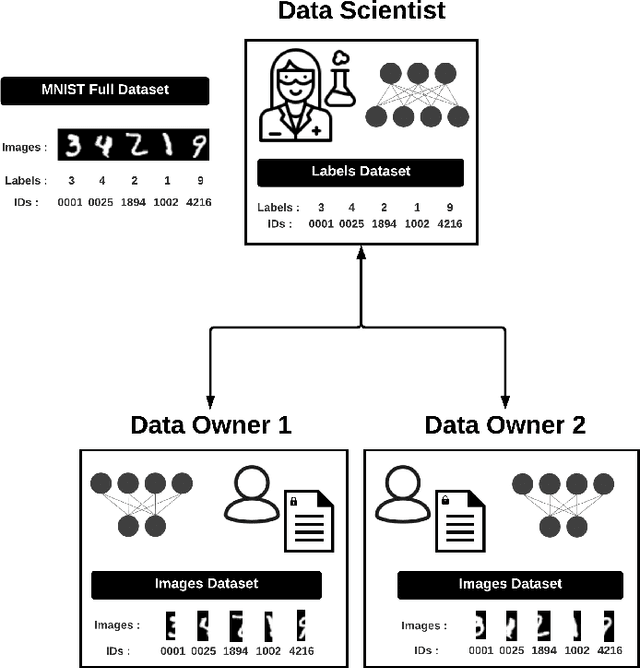
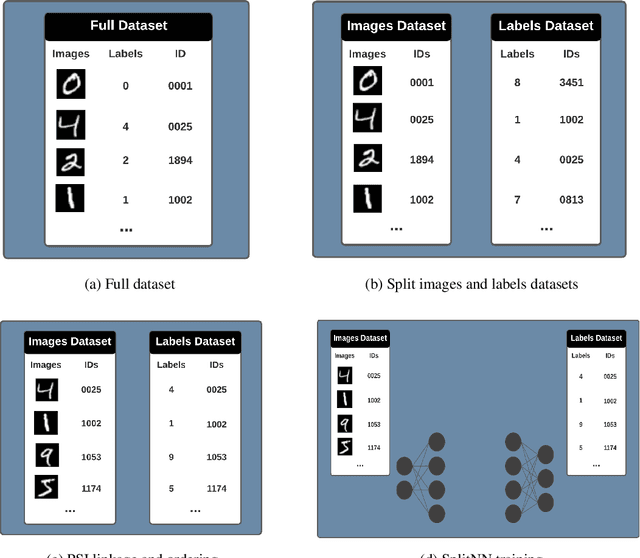
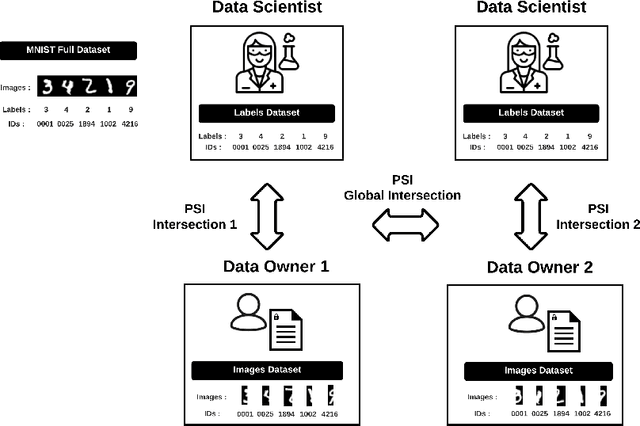
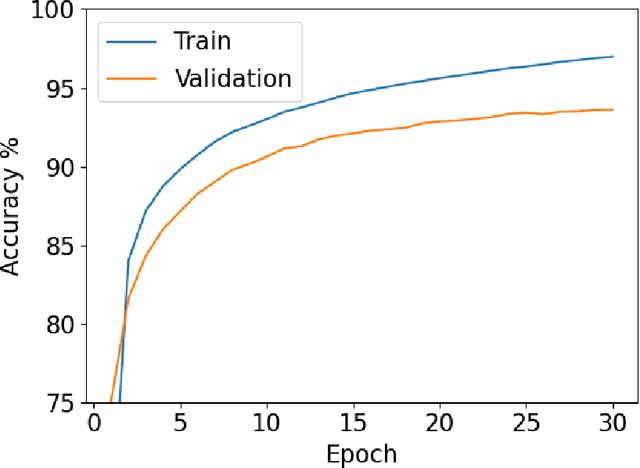
We introduce PyVertical, a framework supporting vertical federated learning using split neural networks. The proposed framework allows a data scientist to train neural networks on data features vertically partitioned across multiple owners while keeping raw data on an owner's device. To link entities shared across different datasets' partitions, we use Private Set Intersection on IDs associated with data points. To demonstrate the validity of the proposed framework, we present the training of a simple dual-headed split neural network for a MNIST classification task, with data samples vertically distributed across two data owners and a data scientist.