 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurvivalGAN: Generating Time-to-Event Data for Survival Analysis
Feb 24, 2023



Synthetic data is becoming an increasingly promising technology, and successful applications can improve privacy, fairness, and data democratization. While there are many methods for generating synthetic tabular data, the task remains non-trivial and unexplored for specific scenarios. One such scenario is survival data. Here, the key difficulty is censoring: for some instances, we are not aware of the time of event, or if one even occurred. Imbalances in censoring and time horizons cause generative models to experience three new failure modes specific to survival analysis: (1) generating too few at-risk members; (2) generating too many at-risk members; and (3) censoring too early. We formalize these failure modes and provide three new generative metrics to quantify them. Following this, we propose SurvivalGAN, a generative model that handles survival data firstly by addressing the imbalance in the censoring and event horizons, and secondly by using a dedicated mechanism for approximating time-to-event/censoring. We evaluate this method via extensive experiments on medical datasets. SurvivalGAN outperforms multiple baselines at generating survival data, and in particular addresses the failure modes as measured by the new metrics, in addition to improving downstream performance of survival models trained on the synthetic data.
HyperImpute: Generalized Iterative Imputation with Automatic Model Selection
Jun 15, 2022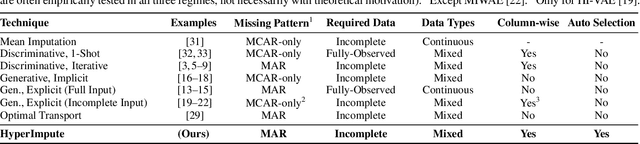

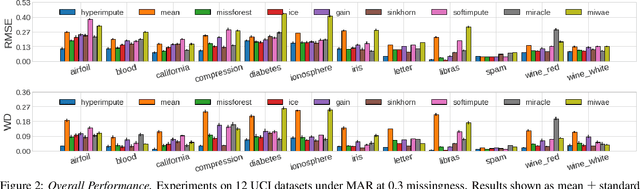
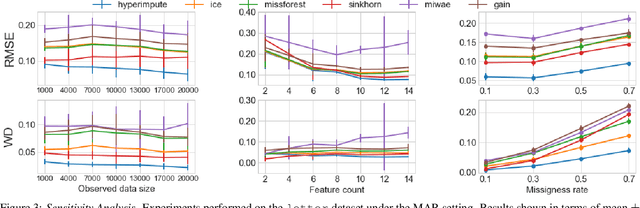
Consider the problem of imputing missing values in a dataset. One the one hand, conventional approaches using iterative imputation benefit from the simplicity and customizability of learning conditional distributions directly, but suffer from the practical requirement for appropriate model specification of each and every variable. On the other hand, recent methods using deep generative modeling benefit from the capacity and efficiency of learning with neural network function approximators, but are often difficult to optimize and rely on stronger data assumptions. In this work, we study an approach that marries the advantages of both: We propose *HyperImpute*, a generalized iterative imputation framework for adaptively and automatically configuring column-wise models and their hyperparameters. Practically, we provide a concrete implementation with out-of-the-box learners, optimizers, simulators, and extensible interfaces. Empirically, we investigate this framework via comprehensive experiments and sensitivities on a variety of public datasets, and demonstrate its ability to generate accurate imputations relative to a strong suite of benchmarks. Contrary to recent work, we believe our findings constitute a strong defense of the iterative imputation paradigm.
TenSEAL: A Library for Encrypted Tensor Operations Using Homomorphic Encryption
Apr 28, 2021



Machine learning algorithms have achieved remarkable results and are widely applied in a variety of domains. These algorithms often rely on sensitive and private data such as medical and financial records. Therefore, it is vital to draw further attention regarding privacy threats and corresponding defensive techniques applied to machine learning models. In this paper, we present TenSEAL, an open-source library for Privacy-Preserving Machine Learning using Homomorphic Encryption that can be easily integrated within popular machine learning frameworks. We benchmark our implementation using MNIST and show that an encrypted convolutional neural network can be evaluated in less than a second, using less than half a megabyte of communication.
Syft 0.5: A Platform for Universally Deployable Structured Transparency
Apr 27, 2021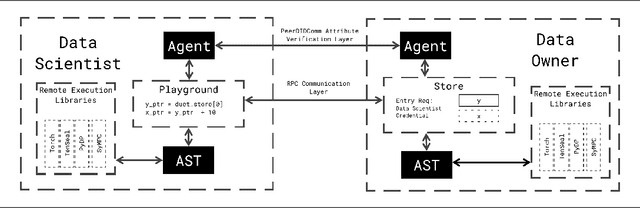
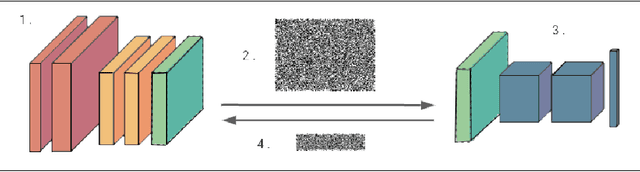
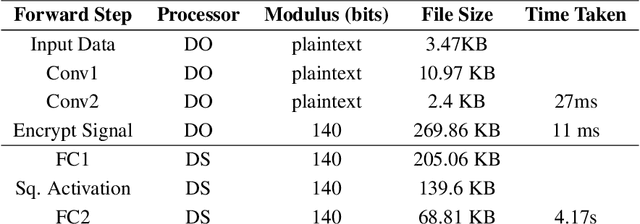
We present Syft 0.5, a general-purpose framework that combines a core group of privacy-enhancing technologies that facilitate a universal set of structured transparency systems. This framework is demonstrated through the design and implementation of a novel privacy-preserving inference information flow where we pass homomorphically encrypted activation signals through a split neural network for inference. We show that splitting the model further up the computation chain significantly reduces the computation time of inference and the payload size of activation signals at the cost of model secrecy. We evaluate our proposed flow with respect to its provision of the core structural transparency principles.
Asymmetric Private Set Intersection with Applications to Contact Tracing and Private Vertical Federated Machine Learning
Nov 18, 2020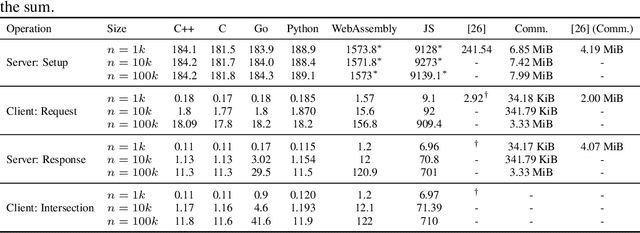
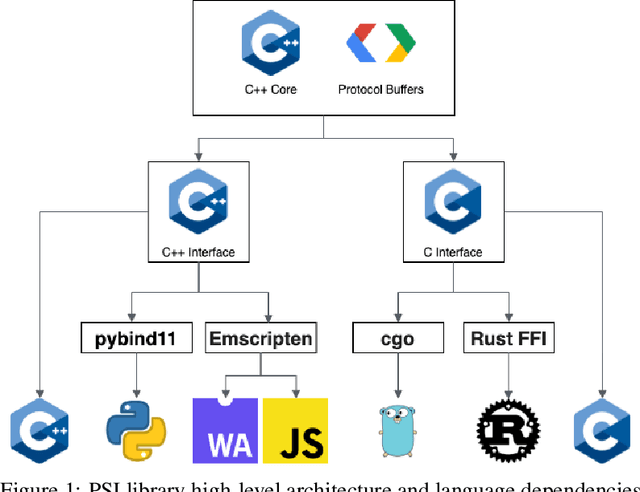
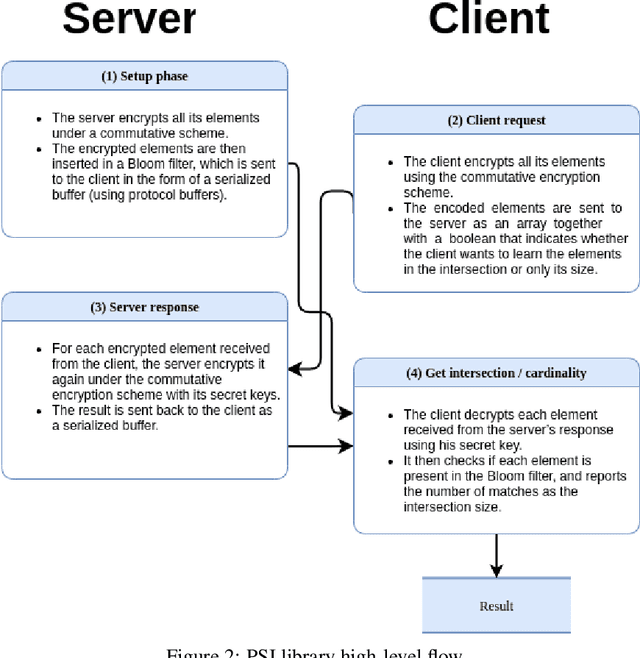

We present a multi-language, cross-platform, open-source library for asymmetric private set intersection (PSI) and PSI-Cardinality (PSI-C). Our protocol combines traditional DDH-based PSI and PSI-C protocols with compression based on Bloom filters that helps reduce communication in the asymmetric setting. Currently, our library supports C++, C, Go, WebAssembly, JavaScript, Python, and Rust, and runs on both traditional hardware (x86) and browser targets. We further apply our library to two use cases: (i) a privacy-preserving contact tracing protocol that is compatible with existing approaches, but improves their privacy guarantees, and (ii) privacy-preserving machine learning on vertically partitioned data.