 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Common Substructures Transferable? Riemannian Graph Foundation Model with Neural Vector Bundles
Jun 02, 2026Foundation models have sparked a revolution via a pretraining-adaptation paradigm, with recent efforts extending this success to graphs. Unlike other modalities, graphs contain rich structural patterns, yet their structural transferability remains poorly understood. Prior studies consider common substructures in the discrete realm, and we are motivated by a fundamental question: Are common substructures transferable? The underlying theory is largely underexplored. In this work, we shift toward learning transferable structures through the lens of functional behavior. Theoretically, we connect transferable substructures to intrinsic geometry of the representation space. However, characterizing such intrinsic geometry has rarely been touched. Grounded in Riemannian geometry, we develop a graph intrinsic geometry learning framework called Neural Vector Bundle, which enables parsing intrinsic geometry with local coordinates. Building on this, we design GAUGE, a pretrainable neural architecture that constructs the vector bundle, flattening geometrically compatible local coordinates, and a new Dirichlet loss, which also measures the transfer effort. We empirically validate its superior expressiveness in challenging tasks including zero-shot link prediction and graph isomorphism.
Concept Graph Convolutions: Message Passing in the Concept Space
Apr 22, 2026The trust in the predictions of Graph Neural Networks is limited by their opaque reasoning process. Prior methods have tried to explain graph networks via concept-based explanations extracted from the latent representations obtained after message passing. However, these explanations fall short of explaining the message passing process itself. To this aim, we propose the Concept Graph Convolution, the first graph convolution designed to operate on node-level concepts for improved interpretability. The proposed convolutional layer performs message passing on a combination of raw and concept representations using structural and attention-based edge weights. We also propose a pure variant of the convolution, only operating in the concept space. Our results show that the Concept Graph Convolution allows to obtain competitive task accuracy, while enabling an increased insight into the evolution of concepts across convolutional steps.
Subgraph Concept Networks: Concept Levels in Graph Classification
Apr 20, 2026The reasoning process of Graph Neural Networks is complex and considered opaque, limiting trust in their predictions. To alleviate this issue, prior work has proposed concept-based explanations, extracted from clusters in the model's node embeddings. However, a limitation of concept-based explanations is that they only explain the node embedding space and are obscured by pooling in graph classification. To mitigate this issue and provide a deeper level of understanding, we propose the Subgraph Concept Network. The Subgraph Concept Network is the first graph neural network architecture that distils subgraph and graph-level concepts. It achieves this by performing soft clustering on node concept embeddings to derive subgraph and graph-level concepts. Our results show that the Subgraph Concept Network allows to obtain competitive model accuracy, while discovering meaningful concepts at different levels of the network.
Zatom-1: A Multimodal Flow Foundation Model for 3D Molecules and Materials
Feb 24, 2026General-purpose 3D chemical modeling encompasses molecules and materials, requiring both generative and predictive capabilities. However, most existing AI approaches are optimized for a single domain (molecules or materials) and a single task (generation or prediction), which limits representation sharing and transfer. We introduce Zatom-1, the first foundation model that unifies generative and predictive learning of 3D molecules and materials. Zatom-1 is a Transformer trained with a multimodal flow matching objective that jointly models discrete atom types and continuous 3D geometries. This approach supports scalable pretraining with predictable gains as model capacity increases, while enabling fast and stable sampling. We use joint generative pretraining as a universal initialization for downstream multi-task prediction of properties, energies, and forces. Empirically, Zatom-1 matches or outperforms specialized baselines on both generative and predictive benchmarks, while reducing the generative inference time by more than an order of magnitude. Our experiments demonstrate positive predictive transfer between chemical domains from joint generative pretraining: modeling materials during pretraining improves molecular property prediction accuracy.
Pairwise is Not Enough: Hypergraph Neural Networks for Multi-Agent Pathfinding
Feb 06, 2026Multi-Agent Path Finding (MAPF) is a representative multi-agent coordination problem, where multiple agents are required to navigate to their respective goals without collisions. Solving MAPF optimally is known to be NP-hard, leading to the adoption of learning-based approaches to alleviate the online computational burden. Prevailing approaches, such as Graph Neural Networks (GNNs), are typically constrained to pairwise message passing between agents. However, this limitation leads to suboptimal behaviours and critical issues, such as attention dilution, particularly in dense environments where group (i.e. beyond just two agents) coordination is most critical. Despite the importance of such higher-order interactions, existing approaches have not been able to fully explore them. To address this representational bottleneck, we introduce HMAGAT (Hypergraph Multi-Agent Attention Network), a novel architecture that leverages attentional mechanisms over directed hypergraphs to explicitly capture group dynamics. Empirically, HMAGAT establishes a new state-of-the-art among learning-based MAPF solvers: e.g., despite having just 1M parameters and being trained on 100$\times$ less data, it outperforms the current SoTA 85M parameter model. Through detailed analysis of HMAGAT's attention values, we demonstrate how hypergraph representations mitigate the attention dilution inherent in GNNs and capture complex interactions where pairwise methods fail. Our results illustrate that appropriate inductive biases are often more critical than the training data size or sheer parameter count for multi-agent problems.
Molecular Representations in Implicit Functional Space via Hyper-Networks
Jan 29, 2026Molecular representations fundamentally shape how machine learning systems reason about molecular structure and physical properties. Most existing approaches adopt a discrete pipeline: molecules are encoded as sequences, graphs, or point clouds, mapped to fixed-dimensional embeddings, and then used for task-specific prediction. This paradigm treats molecules as discrete objects, despite their intrinsically continuous and field-like physical nature. We argue that molecular learning can instead be formulated as learning in function space. Specifically, we model each molecule as a continuous function over three-dimensional (3D) space and treat this molecular field as the primary object of representation. From this perspective, conventional molecular representations arise as particular sampling schemes of an underlying continuous object. We instantiate this formulation with MolField, a hyper-network-based framework that learns distributions over molecular fields. To ensure physical consistency, these functions are defined over canonicalized coordinates, yielding invariance to global SE(3) transformations. To enable learning directly over functions, we introduce a structured weight tokenization and train a sequence-based hyper-network to model a shared prior over molecular fields. We evaluate MolField on molecular dynamics and property prediction. Our results show that treating molecules as continuous functions fundamentally changes how molecular representations generalize across tasks and yields downstream behavior that is stable to how molecules are discretized or queried.
A Monosemantic Attribution Framework for Stable Interpretability in Clinical Neuroscience Large Language Models
Jan 25, 2026Interpretability remains a key challenge for deploying large language models (LLMs) in clinical settings such as Alzheimer's disease progression diagnosis, where early and trustworthy predictions are essential. Existing attribution methods exhibit high inter-method variability and unstable explanations due to the polysemantic nature of LLM representations, while mechanistic interpretability approaches lack direct alignment with model inputs and outputs and do not provide explicit importance scores. We introduce a unified interpretability framework that integrates attributional and mechanistic perspectives through monosemantic feature extraction. By constructing a monosemantic embedding space at the level of an LLM layer and optimizing the framework to explicitly reduce inter-method variability, our approach produces stable input-level importance scores and highlights salient features via a decompressed representation of the layer of interest, advancing the safe and trustworthy application of LLMs in cognitive health and neurodegenerative disease.
MODE: Efficient Time Series Prediction with Mamba Enhanced by Low-Rank Neural ODEs
Jan 01, 2026Time series prediction plays a pivotal role across diverse domains such as finance, healthcare, energy systems, and environmental modeling. However, existing approaches often struggle to balance efficiency, scalability, and accuracy, particularly when handling long-range dependencies and irregularly sampled data. To address these challenges, we propose MODE, a unified framework that integrates Low-Rank Neural Ordinary Differential Equations (Neural ODEs) with an Enhanced Mamba architecture. As illustrated in our framework, the input sequence is first transformed by a Linear Tokenization Layer and then processed through multiple Mamba Encoder blocks, each equipped with an Enhanced Mamba Layer that employs Causal Convolution, SiLU activation, and a Low-Rank Neural ODE enhancement to efficiently capture temporal dynamics. This low-rank formulation reduces computational overhead while maintaining expressive power. Furthermore, a segmented selective scanning mechanism, inspired by pseudo-ODE dynamics, adaptively focuses on salient subsequences to improve scalability and long-range sequence modeling. Extensive experiments on benchmark datasets demonstrate that MODE surpasses existing baselines in both predictive accuracy and computational efficiency. Overall, our contributions include: (1) a unified and efficient architecture for long-term time series modeling, (2) integration of Mamba's selective scanning with low-rank Neural ODEs for enhanced temporal representation, and (3) substantial improvements in efficiency and scalability enabled by low-rank approximation and dynamic selective scanning.
Deep Spectral Prior
May 26, 2025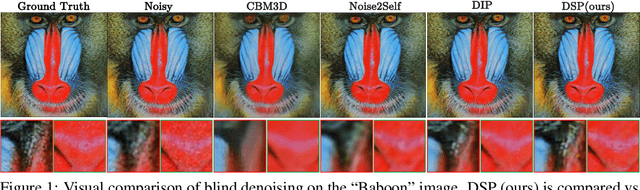
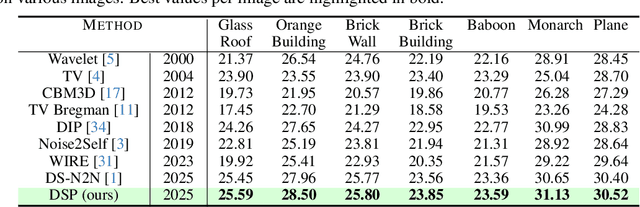


We introduce Deep Spectral Prior (DSP), a new formulation of Deep Image Prior (DIP) that redefines image reconstruction as a frequency-domain alignment problem. Unlike traditional DIP, which relies on pixel-wise loss and early stopping to mitigate overfitting, DSP directly matches Fourier coefficients between the network output and observed measurements. This shift introduces an explicit inductive bias towards spectral coherence, aligning with the known frequency structure of images and the spectral bias of convolutional neural networks. We provide a rigorous theoretical framework demonstrating that DSP acts as an implicit spectral regulariser, suppressing high-frequency noise by design and eliminating the need for early stopping. Our analysis spans four core dimensions establishing smooth convergence dynamics, local stability, and favourable bias-variance tradeoffs. We further show that DSP naturally projects reconstructions onto a frequency-consistent manifold, enhancing interpretability and robustness. These theoretical guarantees are supported by empirical results across denoising, inpainting, and super-resolution tasks, where DSP consistently outperforms classical DIP and other unsupervised baselines.
How Particle System Theory Enhances Hypergraph Message Passing
May 24, 2025Hypergraphs effectively model higher-order relationships in natural phenomena, capturing complex interactions beyond pairwise connections. We introduce a novel hypergraph message passing framework inspired by interacting particle systems, where hyperedges act as fields inducing shared node dynamics. By incorporating attraction, repulsion, and Allen-Cahn forcing terms, particles of varying classes and features achieve class-dependent equilibrium, enabling separability through the particle-driven message passing. We investigate both first-order and second-order particle system equations for modeling these dynamics, which mitigate over-smoothing and heterophily thus can capture complete interactions. The more stable second-order system permits deeper message passing. Furthermore, we enhance deterministic message passing with stochastic element to account for interaction uncertainties. We prove theoretically that our approach mitigates over-smoothing by maintaining a positive lower bound on the hypergraph Dirichlet energy during propagation and thus to enable hypergraph message passing to go deep. Empirically, our models demonstrate competitive performance on diverse real-world hypergraph node classification tasks, excelling on both homophilic and heterophilic datasets.