 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Channel Closures in the Lightning Network with Machine Learning
May 12, 2026The Lightning Network (LN) is a second-layer protocol for Bitcoin designed to enable fast and cost-efficient off-chain transactions. Channels in the LN can be closed either by mutual agreement or unilaterally through a forced closure, which locks the involved capital for an extended period and degrades network reliability. In this paper, we study the problem of predicting channel closure types from publicly available gossip data, framing it as a temporal link classification task over the evolving channel graph. We construct a dataset spanning over two years of LN activity and benchmark a range of machine learning approaches, from MLPs to temporal graph neural networks and spectral encodings. Our experiments reveal that the dominant predictive signals are temporal and behavioural, namely how recently each endpoint was active and the per-node history of past closures, while the surrounding network topology provides no additional benefit. We find that a simple MLP operating on edge-level features, node-level event counts, and temporal patterns outperforms all graph-based approaches, and discuss how the inherent privacy of the LN, where critical information such as channel balances and payment flows remains hidden, fundamentally limits the predictability of closures from gossip data alone. We publicly release the dataset and code at https://github.com/AmbossTech/ln-channel-closure-prediction to encourage further research on this practically relevant task.
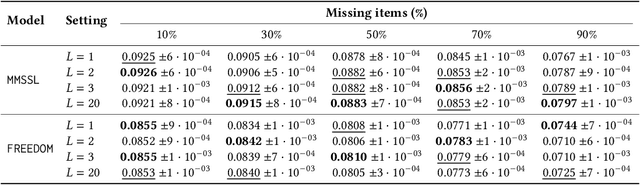
Training-free Graph-based Imputation of Missing Modalities in Multimodal Recommendation
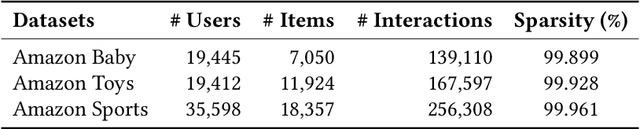
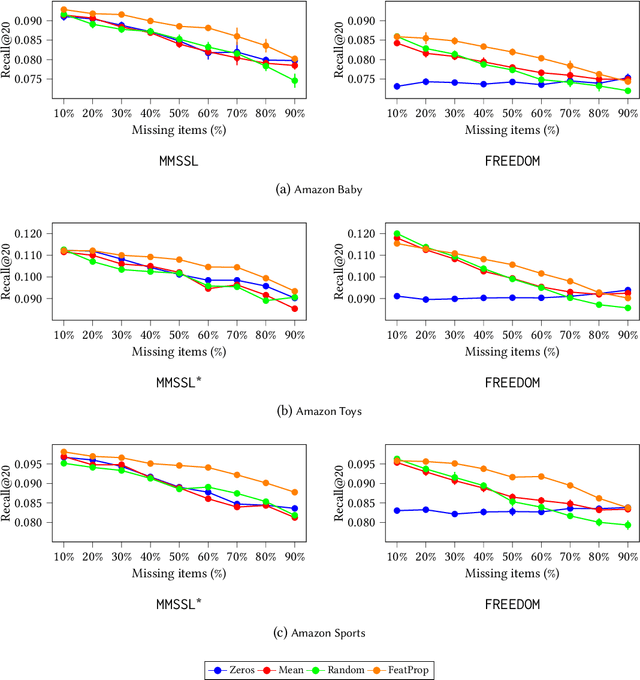
Feb 19, 2026Multimodal recommender systems (RSs) represent items in the catalog through multimodal data (e.g., product images and descriptions) that, in some cases, might be noisy or (even worse) missing. In those scenarios, the common practice is to drop items with missing modalities and train the multimodal RSs on a subsample of the original dataset. To date, the problem of missing modalities in multimodal recommendation has still received limited attention in the literature, lacking a precise formalisation as done with missing information in traditional machine learning. In this work, we first provide a problem formalisation for missing modalities in multimodal recommendation. Second, by leveraging the user-item graph structure, we re-cast the problem of missing multimodal information as a problem of graph features interpolation on the item-item co-purchase graph. On this basis, we propose four training-free approaches that propagate the available multimodal features throughout the item-item graph to impute the missing features. Extensive experiments on popular multimodal recommendation datasets demonstrate that our solutions can be seamlessly plugged into any existing multimodal RS and benchmarking framework while still preserving (or even widen) the performance gap between multimodal and traditional RSs. Moreover, we show that our graph-based techniques can perform better than traditional imputations in machine learning under different missing modalities settings. Finally, we analyse (for the first time in multimodal RSs) how feature homophily calculated on the item-item graph can influence our graph-based imputations.
Model Merging Improves Zero-Shot Generalization in Bioacoustic Foundation Models
Nov 19, 2025Foundation models capable of generalizing across species and tasks represent a promising new frontier in bioacoustics, with NatureLM being one of the most prominent examples. While its domain-specific fine-tuning yields strong performance on bioacoustic benchmarks, we observe that it also introduces trade-offs in instruction-following flexibility. For instance, NatureLM achieves high accuracy when prompted for either the common or scientific name individually, but its accuracy drops significantly when both are requested in a single prompt. We address this by applying a simple model merging strategy that interpolates NatureLM with its base language model, recovering instruction-following capabilities with minimal loss of domain expertise. Finally, we show that the merged model exhibits markedly stronger zero-shot generalization, achieving over a 200% relative improvement and setting a new state-of-the-art in closed-set zero-shot classification of unseen species.
Bayesian Binary Search
Oct 02, 2024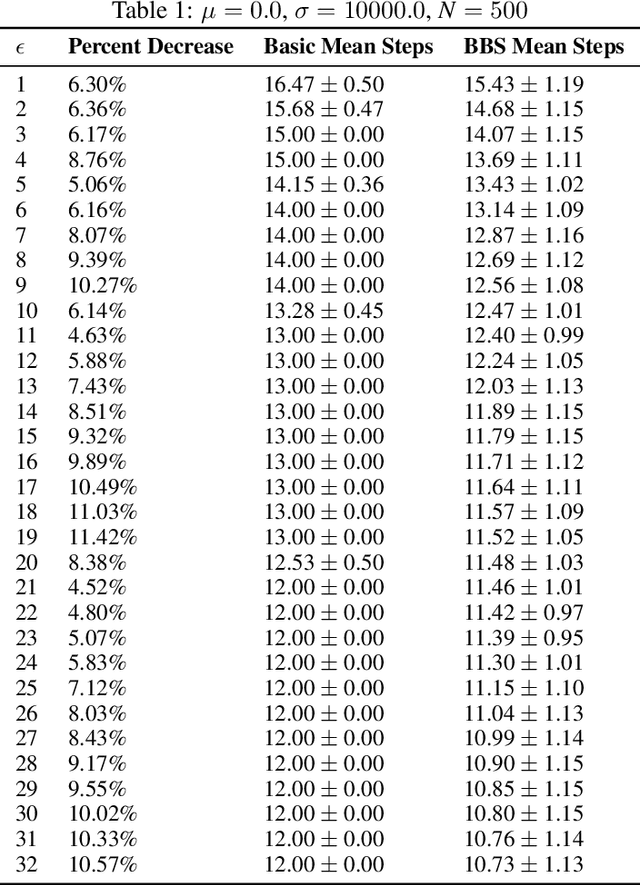
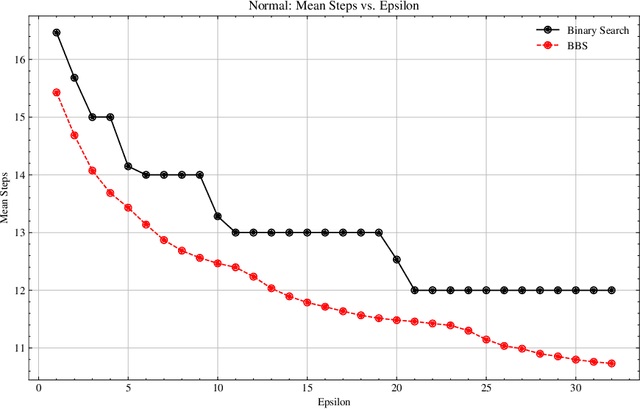

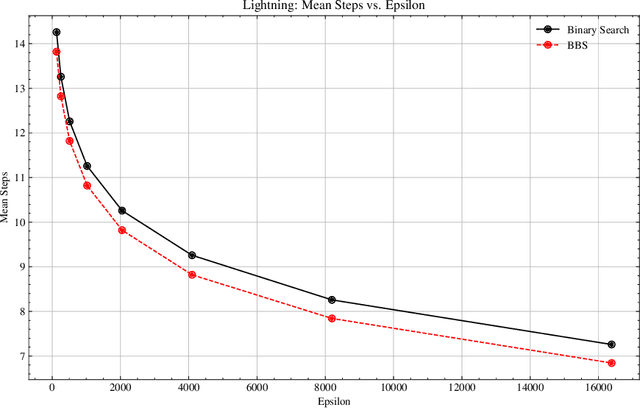
We present Bayesian Binary Search (BBS), a novel probabilistic variant of the classical binary search/bisection algorithm. BBS leverages machine learning/statistical techniques to estimate the probability density of the search space and modifies the bisection step to split based on probability density rather than the traditional midpoint, allowing for the learned distribution of the search space to guide the search algorithm. Search space density estimation can flexibly be performed using supervised probabilistic machine learning techniques (e.g., Gaussian process regression, Bayesian neural networks, quantile regression) or unsupervised learning algorithms (e.g., Gaussian mixture models, kernel density estimation (KDE), maximum likelihood estimation (MLE)). We demonstrate significant efficiency gains of using BBS on both simulated data across a variety of distributions and in a real-world binary search use case of probing channel balances in the Bitcoin Lightning Network, for which we have deployed the BBS algorithm in a production setting.
Do We Really Need to Drop Items with Missing Modalities in Multimodal Recommendation?
Aug 21, 2024
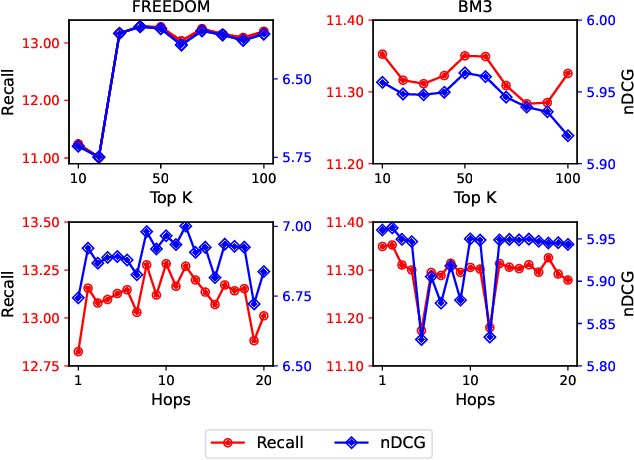
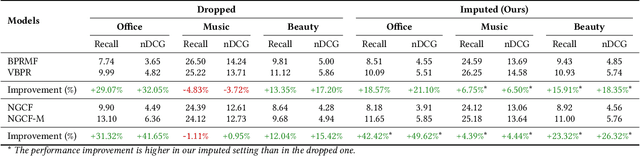
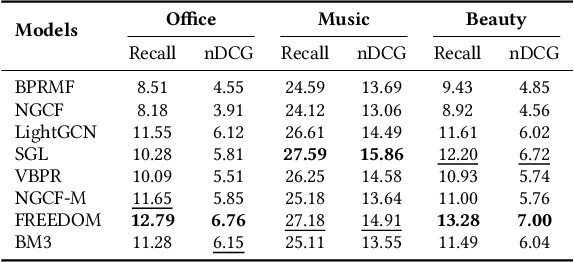
Generally, items with missing modalities are dropped in multimodal recommendation. However, with this work, we question this procedure, highlighting that it would further damage the pipeline of any multimodal recommender system. First, we show that the lack of (some) modalities is, in fact, a widely-diffused phenomenon in multimodal recommendation. Second, we propose a pipeline that imputes missing multimodal features in recommendation by leveraging traditional imputation strategies in machine learning. Then, given the graph structure of the recommendation data, we also propose three more effective imputation solutions that leverage the item-item co-purchase graph and the multimodal similarities of co-interacted items. Our method can be plugged into any multimodal RSs in the literature working as an untrained pre-processing phase, showing (through extensive experiments) that any data pre-filtering is not only unnecessary but also harmful to the performance.
UTG: Towards a Unified View of Snapshot and Event Based Models for Temporal Graphs
Jul 17, 2024



Temporal graphs have gained increasing importance due to their ability to model dynamically evolving relationships. These graphs can be represented through either a stream of edge events or a sequence of graph snapshots. Until now, the development of machine learning methods for both types has occurred largely in isolation, resulting in limited experimental comparison and theoretical crosspollination between the two. In this paper, we introduce Unified Temporal Graph (UTG), a framework that unifies snapshot-based and event-based machine learning models under a single umbrella, enabling models developed for one representation to be applied effectively to datasets of the other. We also propose a novel UTG training procedure to boost the performance of snapshot-based models in the streaming setting. We comprehensively evaluate both snapshot and event-based models across both types of temporal graphs on the temporal link prediction task. Our main findings are threefold: first, when combined with UTG training, snapshotbased models can perform competitively with event-based models such as TGN and GraphMixer even on event datasets. Second, snapshot-based models are at least an order of magnitude faster than most event-based models during inference. Third, while event-based methods such as NAT and DyGFormer outperforms snapshotbased methods on both types of temporal graphs, this is because they leverage joint neighborhood structural features thus emphasizing the potential to incorporate these features into snapshot-based models as well. These findings highlight the importance of comparing model architectures independent of the data format and suggest the potential of combining the efficiency of snapshot-based models with the performance of event-based models in the future.
TGB 2.0: A Benchmark for Learning on Temporal Knowledge Graphs and Heterogeneous Graphs
Jun 14, 2024Multi-relational temporal graphs are powerful tools for modeling real-world data, capturing the evolving and interconnected nature of entities over time. Recently, many novel models are proposed for ML on such graphs intensifying the need for robust evaluation and standardized benchmark datasets. However, the availability of such resources remains scarce and evaluation faces added complexity due to reproducibility issues in experimental protocols. To address these challenges, we introduce Temporal Graph Benchmark 2.0 (TGB 2.0), a novel benchmarking framework tailored for evaluating methods for predicting future links on Temporal Knowledge Graphs and Temporal Heterogeneous Graphs with a focus on large-scale datasets, extending the Temporal Graph Benchmark. TGB 2.0 facilitates comprehensive evaluations by presenting eight novel datasets spanning five domains with up to 53 million edges. TGB 2.0 datasets are significantly larger than existing datasets in terms of number of nodes, edges, or timestamps. In addition, TGB 2.0 provides a reproducible and realistic evaluation pipeline for multi-relational temporal graphs. Through extensive experimentation, we observe that 1) leveraging edge-type information is crucial to obtain high performance, 2) simple heuristic baselines are often competitive with more complex methods, 3) most methods fail to run on our largest datasets, highlighting the need for research on more scalable methods.
Channel Balance Interpolation in the Lightning Network via Machine Learning
May 20, 2024

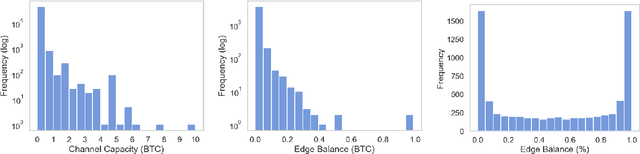
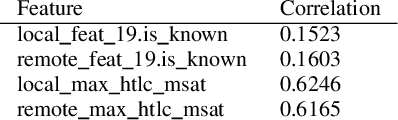
The Bitcoin Lightning Network is a Layer 2 payment protocol that addresses Bitcoin's scalability by facilitating quick and cost effective transactions through payment channels. This research explores the feasibility of using machine learning models to interpolate channel balances within the network, which can be used for optimizing the network's pathfinding algorithms. While there has been much exploration in balance probing and multipath payment protocols, predicting channel balances using solely node and channel features remains an uncharted area. This paper evaluates the performance of several machine learning models against two heuristic baselines and investigates the predictive capabilities of various features. Our model performs favorably in experimental evaluation, outperforming by 10% against an equal split baseline where both edges are assigned half of the channel capacity.
Dealing with Missing Modalities in Multimodal Recommendation: a Feature Propagation-based Approach
Mar 28, 2024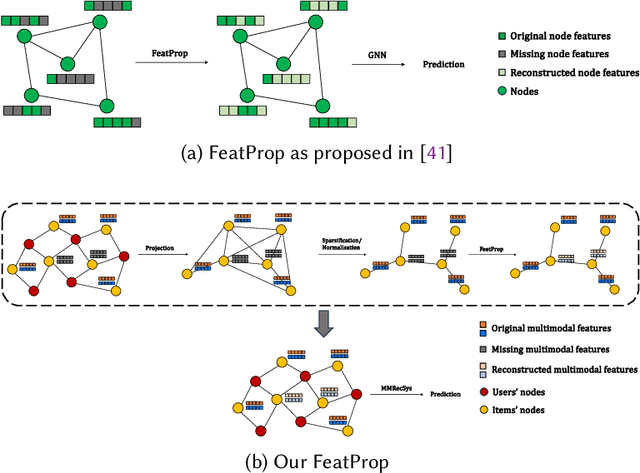
Multimodal recommender systems work by augmenting the representation of the products in the catalogue through multimodal features extracted from images, textual descriptions, or audio tracks characterising such products. Nevertheless, in real-world applications, only a limited percentage of products come with multimodal content to extract meaningful features from, making it hard to provide accurate recommendations. To the best of our knowledge, very few attention has been put into the problem of missing modalities in multimodal recommendation so far. To this end, our paper comes as a preliminary attempt to formalise and address such an issue. Inspired by the recent advances in graph representation learning, we propose to re-sketch the missing modalities problem as a problem of missing graph node features to apply the state-of-the-art feature propagation algorithm eventually. Technically, we first project the user-item graph into an item-item one based on co-interactions. Then, leveraging the multimodal similarities among co-interacted items, we apply a modified version of the feature propagation technique to impute the missing multimodal features. Adopted as a pre-processing stage for two recent multimodal recommender systems, our simple approach performs better than other shallower solutions on three popular datasets.
Temporal Graph Benchmark for Machine Learning on Temporal Graphs
Jul 03, 2023



We present the Temporal Graph Benchmark (TGB), a collection of challenging and diverse benchmark datasets for realistic, reproducible, and robust evaluation of machine learning models on temporal graphs. TGB datasets are of large scale, spanning years in duration, incorporate both node and edge-level prediction tasks and cover a diverse set of domains including social, trade, transaction, and transportation networks. For both tasks, we design evaluation protocols based on realistic use-cases. We extensively benchmark each dataset and find that the performance of common models can vary drastically across datasets. In addition, on dynamic node property prediction tasks, we show that simple methods often achieve superior performance compared to existing temporal graph models. We believe that these findings open up opportunities for future research on temporal graphs. Finally, TGB provides an automated machine learning pipeline for reproducible and accessible temporal graph research, including data loading, experiment setup and performance evaluation. TGB will be maintained and updated on a regular basis and welcomes community feedback. TGB datasets, data loaders, example codes, evaluation setup, and leaderboards are publicly available at https://tgb.complexdatalab.com/ .