 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep ZakaiJ: Structured Filtering for Jump-Diffusion Time Series Forecasting
May 23, 2026Time series driven by unobserved latent states frequently exhibit abrupt jump discontinuities whose timing and magnitude cannot be predicted from observed history alone. Classical jump-diffusion models offer a principled mathematical framework but assume rigid parametric forms, while recent neural jump models operate on fully observed trajectories without inferring the hidden states that govern the dynamics. We propose \textit{Deep ZakaiJ}, a latent-state model for partially observed jump-diffusion systems that embeds the Zakai nonlinear filtering equation into a neural encoder--decoder architecture. The encoder recursively updates a belief over the latent state via Strang splitting into three interpretable substeps: prior propagation, diffusion innovation, and jump innovation, yielding a differentiable, first-order-accurate approximation of the exact filtering evolution. The decoder is a structured jump-diffusion model explicitly conditioned on the filtered belief, preserving the separation between continuous dynamics and discontinuous shocks. On synthetic, financial, and oceanographic datasets, \textit{Deep ZakaiJ} improves distributional forecasts while remaining competitive in point accuracy, achieving calibrated predictive intervals and recovering interpretable latent structure in synthetic and qualitative case studies.
Neural MJD: Neural Non-Stationary Merton Jump Diffusion for Time Series Prediction
Jun 05, 2025While deep learning methods have achieved strong performance in time series prediction, their black-box nature and inability to explicitly model underlying stochastic processes often limit their generalization to non-stationary data, especially in the presence of abrupt changes. In this work, we introduce Neural MJD, a neural network based non-stationary Merton jump diffusion (MJD) model. Our model explicitly formulates forecasting as a stochastic differential equation (SDE) simulation problem, combining a time-inhomogeneous It\^o diffusion to capture non-stationary stochastic dynamics with a time-inhomogeneous compound Poisson process to model abrupt jumps. To enable tractable learning, we introduce a likelihood truncation mechanism that caps the number of jumps within small time intervals and provide a theoretical error bound for this approximation. Additionally, we propose an Euler-Maruyama with restart solver, which achieves a provably lower error bound in estimating expected states and reduced variance compared to the standard solver. Experiments on both synthetic and real-world datasets demonstrate that Neural MJD consistently outperforms state-of-the-art deep learning and statistical learning methods.
TAMA: A Human-AI Collaborative Thematic Analysis Framework Using Multi-Agent LLMs for Clinical Interviews
Mar 26, 2025Thematic analysis (TA) is a widely used qualitative approach for uncovering latent meanings in unstructured text data. TA provides valuable insights in healthcare but is resource-intensive. Large Language Models (LLMs) have been introduced to perform TA, yet their applications in healthcare remain unexplored. Here, we propose TAMA: A Human-AI Collaborative Thematic Analysis framework using Multi-Agent LLMs for clinical interviews. We leverage the scalability and coherence of multi-agent systems through structured conversations between agents and coordinate the expertise of cardiac experts in TA. Using interview transcripts from parents of children with Anomalous Aortic Origin of a Coronary Artery (AAOCA), a rare congenital heart disease, we demonstrate that TAMA outperforms existing LLM-assisted TA approaches, achieving higher thematic hit rate, coverage, and distinctiveness. TAMA demonstrates strong potential for automated TA in clinical settings by leveraging multi-agent LLM systems with human-in-the-loop integration by enhancing quality while significantly reducing manual workload.
Toward a Flexible Framework for Linear Representation Hypothesis Using Maximum Likelihood Estimation
Feb 22, 2025Linear representation hypothesis posits that high-level concepts are encoded as linear directions in the representation spaces of LLMs. Park et al. (2024) formalize this notion by unifying multiple interpretations of linear representation, such as 1-dimensional subspace representation and interventions, using a causal inner product. However, their framework relies on single-token counterfactual pairs and cannot handle ambiguous contrasting pairs, limiting its applicability to complex or context-dependent concepts. We introduce a new notion of binary concepts as unit vectors in a canonical representation space, and utilize LLMs' (neural) activation differences along with maximum likelihood estimation (MLE) to compute concept directions (i.e., steering vectors). Our method, Sum of Activation-base Normalized Difference (SAND), formalizes the use of activation differences modeled as samples from a von Mises-Fisher (vMF) distribution, providing a principled approach to derive concept directions. We extend the applicability of Park et al. (2024) by eliminating the dependency on unembedding representations and single-token pairs. Through experiments with LLaMA models across diverse concepts and benchmarks, we demonstrate that our lightweight approach offers greater flexibility, superior performance in activation engineering tasks like monitoring and manipulation.
FusionTransNet for Smart Urban Mobility: Spatiotemporal Traffic Forecasting Through Multimodal Network Integration
May 09, 2024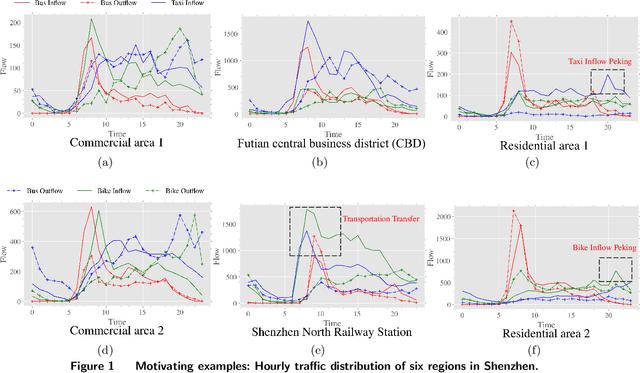
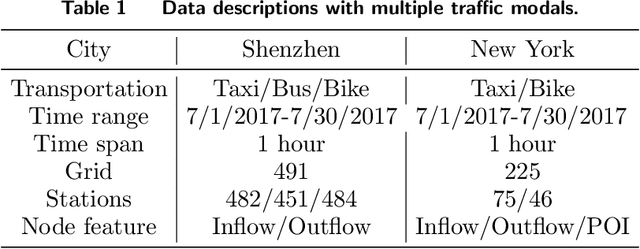

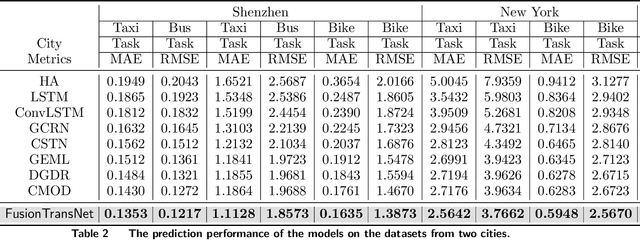
This study develops FusionTransNet, a framework designed for Origin-Destination (OD) flow predictions within smart and multimodal urban transportation systems. Urban transportation complexity arises from the spatiotemporal interactions among various traffic modes. Motivated by analyzing multimodal data from Shenzhen, a framework that can dissect complicated spatiotemporal interactions between these modes, from the microscopic local level to the macroscopic city-wide perspective, is essential. The framework contains three core components: the Intra-modal Learning Module, the Inter-modal Learning Module, and the Prediction Decoder. The Intra-modal Learning Module is designed to analyze spatial dependencies within individual transportation modes, facilitating a granular understanding of single-mode spatiotemporal dynamics. The Inter-modal Learning Module extends this analysis, integrating data across different modes to uncover cross-modal interdependencies, by breaking down the interactions at both local and global scales. Finally, the Prediction Decoder synthesizes insights from the preceding modules to generate accurate OD flow predictions, translating complex multimodal interactions into forecasts. Empirical evaluations conducted in metropolitan contexts, including Shenzhen and New York, demonstrate FusionTransNet's superior predictive accuracy compared to existing state-of-the-art methods. The implication of this study extends beyond urban transportation, as the method for transferring information across different spatiotemporal graphs at both local and global scales can be instrumental in other spatial systems, such as supply chain logistics and epidemics spreading.
Do LLM Agents Exhibit Social Behavior?
Dec 23, 2023The advances of Large Language Models (LLMs) are expanding their utility in both academic research and practical applications. Recent social science research has explored the use of these "black-box" LLM agents for simulating complex social systems and potentially substituting human subjects in experiments. Our study delves into this emerging domain, investigating the extent to which LLMs exhibit key social interaction principles, such as social learning, social preference, and cooperative behavior, in their interactions with humans and other agents. We develop a novel framework for our study, wherein classical laboratory experiments involving human subjects are adapted to use LLM agents. This approach involves step-by-step reasoning that mirrors human cognitive processes and zero-shot learning to assess the innate preferences of LLMs. Our analysis of LLM agents' behavior includes both the primary effects and an in-depth examination of the underlying mechanisms. Focusing on GPT-4, the state-of-the-art LLM, our analyses suggest that LLM agents appear to exhibit a range of human-like social behaviors such as distributional and reciprocity preferences, responsiveness to group identity cues, engagement in indirect reciprocity, and social learning capabilities. However, our analysis also reveals notable differences: LLMs demonstrate a pronounced fairness preference, weaker positive reciprocity, and a more calculating approach in social learning compared to humans. These insights indicate that while LLMs hold great promise for applications in social science research, such as in laboratory experiments and agent-based modeling, the subtle behavioral differences between LLM agents and humans warrant further investigation. Careful examination and development of protocols in evaluating the social behaviors of LLMs are necessary before directly applying these models to emulate human behavior.
Learning to Infer Structures of Network Games
Jun 16, 2022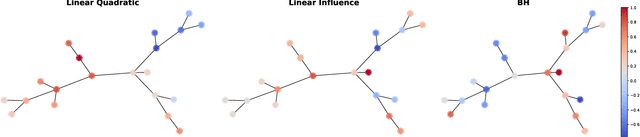

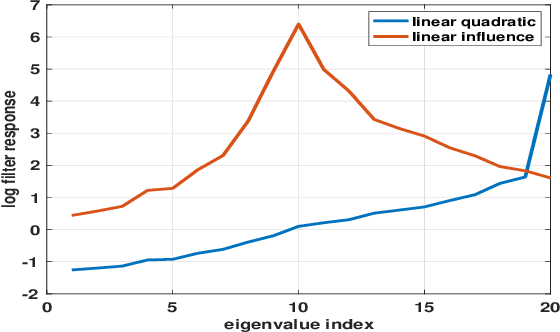
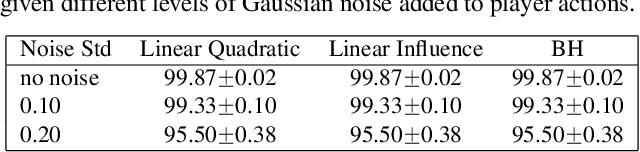
Strategic interactions between a group of individuals or organisations can be modelled as games played on networks, where a player's payoff depends not only on their actions but also on those of their neighbours. Inferring the network structure from observed game outcomes (equilibrium actions) is an important problem with numerous potential applications in economics and social sciences. Existing methods mostly require the knowledge of the utility function associated with the game, which is often unrealistic to obtain in real-world scenarios. We adopt a transformer-like architecture which correctly accounts for the symmetries of the problem and learns a mapping from the equilibrium actions to the network structure of the game without explicit knowledge of the utility function. We test our method on three different types of network games using both synthetic and real-world data, and demonstrate its effectiveness in network structure inference and superior performance over existing methods.
Interpretable Stochastic Block Influence Model: measuring social influence among homophilous communities
Jun 01, 2020
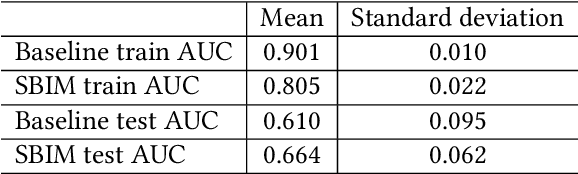
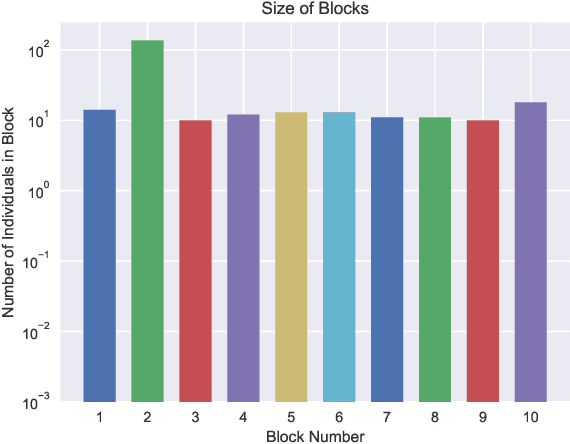

Decision-making on networks can be explained by both homophily and social influence. While homophily drives the formation of communities with similar characteristics, social influence occurs both within and between communities. Social influence can be reasoned through role theory, which indicates that the influences among individuals depend on their roles and the behavior of interest. To operationalize these social science theories, we empirically identify the homophilous communities and use the community structures to capture the "roles", which affect the particular decision-making processes. We propose a generative model named Stochastic Block Influence Model and jointly analyze both the network formation and the behavioral influence within and between different empirically-identified communities. To evaluate the performance and demonstrate the interpretability of our method, we study the adoption decisions of microfinance in an Indian village. We show that although individuals tend to form links within communities, there are strong positive and negative social influences between communities, supporting the weak tie theory. Moreover, we find that communities with shared characteristics are associated with positive influence. In contrast, the communities with a lack of overlap are associated with negative influence. Our framework facilitates the quantification of the influences underlying decision communities and is thus a useful tool for driving information diffusion, viral marketing, and technology adoptions.
Learning Quadratic Games on Networks
Nov 21, 2018
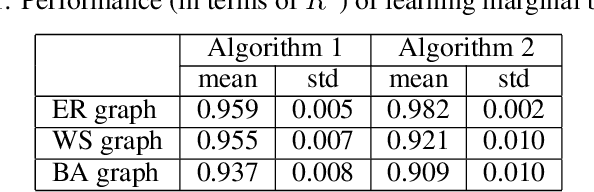
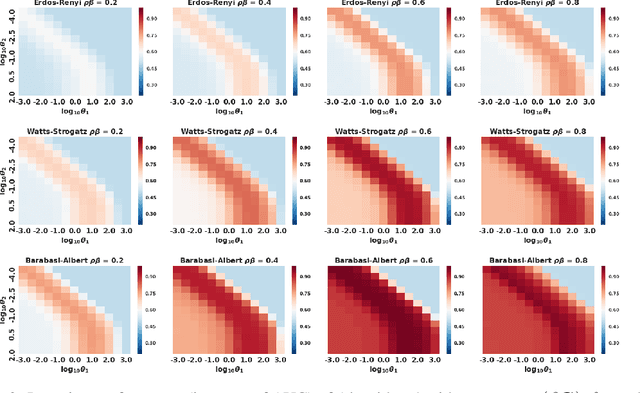
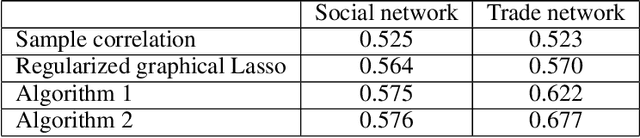
Individuals, or organizations, cooperate with or compete against one another in a wide range of practical situations. Such strategic interactions may be modeled as games played on networks, where an individual's payoff depends not only on her action but also that of her neighbors. The current literature has predominantly focused on analyzing the characteristics of network games in the scenario where the structure of the network, which is represented by a graph, is known beforehand. It is often the case, however, that the actions of the players are readily observable while the underlying interaction network remains hidden. In this paper, we propose two novel frameworks for learning, from the observations on individual actions, network games with linear-quadratic payoffs, and in particular the structure of the interaction network. Our frameworks are based on the Nash equilibrium of such games and involve solving a joint optimization problem for the graph structure and the individual marginal benefits. We test the proposed frameworks in synthetic settings and further study several factors that affect their learning performance. Moreover, with experiments on three real-world examples, we show that our methods can effectively and more accurately learn the games than the baselines. The proposed approach is among the first of its kind for learning quadratic games, and have both theoretical and practical implications for understanding strategic interactions in a network environment.
Improved Learning in Evolution Strategies via Sparser Inter-Agent Network Topologies
Nov 30, 2017

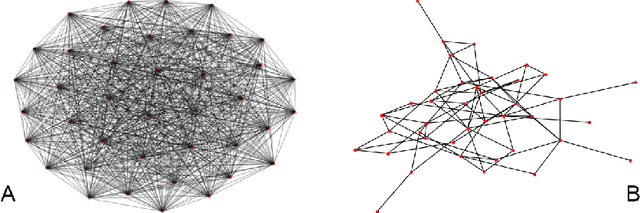
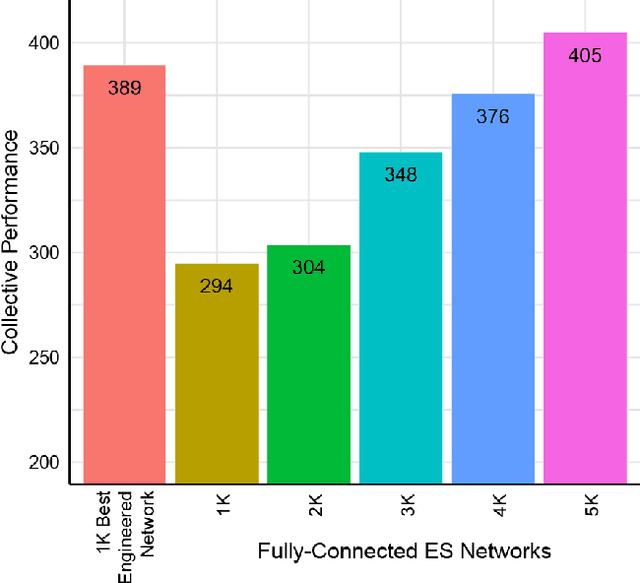
We draw upon a previously largely untapped literature on human collective intelligence as a source of inspiration for improving deep learning. Implicit in many algorithms that attempt to solve Deep Reinforcement Learning (DRL) tasks is the network of processors along which parameter values are shared. So far, existing approaches have implicitly utilized fully-connected networks, in which all processors are connected. However, the scientific literature on human collective intelligence suggests that complete networks may not always be the most effective information network structures for distributed search through complex spaces. Here we show that alternative topologies can improve deep neural network training: we find that sparser networks learn higher rewards faster, leading to learning improvements at lower communication costs.