 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimize Wider, Not Deeper: Consensus Aggregation for Policy Optimization
Mar 13, 2026Proximal policy optimization (PPO) approximates the trust region update using multiple epochs of clipped SGD. Each epoch may drift further from the natural gradient direction, creating path-dependent noise. To understand this drift, we can use Fisher information geometry to decompose policy updates into signal (the natural gradient projection) and waste (the Fisher-orthogonal residual that consumes trust region budget without first-order surrogate improvement). Empirically, signal saturates but waste grows with additional epochs, creating an optimization-depth dilemma. We propose Consensus Aggregation for Policy Optimization (CAPO), which redirects compute from depth to width: $K$ PPO replicates are optimized on the same batch, differing only in minibatch shuffling order, and then aggregated into a consensus. We study aggregation in two spaces: Euclidean parameter space, and the natural parameter space of the policy distribution via the logarithmic opinion pool. In natural parameter space, the consensus provably achieves higher KL-penalized surrogate and tighter trust region compliance than the mean expert; parameter averaging inherits these guarantees approximately. On continuous control tasks, CAPO outperforms PPO and compute-matched deeper baselines under fixed sample budgets by up to 8.6x. CAPO demonstrates that policy optimization can be improved by optimizing wider, rather than deeper, without additional environment interactions.
TAMA: A Human-AI Collaborative Thematic Analysis Framework Using Multi-Agent LLMs for Clinical Interviews
Mar 26, 2025Thematic analysis (TA) is a widely used qualitative approach for uncovering latent meanings in unstructured text data. TA provides valuable insights in healthcare but is resource-intensive. Large Language Models (LLMs) have been introduced to perform TA, yet their applications in healthcare remain unexplored. Here, we propose TAMA: A Human-AI Collaborative Thematic Analysis framework using Multi-Agent LLMs for clinical interviews. We leverage the scalability and coherence of multi-agent systems through structured conversations between agents and coordinate the expertise of cardiac experts in TA. Using interview transcripts from parents of children with Anomalous Aortic Origin of a Coronary Artery (AAOCA), a rare congenital heart disease, we demonstrate that TAMA outperforms existing LLM-assisted TA approaches, achieving higher thematic hit rate, coverage, and distinctiveness. TAMA demonstrates strong potential for automated TA in clinical settings by leveraging multi-agent LLM systems with human-in-the-loop integration by enhancing quality while significantly reducing manual workload.
HyperQuery: Beyond Binary Link Prediction
Jan 13, 2025



Groups with complex set intersection relations are a natural way to model a wide array of data, from the formation of social groups to the complex protein interactions which form the basis of biological life. One approach to representing such higher order relationships is as a hypergraph. However, efforts to apply machine learning techniques to hypergraph structured datasets have been limited thus far. In this paper, we address the problem of link prediction in knowledge hypergraphs as well as simple hypergraphs and develop a novel, simple, and effective optimization architecture that addresses both tasks. Additionally, we introduce a novel feature extraction technique using node level clustering and we show how integrating data from node-level labels can improve system performance. Our self-supervised approach achieves significant improvement over state of the art baselines on several hyperedge prediction and knowledge hypergraph completion benchmarks.
Sonic: A Sampling-based Online Controller for Streaming Applications
Aug 15, 2021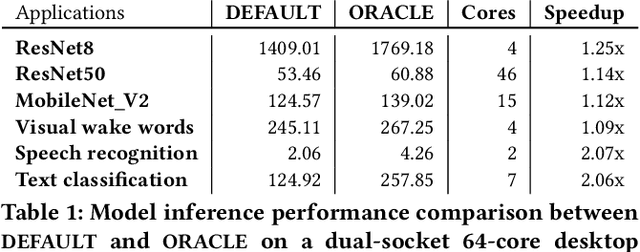
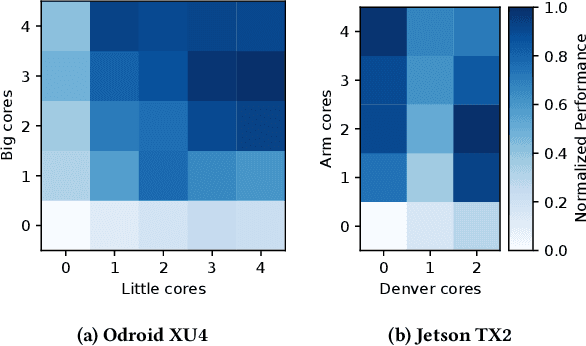

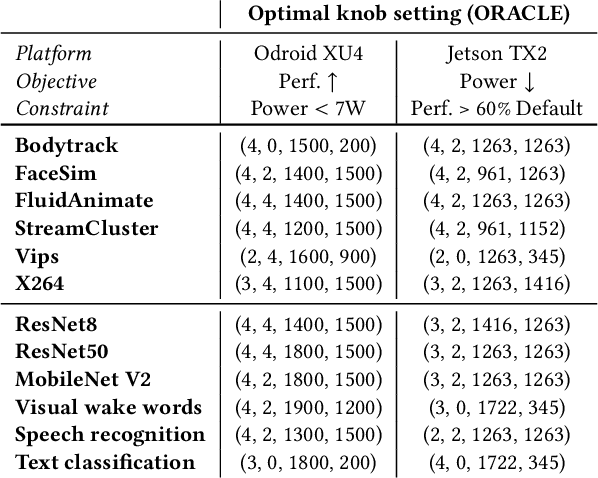
Many applications in important problem domains such as machine learning and computer vision are streaming applications that take a sequence of inputs over time. It is challenging to find knob settings that optimize the run-time performance of such applications because the optimal knob settings are usually functions of inputs, computing platforms, time as well as user's requirements, which can be very diverse. Most prior works address this problem by offline profiling followed by training models for control. However, profiling-based approaches incur large overhead before execution; it is also difficult to redeploy them in other run-time configurations. In this paper, we propose Sonic, a sampling-based online controller for long-running streaming applications that does not require profiling ahead of time. Within each phase of a streaming application's execution, Sonic utilizes the beginning portion to sample the knob space strategically and aims to pick the optimal knob setting for the rest of the phase, given a user-specified constrained optimization problem. A hybrid approach of machine learning regressions and Bayesian optimization are used for better overall sampling choices. Sonic is implemented independent of application, device, input, performance objective and constraints. We evaluate Sonic on traditional parallel benchmarks as well as on deep learning inference benchmarks across multiple platforms. Our experiments show that when using Sonic to control knob settings, application run-time performance is only 5.3% less than if optimal knob settings were used, demonstrating that Sonic is able to find near-optimal knob settings under diverse run-time configurations without prior knowledge quickly.
Optimizing Graph Transformer Networks with Graph-based Techniques
Jun 16, 2021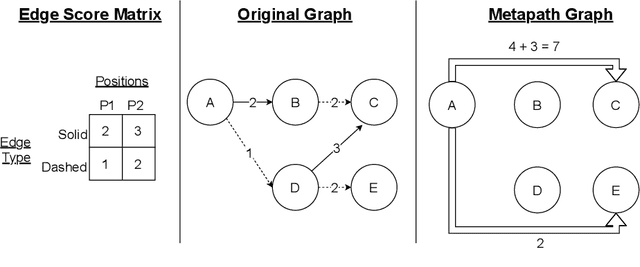
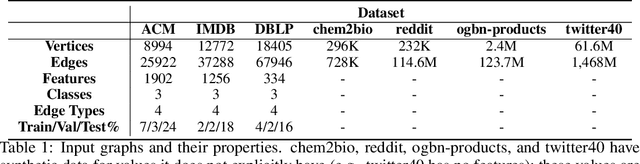
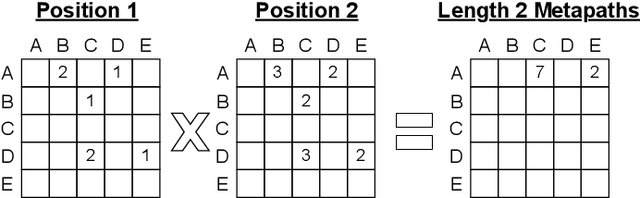
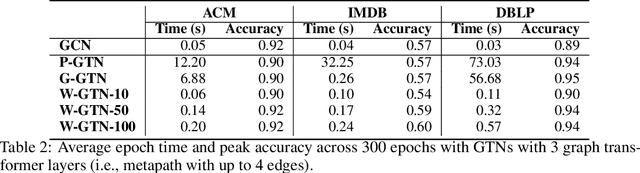
Graph transformer networks (GTN) are a variant of graph convolutional networks (GCN) that are targeted to heterogeneous graphs in which nodes and edges have associated type information that can be exploited to improve inference accuracy. GTNs learn important metapaths in the graph, create weighted edges for these metapaths, and use the resulting graph in a GCN. Currently, the only available implementation of GTNs uses dense matrix multiplication to find metapaths. Unfortunately, the space overhead of this approach can be large, so in practice it is used only for small graphs. In addition, the matrix-based implementation is not fine-grained enough to use random-walk based methods to optimize metapath finding. In this paper, we present a graph-based formulation and implementation of the GTN metapath finding problem. This graph-based formulation has two advantages over the matrix-based approach. First, it is more space efficient than the original GTN implementation and more compute-efficient for metapath sizes of practical interest. Second, it permits us to implement a sampling method that reduces the number of metapaths that must be enumerated, allowing the implementation to be used for larger graphs and larger metapath sizes. Experimental results show that our implementation is $6.5\times$ faster than the original GTN implementation on average for a metapath length of 4, and our sampling implementation is $155\times$ faster on average than this implementation without compromising on the accuracy of the GTN.
NetVec: A Scalable Hypergraph Embedding System
Mar 09, 2021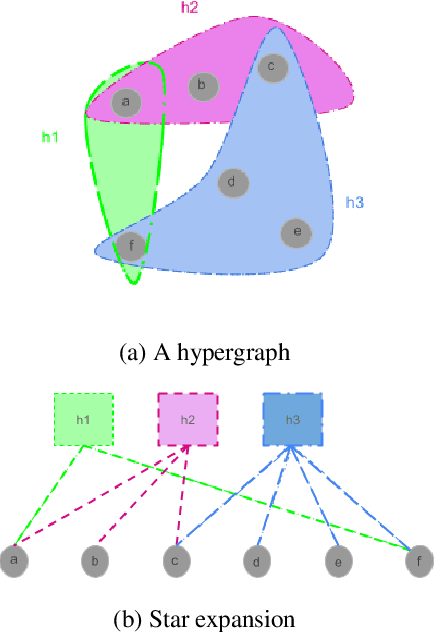
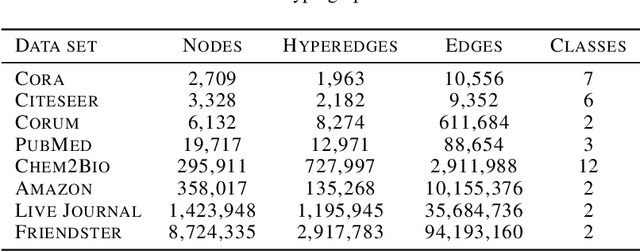

Many problems such as vertex classification andlink prediction in network data can be solvedusing graph embeddings, and a number of algo-rithms are known for constructing such embed-dings. However, it is difficult to use graphs tocapture non-binary relations such as communitiesof vertices. These kinds of complex relations areexpressed more naturally as hypergraphs. Whilehypergraphs are a generalization of graphs, state-of-the-art graph embedding techniques are notadequate for solving prediction and classificationtasks on large hypergraphs accurately in reason-able time. In this paper, we introduce NetVec,a novel multi-level framework for scalable un-supervised hypergraph embedding, that can becoupled with any graph embedding algorithm toproduce embeddings of hypergraphs with millionsof nodes and hyperedges in a few minutes.
SLAMBooster: An Application-aware Controller for Approximation in SLAM
Nov 05, 2018
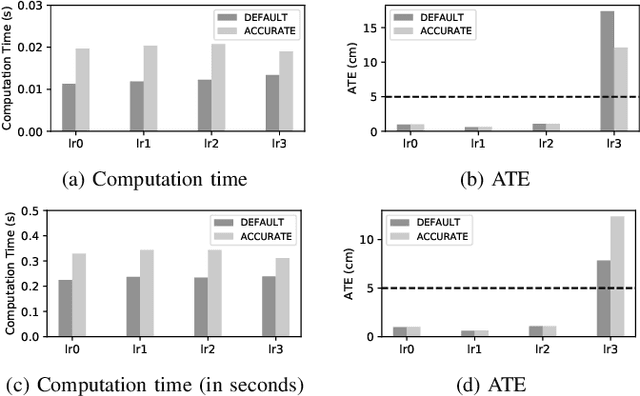
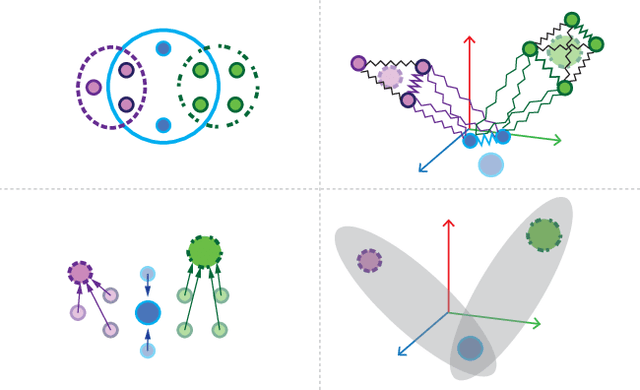
Simultaneous Localization and Mapping (SLAM) is the problem of constructing a map of an agent's environment while localizing or tracking the mobile agent's position and orientation within the map. Algorithms for SLAM have high computational requirements, which has hindered their use on embedded devices. Approximation can be used to reduce the time and energy requirements of SLAM implementations as long as the approximations do not prevent the agent from navigating correctly through the environment. Previous studies of approximation in SLAM have assumed that the entire trajectory of the agent is known before the agent starts to move, and they have focused on offline controllers that use features of the trajectory to set approximation knobs at the start of the trajectory. In practice, the trajectory is not usually known ahead of time, and allowing knob settings to change dynamically opens up more opportunities for reducing computation time and energy. We describe SLAMBooster, an application-aware online control system for SLAM that adaptively controls approximation knobs during the motion of the agent. SLAMBooster is based on a control technique called hierarchical proportional control but our experiments showed this application-agnostic control led to an unacceptable reduction in the quality of localization. To address this problem, SLAMBooster exploits domain knowledge: it uses features extracted from input frames and from the estimated motion of the agent in its algorithm for controlling approximation. We implemented SLAMBooster in the open-source SLAMBench framework. Our experiments show that SLAMBooster reduces the computation time and energy consumption by around half on the average on an embedded platform, while maintaining the accuracy of the localization within reasonable bounds. These improvements make it feasible to deploy SLAM on a wider range of devices.